AI tools for detecting text copyright violations focus on identifying patterns in how content is created, rather than just where it comes from. These systems are particularly effective at spotting paraphrased or AI-generated material that traditional plagiarism checkers miss. Here’s a quick summary of how they work:
- Fingerprinting and Hashing: These methods identify exact or near-exact matches by creating unique digital signatures for text. However, they struggle with heavily edited content.
- Semantic Embeddings: By converting text into numerical vectors, this technique detects semantic similarities, making it useful for identifying paraphrased or reworded content.
- NLP and Machine Learning: These analyze writing style, vocabulary, and context to spot patterns in altered or AI-generated content.
- Real-Time Monitoring: AI systems scan the web for potential violations, flagging suspicious content and providing detailed reports for review.
Combining these methods offers a balanced approach to spotting and addressing potential copyright issues. Tools like ScoreDetect integrate features like blockchain-based timestamps for ownership proof and automated alerts, making content protection more efficient and scalable.
How Are Copyright Violations Detected On The Internet?
sbb-itb-738ac1e
Core AI Detection Methods
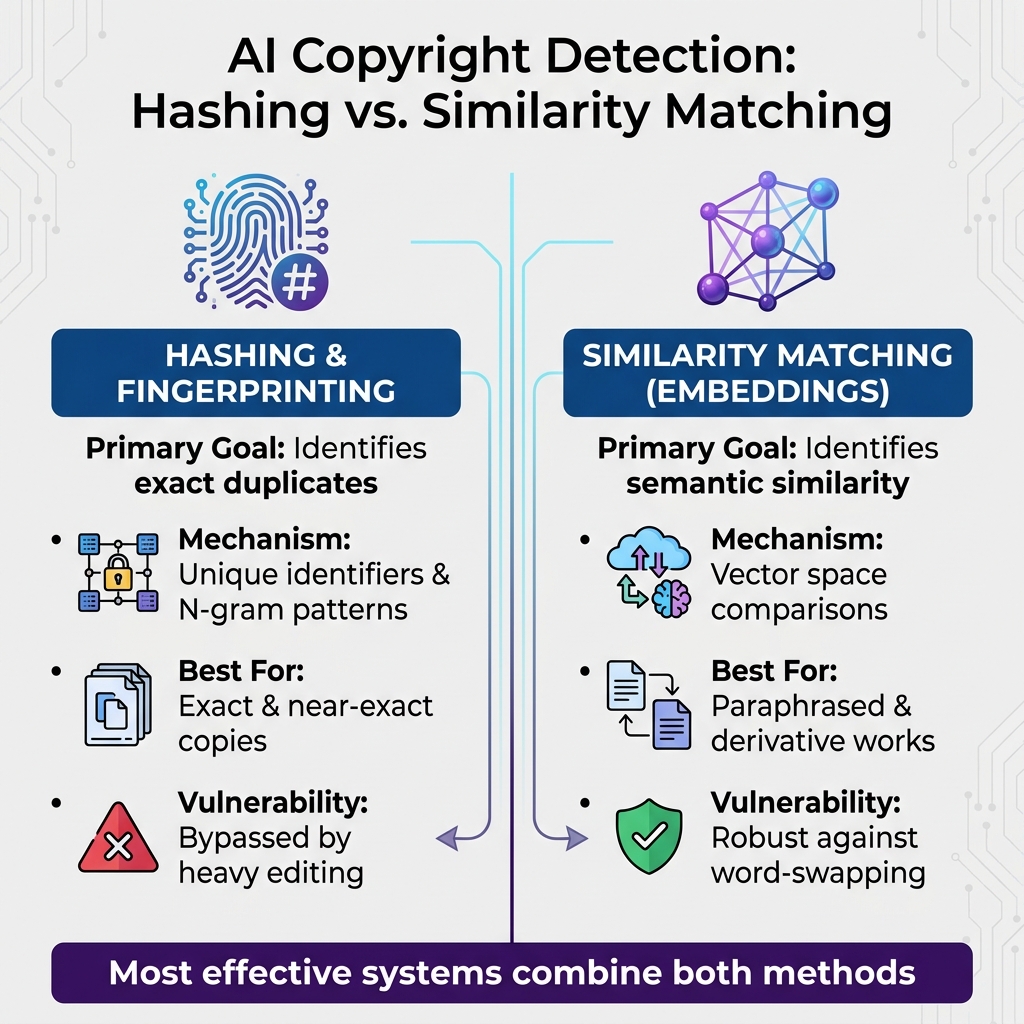
AI Copyright Detection Methods: Hashing vs Embeddings Comparison
AI employs two main methods for detecting content: hashing/fingerprinting for identifying exact matches and embeddings for finding semantic similarities.
Text Fingerprinting and Hashing
Hashing creates unique identifiers for text content. Even a minor change to the text alters its hash, making it useful for spotting exact or near-exact copies [5].
Fingerprinting, on the other hand, analyzes textual characteristics like N-grams and token patterns [4] [6]. This technique breaks text into smaller components (tokens), transforms them into unique digital signatures, and compares them against a database of original content.
In January 2026, the Coalition for Content Provenance and Authenticity (C2PA) introduced the 2.3 specification, which included Section A.7. Authored by Encypher, this section established standards for embedding cryptographic provenance manifests into unstructured text – like articles and social media posts. This allows publishers to verify content origins and detect unauthorized changes using cryptographic signatures and content hashes [6].
"C2PA is cryptographic: verification succeeds or fails with certainty. SynthID is a statistical watermarking system… a probabilistic approach." – Encypher [6]
However, hashing has a key limitation: it’s deterministic. Even small edits, like swapping synonyms or rephrasing a sentence, create a completely different hash. This is where similarity matching with embeddings becomes essential for detecting altered content.
Similarity Matching with Embeddings
Embeddings address the challenges of detecting modified content by focusing on semantic similarity rather than exact matches. Embeddings convert text into numerical vectors that capture the meaning and relationships between words [1]. Instead of matching exact character strings, this method represents words, sentences, and even paragraphs as points in a high-dimensional space. Texts with similar meanings cluster closely together in this space.
This technique is particularly effective for identifying paraphrased or reworded content. By clustering similar meanings, embeddings generate a probability score that reflects how closely two pieces of text are related [1].
While embedding-based comparisons require more computational power, they are indispensable for catching advanced forms of content manipulation, such as AI-generated rewrites or heavily edited material.
Here’s a comparison of the two methods:
| Feature | Hashing & Fingerprinting | Similarity Matching (Embeddings) |
|---|---|---|
| Primary Goal | Identifies exact duplicates | Identifies semantic similarity |
| Mechanism | Unique identifiers and N-gram patterns | Vector space comparisons |
| Best For | Exact and near-exact copies | Paraphrased and derivative works |
| Vulnerability | Bypassed by heavy editing | Robust against word-swapping |
"Embeddings turn words, sentences, and paragraphs into numerical representations that capture meaning and relationships between terms." – Veronika Kuriata [1]
The most effective detection systems combine both methods. Hashing is used to quickly filter out exact duplicates, while embeddings are applied to detect paraphrased or derivative content. This two-step approach strikes a balance between speed and accuracy, making it highly effective for identifying copyright violations.
NLP and Semantic Analysis for Detection
Hashing and embeddings can catch exact and near matches, but NLP (Natural Language Processing) and semantic analysis take things a step further by understanding the meaning behind the content. This deeper comprehension is crucial for identifying more complex cases, like when someone paraphrases or rewords original material.
Semantic Analysis for Paraphrased Content
NLP dives into the structure and style of writing – looking at elements like sentence construction, word choices, and overall flow. By focusing on these key features, it can uncover patterns that point to unauthorized copying, even when the text has been significantly altered [1]. Unlike basic keyword matching, semantic analysis evaluates how words relate to one another and the underlying context of the text.
The process creates a "semantic space", grouping texts with similar stylistic and semantic traits. This clustering helps identify whether a rephrased piece retains the original’s writing pattern, even if the wording has been completely changed [5].
"In this ‘semantic space’ texts with similar stylistic and semantic properties are clustered together." – Jonathan Farrington, Silicon Dales [5]
Advanced semantic tools can even differentiate between multiple meanings of the same word, depending on the context [2]. This level of understanding enables the detection of subtle signs like smooth topic transitions and coherent flow – traits often found in AI-generated or heavily paraphrased material [10]. Machine learning models then take these insights and fine-tune the detection process by quantifying these contextual subtleties.
Machine Learning for Contextual Understanding
Machine learning models are trained on extensive datasets of both original and derivative texts. This training allows them to identify the unique "fingerprints" of various writing styles, analyzing vocabulary, syntax, and structure [5][2][8].
A standout example is BERT (Bidirectional Encoder Representations from Transformers), which examines the context of words by looking at the surrounding text in both directions. In tests, BERT achieved an impressive 93% accuracy when distinguishing original content from rewritten versions [9]. Premium detection tools using similar methods have reached up to 84% accuracy, while free tools typically hover around 68% [2].
However, no system is flawless. A Stanford study found that over 61% of essays written by non-native English speakers were wrongly flagged due to their formal and structured writing styles [2]. This underscores the need for human oversight, especially when reviewing highly structured content like technical, legal, or academic documents, which naturally show less variation [1][10].
Real-Time Monitoring and Automated Flagging
AI tools don’t just understand text semantics – they actively monitor the web to catch violations as they happen. By using advanced detection algorithms, real-time monitoring provides an extra layer of protection across the massive online landscape.
Web Scraping for Text Detection
AI systems are constantly scanning digital platforms, comparing new content against enormous databases of proprietary text. For example, one platform reportedly scans over 60 trillion web pages every month, identifying both AI-generated and plagiarized material [7]. This wide reach allows these tools to spot not only exact matches but also content that’s closely similar.
Here’s how it works: when suspicious content is flagged, the system performs a retrieval-based search across internal and external databases to confirm whether the material has been reused without permission. Many modern tools also feature a "source match" function, which helps verify how closely the content aligns with existing materials [7]. For businesses, these capabilities can be integrated directly into their workflows. With detection APIs in place, every piece of content – whether generated or published – can be automatically scanned before it goes live.
Automated Alerts and Reporting
Once a potential violation is detected, the system immediately validates the findings and notifies content owners.
These alerts include detailed reports, breaking down the matched content and highlighting specific sentences or phrases that triggered the system. Some tools even use "AI Logic" to pinpoint the exact patterns or phrases that raised red flags [8].
To assess the likelihood of a violation, the system combines probability scores, embedding distances, and pattern recognition. However, accuracy can vary. While some tools boast over 99% accuracy for detecting AI-generated content in English datasets [7], a 2023 evaluation of 14 popular AI detection tools revealed that none surpassed 80% accuracy [1]. This inconsistency highlights the need for a multi-layered approach – cross-checking results with different tools and involving human reviewers before taking action.
Using AI Tools Like ScoreDetect in Enterprise Workflows
Enterprises today need to weave AI-powered content protection directly into their workflows. Tools like ScoreDetect can integrate seamlessly with platforms such as Content Management Systems (CMS), Learning Management Systems (LMS), or editorial dashboards. These integrations allow for automated scanning of content throughout the creation pipeline, ensuring that every piece is checked before publication [7][8]. By leveraging advanced fingerprinting and semantic analysis, these tools make real-time enforcement not just a possibility but a streamlined process.
ScoreDetect stands out by offering easy integration through APIs and CMS plugins, simplifying adoption for enterprise teams.
ScoreDetect’s Blockchain Timestamping for Proof of Ownership
Proving ownership before a potential infringement occurs is a critical step in content protection. ScoreDetect uses blockchain technology to create tamper-proof timestamps for text-based content. Instead of storing the actual content, it captures a checksum, providing a secure and verifiable record of ownership. This is particularly important for legal and DMCA-related actions.
With its WordPress plugin, ScoreDetect timestamps every article that is published or updated. This process generates blockchain certificates that include key details such as registration dates, copyright owner names, SHA256 hashes, and public blockchain URLs. These certificates serve as solid documentation to prove originality. Additionally, ScoreDetect supports integration with over 6,000 web apps via Zapier, enabling enterprises to automate content timestamping across multiple platforms effortlessly.
AI-Driven Features in ScoreDetect
ScoreDetect doesn’t stop at securing ownership – it takes enforcement to the next level with proactive detection. Its Enterprise plan, powered by InCyan‘s AI, offers robust content protection. The platform’s web scraping technology boasts a 95% success rate in bypassing common barriers to identify unauthorized content online [7]. Once infringing material is found, automated analysis provides clear, quantitative proof. From there, the system can issue delisting notices, achieving an impressive 96% takedown rate.
For enterprises focused on text-specific protection, InCyan’s Txtmatch platform delivers unmatched speed and precision. Using a proprietary enterprise-scale database, Txtmatch ensures forensic-level accuracy when identifying copied text. This combination of blockchain-backed ownership records and AI-driven detection creates a comprehensive defense system. Industries like publishing, legal services, and marketing benefit significantly from ScoreDetect’s evidence-grade reports, which are tailored for academic integrity cases, legal disputes, and brand compliance reviews [3][8].
Conclusion
AI-powered tools for copyright detection have become a cornerstone for businesses managing digital content. These systems, using advanced techniques, provide a robust shield against unauthorized use. The U.S. Copyright Office emphasized this in its 2025 guidance, stating, "generative AI should be used as an assisting tool rather than as a replacement for human creativity" [14]. This highlights the increasing importance of verification systems to confirm human authorship and ownership, paving the way for stronger content protection strategies.
The digital landscape is evolving quickly. Technologies like invisible watermarking – Google’s SynthID Text being a prime example – embed subtle patterns to identify AI-generated content [11][15]. Simultaneously, licensing frameworks are gaining traction, with major publishers securing multi-million–dollar agreements to authorize their data for AI training [12]. These developments signal a shift toward proactive content protection, where AI-driven monitoring works alongside innovative technologies.
As these advancements reshape how content is monitored, businesses must adapt to safeguard their intellectual property. A March 2025 study revealed a significant change in user behavior: when AI-generated summaries were present, users clicked on traditional search results only 8% of the time, compared to 15% without such summaries [13]. This drop in traffic underscores the urgency of protecting original content. Tools like ScoreDetect and InCyan’s Txtmatch offer the speed and forensic accuracy required to defend intellectual property at scale, while also providing detailed documentation for legal and compliance needs.
The future of copyright protection will rely on multiple layers, including blockchain-based authorship verification, invisible watermarking, advanced semantic detection, and licensing frameworks like "CC Signals" [12]. By adopting tools such as ScoreDetect and Txtmatch, businesses can implement this multi-pronged approach. As Copyleaks put it, "In the age of generative AI, content integrity isn’t a nice-to-have. It’s essential" [7]. Companies that embrace these technologies now will be better equipped to protect their intellectual property, ensure compliance, and uphold their brand’s reputation in an increasingly AI-driven world.
FAQs
How can AI detect paraphrased plagiarism?
AI systems identify paraphrased plagiarism by examining text patterns, including sentence structure, word usage, and statistical markers like perplexity and burstiness. Perplexity evaluates how predictable the word choices are, while burstiness looks at variations in sentence structure. Instead of simply matching content to specific sources, these systems analyze stylistic and statistical characteristics, making it possible to detect even subtle paraphrasing that might go unnoticed by a human reader.
How accurate are AI copyright detectors?
AI copyright detectors work by assessing how likely it is that a piece of text was created by AI. They do this by examining statistical patterns, such as how predictable certain words are or how varied the sentences appear. Their accuracy can vary based on factors like the sophistication of the AI model used, the complexity of the text, and whether the content has been revised by a human. While these tools can be effective, they only offer probability scores instead of concrete conclusions. This makes them most useful when combined with other content review methods.
How does blockchain prove text ownership?
Blockchain establishes text ownership by creating a unique checksum – a digital fingerprint – of the content and recording it on a secure, tamper-resistant ledger. This process provides a timestamped and verifiable proof of ownership without storing the original text itself, safeguarding both the claim’s integrity and its credibility.

