Adversarial training is transforming the way audio watermarking protects digital content. It strengthens watermarking systems by simulating attacks, like noise addition or AI-driven manipulations, during training. This method addresses common issues such as desynchronization, codec compression, and advanced AI-based attacks, where traditional methods often fail. Key benefits include:
- Improved Resilience: Adversarial training reduces Bit Error Rates (BER) under conditions like noise, filtering, and neural vocoder processing.
- Dynamic Attack Simulation: Unlike older methods that rely on fixed distortions, this approach prepares systems for unpredictable manipulations.
- Enhanced Detection: Techniques like time-order-agnostic detection and advanced feature extraction improve accuracy even after audio edits.
For example, the AWARE system achieves a BER of just 1.61% under pink noise and neural vocoder attacks, outperforming older systems like WavMark (28.59%) and AudioSeal (10.89%). This makes adversarial training a key tool for safeguarding audio assets against piracy and AI-driven threats.
Responsible AI for Offline Plugins – Tamper-Resistant Neural Audio Watermarking – Kanru Hua ADC 2024
Why Standard Audio Watermarking Methods Fall Short
Conventional audio watermarking systems often stumble when confronted with unpredictable, real-world conditions. These methods typically rely on fixed transformations like DCT, DWT, or FFT, which can only handle a narrow range of attacks [5]. When unexpected manipulations occur, watermarks that perform well in controlled environments often fail in practice.
Dependence on Predefined Distortions
Most traditional watermarking methods are developed using a set of predefined attack simulations. These simulations include a limited menu of distortions that the system is trained to handle [7]. However, real-world audio processing rarely follows a predictable script. When audio undergoes unfamiliar transformations, the performance of these systems can degrade significantly. For instance, under the common neural vocoder process used in AI voice cloning, WavMark shows a Bit Error Rate (BER) of 50.00%, while AudioSeal records a BER of 39.01% [7].
As Shiqiang Wu from the Chinese Academy of Sciences highlights:
"Hand-designed algorithms can only consider those pre-defined attacks, representing a small part of all attack types."
– Shiqiang Wu, Institute of Automation, Chinese Academy of Sciences [5]
This reliance on predefined distortions limits the ability of these systems to adapt to novel manipulations, often referred to as "out-of-distribution" attacks. This gap in adaptability leaves them vulnerable, especially as new AI-driven techniques exploit these weaknesses.
Weak Defense Against New Threats
Emerging AI-powered attacks expose the inherent vulnerabilities of traditional watermarking systems even further. Techniques like neural audio compression and "regeneration attacks" – where audio is re-encoded using high-fidelity models such as DAC or EnCodec – have proven highly effective in bypassing these systems [2]. For example, when tested on the MUSDB18-HQ dataset, AudioSeal recorded a BER of 66.46% under regeneration attacks, while WavMark showed a BER of 49.24% [2].
Security concerns compound these challenges. Research from the University of Houston and other institutions in December 2025 demonstrated that modern neural watermarking systems, including AudioSeal, Timbre, and WavMark, are highly susceptible to overwriting attacks. By layering a forged watermark over an existing one, researchers achieved nearly a 100% success rate in erasing the original watermark across datasets like LibriSpeech and VoxCeleb1 [8]. The findings revealed that these systems rely more on obscurity than on robust cryptographic methods.
"Current neural audio watermarking methods focus primarily on the imperceptibility and robustness of watermarking, while ignoring its vulnerability to security attacks."
– AAAI 2026 [3]
These vulnerabilities highlight a significant gap in the design of existing systems, which fail to account for both targeted and incidental manipulations.
Performance Issues in Practical Use
When it comes to real-world audio editing, watermark synchronization often breaks down, leading to higher error rates. Common editing practices like mixing, changing playback speed, filtering, and splicing can disrupt the synchronization mechanisms that traditional watermarking systems depend on [7]. For instance, trimming or splicing audio – a routine step in music production or podcast editing – can render watermarks irretrievable, as many systems embed data within single frames or small groups with minimal redundancy [7].
Specific examples of performance issues include:
- Low-pass filtering: AudioSeal’s BER rises to 14.58%.
- Band-stop filtering: AudioSeal’s BER climbs to 33.81%.
- MP3 compression at 64 kbps: WavMark records a BER of 24.12%.
- Pink noise: WavMark’s BER reaches 28.59%, while AudioSeal fares slightly better at 10.89%.
- Neural vocoder processing: WavMark and AudioSeal face BERs of 50.00% and 39.01%, respectively [7].
| Attack Condition | WavMark BER (%) | AudioSeal BER (%) |
|---|---|---|
| Low-Pass Filter | 0.00 | 14.58 |
| Band-Stop Filter | 0.00 | 33.81 |
| MP3 Compression (64 kbps) | 24.12 | 0.24 |
| Pink Noise | 28.59 | 10.89 |
| Neural Vocoder | 50.00 | 39.01 |
Source: [7]
The underlying problem is clear: these systems are optimized for a small set of predictable distortions, leaving them unprepared for the wide variety of manipulations encountered in real-world scenarios [5].
How Adversarial Training Improves Audio Watermarking
Audio Watermarking Performance Comparison: Traditional vs Adversarial Training Systems
Adversarial training steps up to address the challenges of desynchronization and codec compression in audio watermarking. By simultaneously training both an embedder and a discriminator, this approach eliminates the need for static attack simulations, offering a more dynamic and adaptable solution[4].
Building Stronger Watermarks Through Adversarial Optimization
At the heart of this method is the creation of watermarks by introducing minimal changes to the original audio. These changes, guided by backpropagation, help a differentiable detector identify the intended watermark bits[5][7]. A "push loss" function is employed to ensure confident bipolar decisions, while keeping the audio quality intact by controlling the level of perturbation[7].
To further enhance robustness, an attack layer is included to mimic real-world distortions. As Pengcheng Li et al. describe:
"The attack layer which simulates common damages on the watermarked media is introduced into the Embedder-Extractor structure to guarantee the robustness." – Pengcheng Li et al.[4]
Advanced techniques like PCA-based whitening and Invertible Neural Networks with balance blocks are also integrated. These additions stabilize the training process and minimize interference between watermark bits, ensuring a more reliable system[4][5].
Better Detection Methods
Adversarial training also improves the performance of detectors, making them resilient to audio manipulations. Techniques like time-order-agnostic detection, achieved through 1×1 convolutions, and the Bitwise Readout Head (BRH), reduce the impact of edits like cuts. For instance, under sample deletion attacks, these methods achieved a Bit Error Rate (BER) of just 3.74%, compared to 30.91% with older approaches[7].
Feature extraction plays a key role here as well. Using Mel-spectrogram representations enhances the system’s ability to withstand voice cloning and synthesis attacks. Since Mel features are commonly used in text-to-speech and vocoder systems, they offer a more robust foundation. Against neural vocoder resynthesis using BigVGAN, adversarial detectors based on Mel features achieved a BER of just 1.61%, while detectors relying solely on STFT features saw their BER soar to 50.30%[7].
The BRH also aggregates temporal evidence into a single score per watermark bit, making decoding reliable even when the audio is trimmed or spliced. Some systems go a step further by employing a dual-embedding strategy: a lightweight "locating code" identifies the watermark’s position, after which the full message is extracted. This approach helps to save computational resources while maintaining accuracy[4].
These advanced detection methods have directly contributed to the improved performance seen in various tests.
Test Results and Performance Data
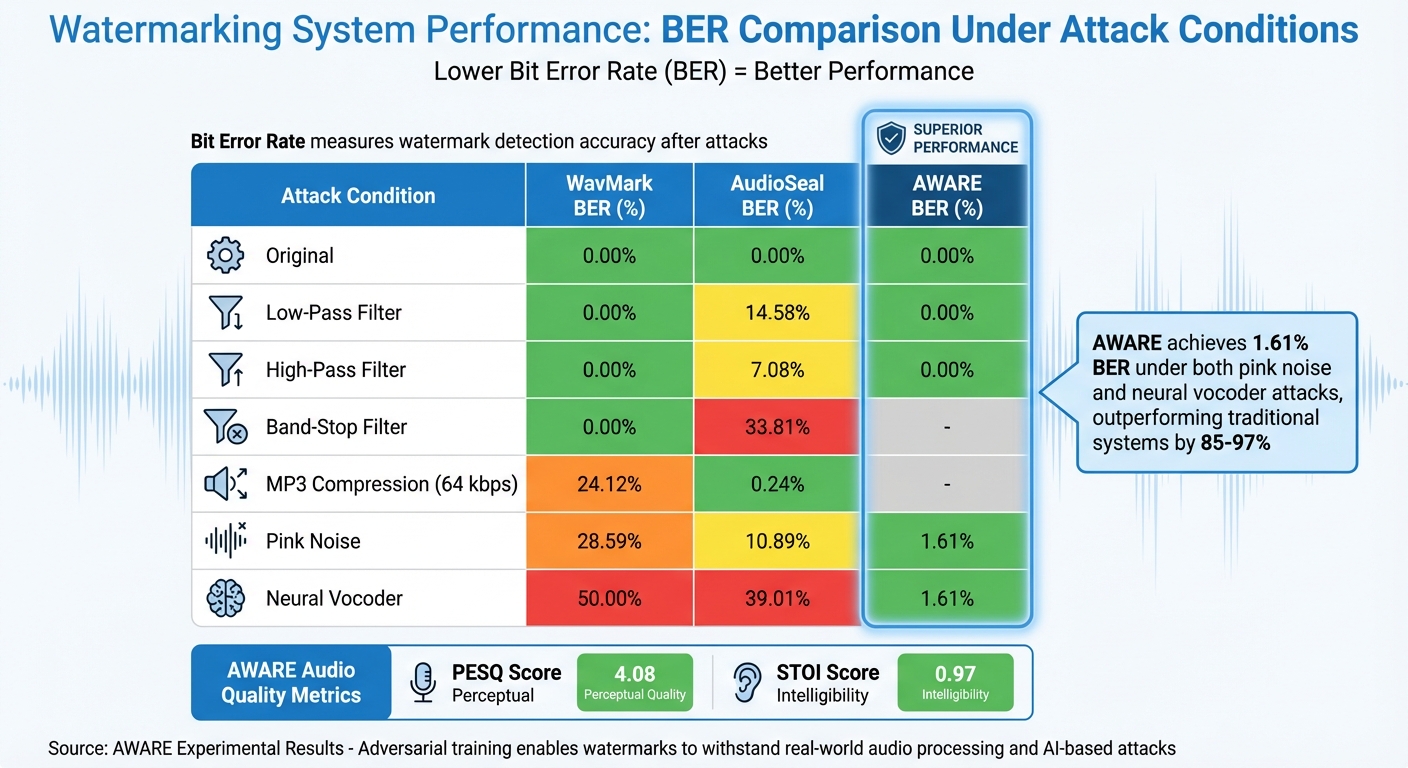
The impact of these advancements is evident in measurable performance improvements. For instance, the AWARE system, which uses adversarial optimization, achieved a Perceptual Evaluation of Speech Quality (PESQ) score of 4.08 and a Short-Time Objective Intelligibility (STOI) score of 0.97[7]. It also maintained a 0.00% BER under both low-pass and high-pass filtering – scenarios where traditional systems often falter.
| Condition | WavMark BER (%) | AudioSeal BER (%) | AWARE BER (%) |
|---|---|---|---|
| Original | 0.00 | 0.00 | 0.00 |
| Low-Pass Filter | 0.00 | 14.58 | 0.00 |
| High-Pass Filter | 0.00 | 7.08 | 0.00 |
| Pink Noise | 28.59 | 10.89 | 1.61 |
| Neural Vocoder | 50.00 | 39.01 | 1.61 |
Source: AWARE Experimental Results [7]
Under challenging conditions like pink noise, AWARE recorded a BER of just 1.61%, significantly outperforming WavMark (28.59%) and AudioSeal (10.89%). Against neural vocoder processing, a common technique in AI-driven voice cloning, AWARE once again excelled with a BER of 1.61%, while traditional systems struggled with error rates of 39.01% and 50.00%. These results highlight the resilience of adversarially trained watermarks, making them capable of withstanding both routine audio processing and advanced AI-based attacks.
sbb-itb-738ac1e
Where Adversarial Training Is Used in Audio Watermarking
Working with Anti-Piracy Tools
Adversarial training plays a key role in modern anti-piracy strategies, especially when integrated into robust protection platforms. For instance, in May 2025, Sony Research‘s RAW-Bench framework demonstrated how adversarial training effectively counters neural codec distortions in watermarking systems[10]. This approach employs an Attack Simulation Layer (ASL) to replicate common piracy distortions, enabling watermarks to resist unauthorized manipulation[5]. These advancements pave the way for systems that can better safeguard digital audio against increasingly sophisticated piracy techniques.
A notable case from 2023 highlighted how voice deepfakes were exploited to manipulate AI-generated voices for fraudulent purposes. This incident underscored the importance of embedding traceable signals that can withstand even advanced voice conversion methods[1]. Similarly, research presented at AAAI 2026 showed that neural watermarks could be entirely compromised through overwriting attacks unless fortified with adversarial training, which proved essential for maintaining their integrity[3]. This evidence highlights why industries like media, entertainment, and cybersecurity must prioritize adversarial optimization in their anti-piracy tools.
Platforms such as ScoreDetect tackle these challenges by integrating invisible watermarking with intelligent web scraping, achieving a 95% success rate in content detection. Additionally, their automated takedown notices secure a takedown rate of over 96%. When adversarial training is applied to the watermarking process, it ensures that embedded identifiers remain intact even after extensive editing or compression, enabling reliable detection and supporting legal actions.
Protecting Digital Audio Assets
Adversarial training extends beyond anti-piracy measures to enhance the protection of large-scale audio libraries. Companies managing extensive audio collections – ranging from music archives to podcast libraries – face ongoing risks from unauthorized distribution and AI-driven theft. Adversarial training provides a practical solution for safeguarding these assets without requiring retraining of original generative models or maintaining large training datasets[2][9]. For example, the Timbru model significantly improves protection for high-fidelity 44.1 kHz stereo audio compared to older methods using 16 kHz mono audio[2].
Deploying adversarially trained watermarking systems involves several key steps:
- Simulating neural codec attacks, as codecs like Encodec and DAC can reduce bitwise accuracy below 0.5[10].
- Using Just Noticeable Difference (JND) maps to hide watermarks within intricate audio textures[9].
- Regularly updating the attack library with new distortions to maintain high bit-recovery rates as piracy tools evolve[10][6].
In December 2025, Meta AI researchers introduced Pixel Seal, an adversarial-only training framework. Tests on 1,000 Meta AI-generated images showed that the system retained its robustness against combined attacks, such as brightness adjustments, cropping, and heavy JPEG compression[9]. While initially designed for visual media, this approach is equally applicable to audio protection.
"Our approach attains the best average bit error rates, while preserving perceptual quality, demonstrating an efficient, dataset-free path to imperceptible audio watermarking." – Luca A. Lanzendorfer, ETH Zurich[2]
ScoreDetect also incorporates blockchain timestamping to create verifiable proof of ownership through content checksums. This dual-layer strategy – combining resilient watermarking with blockchain verification – offers both technical durability and legal backing for industries such as education, content creation, law, and software development.
Conclusion
Key Takeaways
The world of digital content protection is constantly evolving, and adversarial training is reshaping audio watermarking by tackling its most persistent challenges. Traditional methods, like those using DCT or DWT transforms, focus on pre-defined attack scenarios. But adversarial training takes it a step further, enabling watermarks to adapt to and resist unpredictable distortions through neural network optimization[5][6]. This ensures your audio remains protected even as piracy tactics grow more sophisticated.
For instance, standard systems like SilentCipher experience bit error rates of 24.25% under attack, while adversarially trained models such as Timbru significantly reduce these rates to 14.89% across 16 different attack types[2]. Traditional watermarks often falter when faced with neural codecs, but adversarial methods embed markers deep within audio features, ensuring reliable detection even under such conditions[10].
"The adversarial-only training paradigm eliminates unreliable pixel-wise imperceptibility losses and avoids the failure modes associated with traditional loss functions." – Tomáš Souček, Meta FAIR[9]
Adversarial training also addresses the long-standing issue of perceptual quality in watermarking. By using discriminators that simulate human hearing instead of relying on metrics like MSE, these methods keep watermarks both robust and imperceptible[9][11]. This balance makes adversarial approaches a game-changer for professional audio industries where quality cannot be compromised.
Next Steps
With these advancements in mind, it’s time to assess how you’re protecting your digital audio assets. Whether you’re managing music libraries, podcasts, or proprietary recordings, ask yourself: Are your watermarks holding up against modern compression techniques? Can they withstand manipulation powered by AI?
ScoreDetect offers a solution by combining invisible watermarking, enhanced with adversarial training, and intelligent detection systems. The platform boasts a 95% success rate in content discovery and over 96% in automated takedowns. By integrating blockchain timestamping, it also provides verifiable ownership proof, offering both technical durability and legal strength.
With seamless integration into over 6,000 web apps via Zapier, ScoreDetect enables automated workflows that protect your content from the moment it’s created. For creators, marketers, and media companies grappling with rising piracy threats, adversarial-trained watermarking isn’t just an upgrade – it’s quickly becoming a critical tool for safeguarding digital assets.
FAQs
How does adversarial training make audio watermarks more resistant to AI-based attacks?
Adversarial training strengthens the durability of audio watermarks by mimicking potential attacks that could distort or remove them. By exposing the system to these simulated threats during training, the watermarking process learns to embed marks that can endure challenges like heavy noise, compression, and gradient-based alterations.
This approach integrates attack scenarios directly into the training phase, striking a balance between keeping the watermark subtle and ensuring it remains identifiable even under harsh conditions. Tools such as ScoreDetect use this technique to create invisible, tamper-proof watermarks, offering enhanced security for copyrighted audio files.
How does adversarial training improve audio watermarking compared to traditional methods?
Traditional audio watermarking systems rely on fixed, manually designed rules to embed data into audio signals. These methods often use techniques based on the time domain or transform domain. While they can be effective in certain scenarios, they tend to struggle against challenges like compression, added noise, or reverb. As a result, their ability to maintain robustness, handle larger data capacities, and preserve audio quality is limited.
Adversarial training offers a different approach. By leveraging deep learning models trained on simulated attack scenarios, this method enhances watermarking’s resistance to distortions. The outcome? Greater robustness, higher data capacity, and improved sound quality that remains nearly imperceptible. Although these systems demand more computational power and precise fine-tuning, they mark a major step forward in safeguarding audio content from unauthorized use.
ScoreDetect builds on these advancements by using AI-powered, undetectable watermarking technology. Its solutions are engineered to endure common audio attacks while delivering exceptional sound quality, showcasing a move toward more intelligent and adaptive protection strategies.
How does adversarial training enhance the protection of digital audio watermarks?
Adversarial training has emerged as a powerful method for safeguarding digital audio watermarks against modern threats. Attackers today can apply subtle, nearly imperceptible tweaks to audio files that erase or distort watermarks while keeping the audio quality intact. By exposing watermarking systems to these kinds of manipulations during the training process, adversarial training equips them to handle real-world challenges like compression, background noise, and advanced AI-driven alterations.
This technique ensures that watermarks stay intact and detectable even after undergoing aggressive processes such as pruning, fine-tuning, or overwriting. When paired with simulations of various attack methods – like time-stretching, polarity inversion, and reverberation – it significantly bolsters watermark durability. This makes it far more difficult for unauthorized users to tamper with or strip the watermarks. In an era dominated by AI-generated audio and rapid content distribution, such proactive measures are crucial for protecting creators’ rights and maintaining the traceability of digital assets.

