Web crawlers face a growing challenge: websites use advanced tools to detect bots by analyzing human-like behavior. To avoid detection, crawlers now mimic human actions – like natural mouse movements, typing speeds, and pauses. This approach, called behavioral mimicry, helps automated systems navigate websites undetected.
Key Points:
- What is it? Behavioral mimicry programs bots to act like humans by simulating natural interaction patterns (e.g., curved mouse paths, fluctuating delays).
- Why is it needed? Modern anti-bot systems analyze behaviors like scrolling, mouse actions, and timing to spot automation. Bots now make up 40% of web traffic, with 27.7% classified as harmful.
- How does it work? Techniques include:
- Creating random, curved mouse movements.
- Introducing pauses and variability in actions.
- Using headless browsers with modified settings to avoid detection.
- Applications: Behavioral mimicry is used for ethical purposes like monitoring piracy websites for stolen content while respecting legal and ethical boundaries.
This method ensures bots can pass undetected while adhering to laws and ethical guidelines. Below, you’ll find detailed techniques and how they’re applied effectively.
WHY 2025 – Stealth Web Scraping Techniques for OSINT
Methods for Simulating Human Behavior
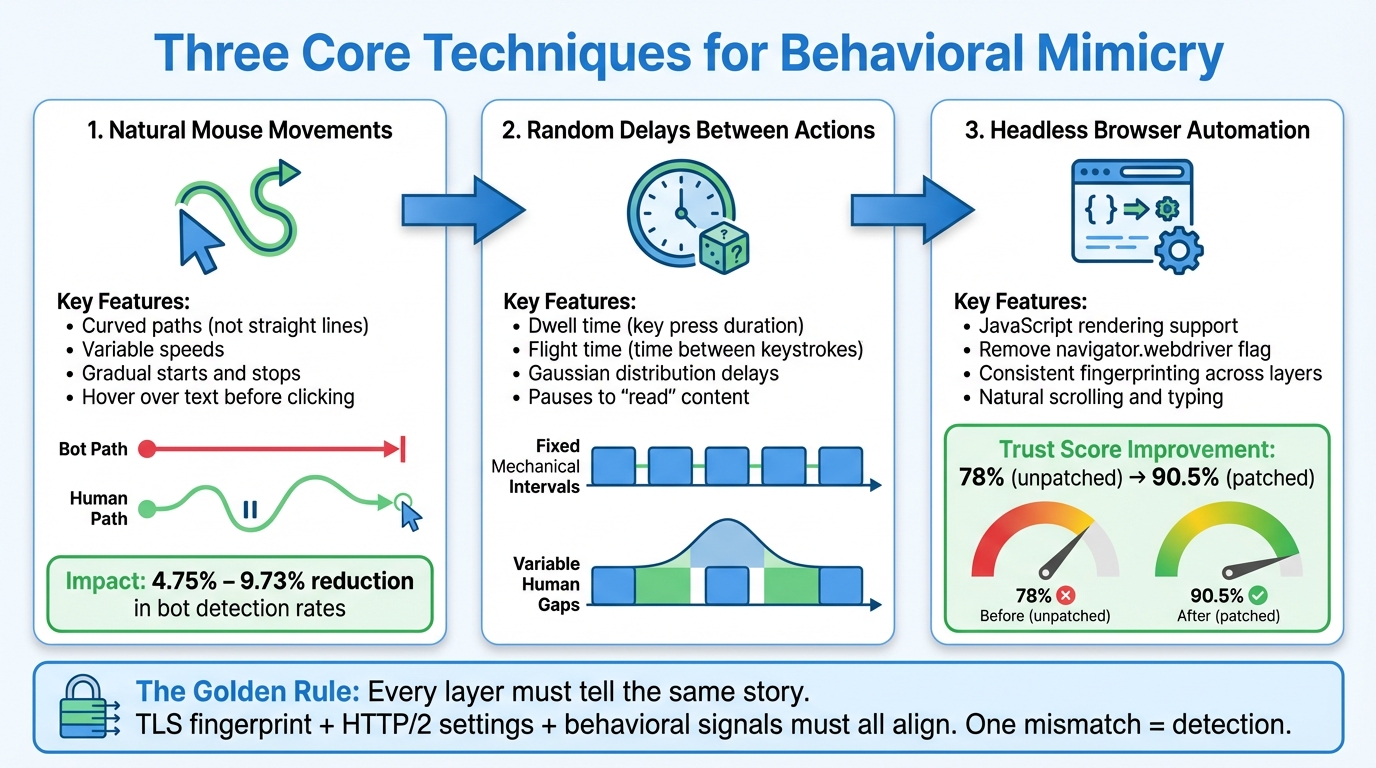
How Behavioral Mimicry Works: Three Key Techniques for Human-Like Web Crawling
With modern anti-bot systems becoming increasingly sophisticated, simulating human behavior has become a key strategy for bypassing detection. This involves replicating realistic mouse movements, introducing natural delays, and employing advanced browser automation. These techniques work together to create the illusion of authentic user interactions.
Simulating Natural Mouse Movements
Humans don’t move their cursors in straight, predictable lines. Instead, their mouse movements are characterized by curves, small corrections, and varying speeds. Tools like DMTG (Diffusion-based Mouse Trajectory Generator) use diffusion models to replicate these patterns, blending purposeful cursor movement with random variations. This approach has been shown to reduce bot detection rates by 4.75% to 9.73% during white-box tests[1].
"DMTG can effectively mimic the physical properties of human operations, including slow initiation and differences in applied force for different directions." – Jiahua Liu et al., University of Michigan[1]
To simulate human-like behavior, consider these details:
- Gradual starts and stops in movement.
- Adjusting speed based on the cursor’s distance from the target.
- Using the mouse as a reading tool – hovering over text or interactive elements before clicking[1][2].
Additionally, mimic the way humans interact with elements. For example, vary the time between mousedown and mouseup events, as fixed intervals can be a red flag for automation. Avoid straight-line movements; instead, introduce curved, variable paths for a more natural look.
Adding Random Delays Between Actions
Humans don’t operate with mechanical precision – they take time to process what they see, which naturally introduces delays. Timing variations can be broken down into patterns like dwell time (how long a key is pressed) and flight time (the time between keystrokes). These patterns often depend on typing speed and familiarity with the task[2].
Rather than relying on static sleep() commands, use random ranges or Gaussian distributions to simulate delays. For instance:
- Vary the timing between events like
mousemove,hover,mousedown,mouseup, andclick. - Introduce pauses that reflect real user behavior, such as stopping to read page content before taking the next action.
By incorporating these random delays, the simulation becomes harder to distinguish from genuine human activity.
Using Headless Browsers for Automation
Headless browsers are powerful tools for simulating user interactions. They support JavaScript rendering and allow for complex scripts that mimic real browsing behaviors, such as scrolling, typing, and mouse movements[9][4]. These browsers interact with protocols like the Chrome DevTools Protocol (CDP) to execute these actions.
However, standard headless browsers can be easily flagged. One common detection method involves the navigator.webdriver flag, which signals automation. By applying undetected patches to remove this flag, Trust Scores can significantly improve. For example, an unpatched version of Playwright might yield a Trust Score of 78%, while a patched version can reach approximately 90.5%, making detection far less likely[8].
"The Golden Rule: Every layer must tell the same story. If your TLS fingerprint says ‘Chrome 120’, your HTTP/2 settings must match Chrome 120… One mismatch = detection." – Pydoll[6]
To further reduce detection risks:
- Ensure all layers – network, browser, and behavioral – are consistent.
- Avoid linear interactions, such as fixed wait times or predictable paths.
- Simulate natural pauses, like a user taking time to process page content before navigating further.
Advanced detection systems are now capable of identifying the use of CDP itself, so introducing variability at every step is critical. By aligning all interaction layers and mimicking natural behaviors, the simulation becomes more convincing and harder to detect[2].
Using Behavioral Mimicry for Digital Content Protection
Behavioral mimicry is often linked to bypassing security systems, but it also plays a legitimate role in safeguarding intellectual property. For content creators, monitoring the web for stolen digital assets can be a daunting task, especially when piracy websites deploy advanced anti-bot systems to block automated crawlers. So, how do you uncover stolen content when the very platforms hosting it are designed to keep you out?
Finding Unauthorized Content Through Web Crawling
Piracy websites protect themselves by using Web Application Firewalls (WAFs) like Cloudflare, Akamai, and DataDome, which are specifically designed to block automated scrapers [3]. This is where behavioral mimicry comes into play. By making web crawlers behave like real users, these tools can slip past such defenses. Instead of sending predictable, robotic requests, crawlers simulate human-like behaviors – smooth mouse movements, natural scrolling with varying momentum, and irregular timing patterns – to avoid detection.
For this approach to work, consistency across multiple layers is essential. A crawler must align its network fingerprint (e.g., TLS handshake, HTTP/2 settings), browser characteristics (like User-Agent strings and canvas rendering), and behavioral signals (such as mouse movement entropy and scrolling patterns). Even a small inconsistency – like pairing a Chrome User-Agent with a Firefox TLS fingerprint – can trigger immediate blocking [6]. This meticulous simulation allows advanced systems to bypass even the most stringent anti-bot protections.
Bypassing Protection on Piracy Websites
ScoreDetect’s web scraping technology boasts a 95% success rate in bypassing anti-bot measures on protected websites [3]. This impressive performance stems from the highly sophisticated mimicry techniques described earlier. By using entropy-controlled models, the system injects randomness into every interaction, ensuring each session appears unique, with distinct trajectories and timing patterns.
"Behavioral analysis can detect automation even when network and browser fingerprints are correctly spoofed." – Pydoll [6]
Such precision is crucial because roughly 27.7% of global web traffic comes from "bad bots" that engage in unauthorized scraping and data theft [3]. In response, anti-bot vendors are stepping up their game, combining technical fingerprints with behavioral biometrics to create comprehensive trust scores for web visitors.
Combining Crawling with Copyright Protection Tools
Behavioral mimicry doesn’t just help detect stolen content – it’s also a powerful tool for enforcing copyright. ScoreDetect takes this a step further by integrating advanced copyright protection measures. These include embedding invisible watermarks in digital assets and linking content to blockchain-timestamped originals. The blockchain records a checksum of the content rather than the asset itself, offering verifiable proof of ownership for legal purposes.
Once unauthorized use is identified, the system automatically issues delisting notices, achieving a 96% takedown rate [3]. This comprehensive approach – spanning detection, evidence gathering, and enforcement – highlights how behavioral mimicry plays a pivotal role in combating digital piracy. While the crawling technology uncovers stolen content, the accompanying tools provide the proof and mechanisms needed to take effective legal action.
sbb-itb-738ac1e
Ethics and Responsible Use
Behavioral mimicry can serve both noble and harmful purposes – it all depends on how it’s applied. On one hand, it can safeguard intellectual property; on the other, it can enable malicious activities like scraping or fraud. As this technique evolves to outsmart advanced anti-bot defenses, drawing clear ethical lines becomes non-negotiable. For example, while bad bots are notorious for scalping high-demand items (like PlayStation 5 consoles or limited-edition sneakers), stealing personal data, or launching DDoS attacks [3], ethical applications focus on protecting intellectual property and monitoring copyright violations without causing harm.
When Behavioral Mimicry is Justified
Using behavioral mimicry to protect intellectual property rights is a responsible and justified practice. Content creators often face challenges when piracy websites deploy the same anti-bot defenses used by legitimate platforms. Tools like ScoreDetect leverage behavioral mimicry to bypass these barriers with a 95% success rate – not to steal content, but to locate stolen material. This approach parallels how search engine crawlers such as Googlebot operate: they mimic browser behavior to index publicly accessible content for constructive purposes.
The key lies in targeting data that’s already visible to any human visitor. Ethical crawling respects this boundary. As CapSolver explains:
"We advocate for the responsible aggregation of publicly accessible data to enrich human existence, while vehemently denouncing the unauthorized harvesting of sensitive data without proper consent" [5].
Copyright monitoring aligns with this principle by scanning public-facing piracy sites for unauthorized copies of protected works.
Practices to Avoid
No matter how advanced the technology, certain actions in web crawling cross ethical and legal boundaries and must be avoided. For instance, bypassing login walls or paywalls to access restricted content is considered unauthorized access under laws like the Computer Fraud and Abuse Act (CFAA). Similarly, scraping personal data – such as names, emails, phone numbers, health records, or financial information – without explicit consent violates regulations like GDPR and CCPA [12][13].
Additionally, while violating a website’s Terms of Service may not always result in criminal charges, it can be used as evidence of unauthorized access in legal disputes [10][13]. Deceptive practices, such as pretending your crawler is Googlebot, are also unethical and could potentially be illegal. As Alejandro Loyola from Browserless succinctly puts it:
"Technical ability alone doesn’t mean legal permission" [10].
| Ethical Use | Unethical Use |
|---|---|
| Publicly available HTML, price data, SEO metadata [10] | Personal data (PII), health records, financial data [12][13] |
Respects robots.txt and rate limits [12] |
Bypasses logins, paywalls, or security controls [10][12] |
| Transparent User-Agent with contact info [12] | Spoofing legitimate services like Googlebot [10] |
Following Legal Requirements
Legal compliance is the backbone of ethical web crawling. Always respect robots.txt files to understand which parts of a website are off-limits [10][12]. Implement rate limits to ensure your crawler doesn’t overwhelm servers – for smaller sites, one request every 3–5 seconds is reasonable, while larger platforms can typically handle 1–2 requests per second [12]. Using exponential backoff can also help avoid overloading struggling servers [12].
To further ensure compliance, configure your crawlers to avoid honeypots, such as hidden links or fields styled with display:none, which are designed to trap bots [7][11]. Accessing these elements signals unauthorized automation. Additionally, remove or mask any personally identifiable information before storing data to meet GDPR and CCPA standards [13][14]. Lastly, use an honest User-Agent string that includes contact information, allowing site administrators to reach out if your crawler causes issues [12][13]. As Vinod Chugani from DataCamp wisely notes:
"Ethical scraping is as much about restraint as it is about reach" [12].
Summary
Behavioral mimicry allows crawlers to slip past advanced anti-bot systems by imitating how humans interact online. This includes techniques like creating mouse movements with controlled randomness [1], varying typing patterns [2], and replicating natural scrolling behaviors. As Incolumitas puts it:
"Humans behave like a chaotic systems. Humans move their mouse, keyboard, touch screen and scrolling wheel in an organic fashion." [2]
Consistency across multiple layers is also essential. From TLS fingerprints and HTTP/2 settings to User-Agent strings and behavioral signals, everything needs to align. Any inconsistency can raise red flags and lead to detection [6]. By combining this detailed mimicry with tools like residential proxies and randomized timing, crawlers can access public content without tripping security alarms.
These techniques also play a key role in protecting digital content. For instance, ScoreDetect uses behavioral mimicry to bypass anti-bot defenses on piracy websites. This allows it to uncover unauthorized copies of protected works that might otherwise go unnoticed. This capability benefits creators across industries – whether in media, academia, or software development – by helping them identify and address copyright violations effectively.
FAQs
What is behavioral mimicry, and how does it help web crawlers avoid detection?
Behavioral mimicry is a method used by web crawlers to imitate human behaviors, making their actions seem more natural and less likely to trigger detection as automated activity. By mimicking realistic actions – like mouse movements, varying speeds, and natural timing patterns – crawlers can blend in with typical human interaction data.
These simulated behaviors are designed to align with the biometric patterns that bot detection systems are programmed to recognize. This helps the crawler slip past security measures aimed at identifying automated activity, enabling more efficient and discreet data collection, even on platforms with sophisticated anti-bot defenses.
What ethical concerns should you consider when using behavioral mimicry techniques?
Behavioral mimicry – like imitating human-like mouse movements, scrolling, or click patterns – can be a clever way to get around bot detection systems. While there are legitimate applications for this, such as testing your website’s security or gathering publicly accessible data, it also comes with ethical and legal challenges.
For starters, bypassing anti-bot measures often breaches website terms of service and can be considered unauthorized access, putting you at legal risk. Beyond that, it erodes trust by sidestepping consent-based interactions. This practice can also lead to unfair outcomes, such as bots snapping up limited-edition products or scraping sensitive information, which raises privacy concerns.
To stay on the right side of ethics, always secure explicit permission – whether you’re working with your own website or publicly licensed datasets. Stick to rate limits, respect robots.txt directives, and be upfront about your crawler’s identity. If you’re looking to protect your content from unethical mimicry, tools like ScoreDetect offer advanced detection and watermarking solutions to safeguard your digital assets.
What is behavioral mimicry, and how does it help protect digital content?
Behavioral mimicry is all about replicating human-like actions – things like mouse movements, clicking patterns, and scrolling habits – to make automated systems blend in seamlessly with real users. By imitating these natural behaviors, bots can slip past detection systems that are built to block non-human activity.
When it comes to protecting digital content, behavioral mimicry plays a dual role. First, it helps spot suspicious activity, such as bots trying to scrape protected data, by flagging interactions that don’t look natural. Second, it allows for the identification of pirated material online. Tools that mimic human behavior can bypass anti-bot defenses, making it easier to locate infringing content without raising red flags.
Platforms like ScoreDetect use these methods to combat data theft, uncover unauthorized use of digital assets, and streamline takedown efforts – all while staying under the radar of detection systems.

