Neural audio watermarking embeds hidden information into audio to protect ownership, verify authenticity, and detect tampering. However, these systems face critical vulnerabilities, especially against overwriting attacks, where adversaries replace legitimate watermarks with fake ones. This article examines three systems – AudioSeal, Timbre, and WavMark – highlighting their strengths and weaknesses in imperceptibility, robustness, and security.
Key findings:
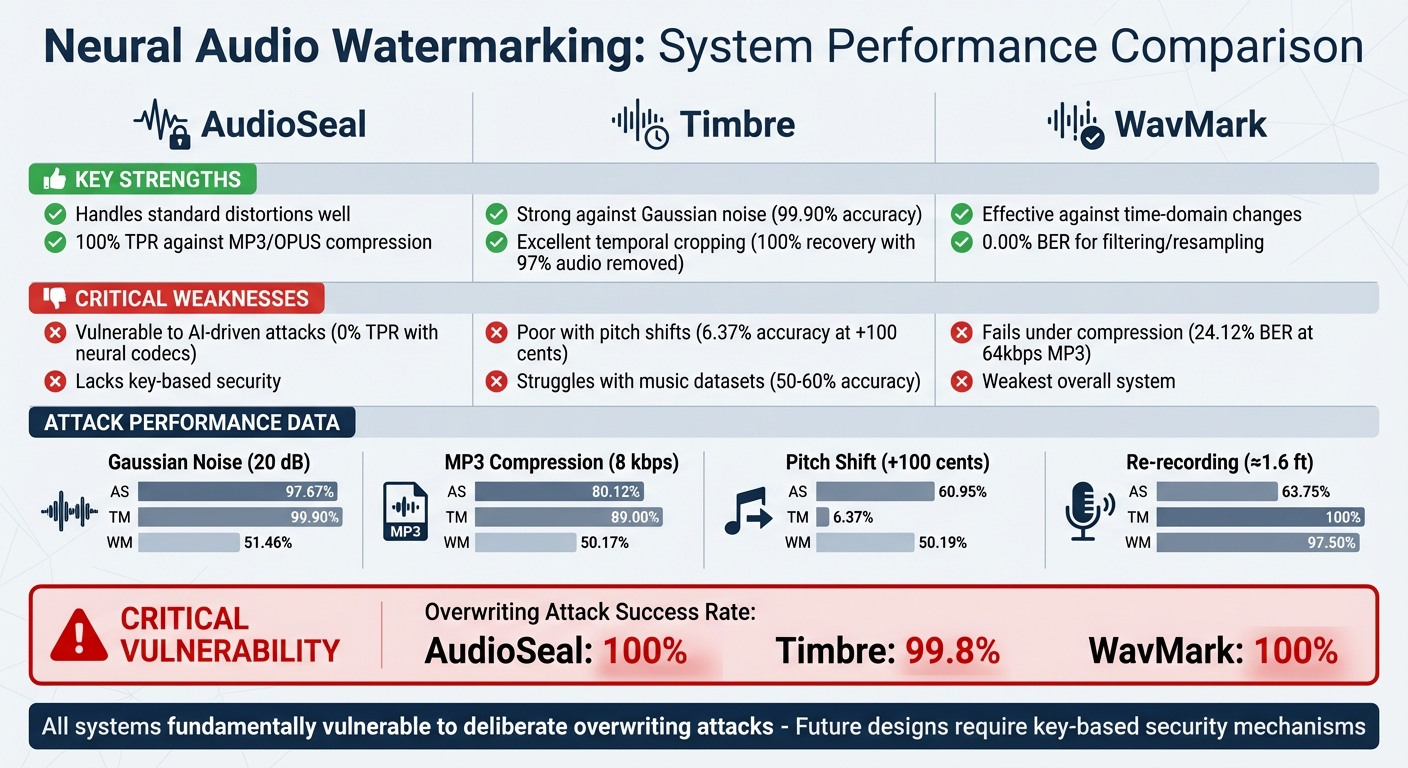
- Overwriting attacks succeed nearly 100% of the time across all systems, rendering watermarks unreliable.
- AudioSeal withstands standard distortions but fails against AI-driven manipulations and lacks robust security measures.
- Timbre performs well against Gaussian noise but struggles with pitch shifts and long-distance re-recording.
- WavMark is effective against time-domain changes but is the weakest overall, failing under compression and neural codec attacks.
Quick Comparison
| System | Strengths | Weaknesses | Overwriting Attack Success Rate |
|---|---|---|---|
| AudioSeal | Handles standard distortions well | Vulnerable to AI-driven attacks and lacks key-based security | 100% |
| Timbre | Strong against Gaussian noise | Poor with pitch shifts and music datasets | 99.8% |
| WavMark | Effective against time-domain changes | Fails under compression and neural codecs | 100% |
Conclusion: All three systems are fundamentally flawed in resisting deliberate attacks, particularly overwriting. Future designs must incorporate stronger, key-based security mechanisms to address these issues.
Neural Audio Watermarking Systems Performance Comparison: AudioSeal vs Timbre vs WavMark
AI’s New Threat: Self Voice Conversion & Audio Watermarks
sbb-itb-738ac1e
1. AudioSeal
AudioSeal is a neural watermarking system designed to work in the time domain, built on the Encodec platform. It embeds watermark messages directly into the latent space of the neural codec, using redundant embedding techniques to withstand compression and resampling [1][5]. To maintain audio quality and ensure the watermark remains undetectable to listeners, the system incorporates perceptual loss during its training process [1].
This section examines AudioSeal’s performance across three key areas: imperceptibility, robustness, and security.
Attack Success Rates
AudioSeal faces major challenges when it comes to overwriting attacks. In both white-box attacks (where the attacker has full access to the embedder) and gray-box attacks (using surrogate models with similar architecture), attackers achieve a 100% success rate in replacing the original watermark with a forged one [1]. Under these conditions, the Bit Error Rate (BER) of the legitimate watermark rises to nearly 50%, making detection as unreliable as random guessing. Meanwhile, the forged watermark introduced by the attacker is recovered with perfect accuracy [1].
AI-driven distortions, such as those caused by Encodec-VoiceCraft and SpeechTokenizer, further compromise the system. These neural codecs act as passive removal tools, reducing the True Positive Rate (TPR) to almost 0% [7]. While these distortions suppress watermark detection, they still preserve the original audio quality.
Although AudioSeal demonstrates resilience to standard signal processing, its vulnerabilities to deliberate overwriting and AI-induced distortions significantly weaken its overall reliability.
Robustness Against Distortions
AudioSeal performs well against standard signal-level distortions. It maintains a 100% TPR at a 1% False Positive Rate when subjected to transformations like 20dB SNR Gaussian noise, MP3 compression at 24kbps, and OPUS compression [7]. This robustness is largely due to distortion-aware training, where the model is exposed to various time modifications, audio effects, filtering, and compression techniques during development [1].
However, the system struggles to handle physical-level distortions such as re-recording in environments with reverberation or background noise. Similarly, it cannot withstand AI-induced manipulations like voice conversion or text-to-speech transformations [5]. These gaps highlight a trade-off in its design: while AudioSeal excels at surviving unintentional signal processing changes, it lacks defenses against intentional adversarial attacks.
Defense Mechanisms
AudioSeal employs sample-level temporal resolution detection, analyzing smaller audio segments and averaging scores across them, instead of relying on a single detection score for the entire audio file [1]. Its architecture is optimized for both watermark detection and message recovery, making it a useful tool for tracking content provenance and protection.
However, the system’s reliance on a "security-through-obscurity" model poses a significant weakness. Instead of employing explicit key-based security measures, AudioSeal depends on keeping its model weights confidential [7]. This approach becomes particularly fragile in open-source settings, where adversaries can reverse-engineer or gain access to the model. Since AudioSeal embeds watermarks as additive perturbations within the Encodec latent space, attackers using the same embedding method can easily compromise it. In contrast, attacks from different embedding domains, such as frequency-domain systems, are typically less effective at destroying the watermark [1].
While AudioSeal demonstrates some advanced features, its lack of robust security mechanisms leaves it vulnerable in adversarial scenarios.
2. Timbre

Timbre takes a different approach compared to AudioSeal by focusing on frequency-domain techniques, which come with their own set of challenges. Instead of working in the time domain, Timbre embeds watermarks in the spectrogram’s amplitude using the Short-Time Fourier Transform (STFT) while preserving the phase [8].
Attack Success Rates
Timbre shows vulnerabilities to frequency-based manipulations. For example, a +100 cents pitch shift drastically reduces bit recovery accuracy to just 6.37% [3]. Voice conversion attacks in zero-shot scenarios also lead to a sharp drop in accuracy, bringing it down to 48.52%, which is close to random detection levels [3]. Additionally, white-box overwriting attacks are highly effective, achieving a 99.80% success rate, allowing attackers to replace legitimate watermarks with counterfeit ones [9].
Physical attacks reveal additional weaknesses. Re-recording audio at a distance of 0.5 meters (about 1.6 feet) maintains 100% accuracy, but this drops significantly to 64% when the distance increases to 5 meters (approximately 16.4 feet) [3]. Even setting just 10% of audio samples to zero causes accuracy to fall to 51.28% [3].
These findings highlight areas where Timbre struggles when subjected to various attack methods.
Robustness Against Distortions
Timbre’s performance under distortions varies depending on the type of audio. While it handles speech content effectively, it struggles with music. For speech data, Timbre demonstrates strong resilience. It achieves 99.90% accuracy even under 20 dB Gaussian noise and nearly perfect accuracy (99.99%) at 16 kbps MP3 compression [3]. It also performs exceptionally well in temporal cropping scenarios, recovering nearly 100% of bits even when 97% of the audio is removed [3].
However, when tested on music or singing datasets like M4Singer, its accuracy drops significantly, often landing in the 50–60% range for similar distortions [3]. In contrast, speech datasets like LJ Speech frequently see 100% accuracy across various distortions. Neural codecs, such as EnCodeC, present additional challenges, even when Timbre is trained to account for such compression techniques [8][2].
Defense Mechanisms
To defend against adversarial attacks, Timbre employs a combination of ISTFT, normalization, and wave reconstruction techniques [2]. Its hybrid-domain processing integrates features from both time and frequency domains, which helps it resist AI-driven removal methods. The system uses a bitwise accuracy metric to confirm watermarks, requiring a certain proportion of matching bits to exceed a predefined threshold for validation.
Despite these defenses, Timbre lacks key-based security measures, leaving it exposed in open-source environments where attackers can access the embedding method [9]. Additionally, its robustness can vary across different demographic groups, such as biological sex and language, under specific perturbations, raising questions about its fairness [8].
3. WavMark

Security evaluations have highlighted major weaknesses in WavMark’s design. This system uses invertible neural networks (INN) to embed watermarks within the frequency domain, treating both embedding and extraction as reversible processes [4][9]. It encodes 32 bits of data per second by converting audio into spectrograms using the Short-Time Fourier Transform (STFT) [10][11]. To ensure extraction remains reliable even after signal distortions, synchronization bits are embedded alongside the watermark payload [8][9].
Attack Success Rates
A 2025 study conducted by researchers at the University of Houston and Waseda University tested WavMark’s resilience using the LibriSpeech and VoxCeleb1 datasets. The results were striking: overwriting attacks achieved a 100% success rate, completely replacing the original watermarks. This left the original watermark undetectable, with a Bit Error Rate (BER) of about 50%, equivalent to random guessing [9].
"Overwriting attacks compromise watermarks with near 100% success." – Lingfeng Yao et al., University of Houston [9]
Further analysis from the 2024 AudioMarkBench study, presented at NeurIPS, identified WavMark as particularly vulnerable among neural watermarking systems. The study tested 15 different perturbations and found that even simple techniques like Gaussian noise and MP3 compression could remove WavMark’s watermarks, all while maintaining acceptable audio quality (ViSQOL ≥ 3) [12].
"WavMark is the least robust [among evaluated methods]. For instance, watermarks embedded by WavMark can even be removed by Gaussian noise and MP3 compression without compromising the watermarked audios’ quality." – AudioMarkBench [12]
These findings underscore WavMark’s limited resistance to various forms of attack, raising questions about its practical reliability.
Robustness Against Distortions
WavMark’s ability to withstand distortions depends heavily on the type of transformation applied. It shows no errors (0.00% BER) when subjected to low-pass filtering, high-pass filtering, or resampling. It also performs well against sample deletions, with a BER of 1.43%, and holds up moderately against time-scale modifications, achieving a 9.98% BER [13].
However, certain transformations expose its vulnerabilities. MP3 compression at 64 kbps leads to a BER of 24.12%, while 8-bit PCM quantization results in a BER of 24.46%. Pink noise pushes the BER even higher, to 28.59%. Comparatively, other systems like AudioSeal (10.89% BER) or AWARE (1.61% BER) fare much better under similar conditions. Pitch-shifting and neural vocoder resynthesis render WavMark’s watermarks entirely ineffective, resulting in a BER of 50% [13].
On average, WavMark achieves a BER of 0.48% across ten types of attacks, which is a 28-fold improvement over Audiowmark [10][11].
Defense Mechanisms
WavMark incorporates several defenses to bolster its resilience against distortions. It uses Brute Force Detection (BFD), which combines pattern bits with the payload, enabling the model to locate watermarks without relying on external synchronization codes. The synchronization bitstring must match a predefined pattern exactly for successful extraction [11][8]. Additionally, a shift module aids in recovering watermarks from nearby positions, mitigating de-synchronization attacks [4].
To further strengthen its defenses, WavMark employs a curriculum learning approach, exposing the model to a broad range of simulated distortions – such as noise, filtering, compression, echo, and time stretching – during training. This process uses a diverse dataset of 5,000 hours, encompassing speech, music, and event sounds [2][11].
Despite these strategies, WavMark’s reliance on the secrecy of its model weights remains a critical weak point. This dependency is especially concerning given the capabilities of modern reverse engineering techniques [9].
Pros and Cons
This section breaks down the strengths and weaknesses of each system, summarizing their performance across various challenges.
AudioSeal stands out for its ability to handle signal-level distortions effectively. However, it struggles with speed changes and is particularly vulnerable to AI-driven codec attacks like FACodec [3][7].
Timbre performs well in physical robustness tests, especially in close-range re-recording scenarios, and handles Gaussian noise better than the others [3]. It also manages speed changes more effectively than AudioSeal [7]. That said, its Achilles’ heel is pitch shifting – a +100 cent shift drops its bit recovery accuracy to a mere 6.37%, compared to AudioSeal’s 60.95% [3].
WavMark excels in resisting time-domain modifications and performs admirably in close-range re-recording [3]. However, it is the weakest overall, showing poor resistance to Gaussian noise, MP3 compression at 8 kbps, and neural codecs [3].
A shared vulnerability across all three systems is their near-total susceptibility to overwriting attacks in white-box scenarios, with success rates close to 100% [9]. Additionally, none of the systems perform well against AI-induced attacks like Voice Conversion, with bit recovery accuracies ranging between 51% and 65%, barely above random chance [3].
Below is a table summarizing the comparative performance of these systems:
| Attack Type | AudioSeal | Timbre | WavMark |
|---|---|---|---|
| Gaussian Noise (20 dB) | 97.67% | 99.90% | 51.46% |
| MP3 Compression (8 kbps) | 80.12% | 89.00% | 50.17% |
| Pitch Shift (+100 cents) | 60.95% | 6.37% | 50.19% |
| Re-recording (≈1.6 ft) | 63.75% | 100% | 97.50% |
| Speed Change | 0.15 TPR | 0.27 TPR | 0.00 TPR |
| Overwriting Attack | 100% | 99.8% | 100% |
This comparison highlights the urgent need for stronger defenses against adversarial attacks in neural audio watermarking technologies. Each system has areas of strength, but none are fully equipped to handle the full spectrum of challenges.
Conclusion
AudioSeal, Timbre, and WavMark each bring distinct advantages to the table but share a glaring weakness: susceptibility to overwriting attacks. AudioSeal’s latent space design ensures high imperceptibility, Timbre shows strong resistance to Gaussian noise and common distortions, and WavMark, built on invertible neural network architectures, excels in high-fidelity recovery.
However, all three systems struggle against overwriting attacks, which boast nearly 100% success rates. Neural compression further complicates matters by erasing the subtle signals essential for watermark authentication [1]. This highlights a critical flaw: current approaches rely too heavily on "security through obscurity" instead of robust, key-based mechanisms.
"The proposed overwriting attacks can effectively compromise existing watermarking schemes across various settings and achieve a nearly 100% attack success rate" – Lingfeng Yao et al. [1]
"Neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions" – Yigitcan Özer, Sony AI [6]
These findings underscore the need for a paradigm shift in watermarking design. Future systems must prioritize proactive security measures, such as key-based authentication, dual-embedding strategies, and balanced block integration, to address these vulnerabilities [4][1]. The focus must shift from merely resisting unintentional noise to countering deliberate adversarial attacks, ensuring these technologies are viable for real-world applications.
In tackling these challenges, emerging solutions are making strides. ScoreDetect (https://www.scoredetect.com) provides a complementary approach with blockchain-based content verification and automated takedown workflows, achieving a 96% takedown success rate. While as AI improves audio watermarking accuracy, combining multiple layers of protection – technical, legal, and procedural – remains the most effective strategy for safeguarding digital audio assets.
FAQs
What is an overwriting attack in audio watermarking?
An overwriting attack in audio watermarking happens when a counterfeit watermark replaces the original one. This makes the legitimate watermark undetectable, undermining the audio’s embedded security and protection.
Why do neural codecs and voice conversion break watermarks so easily?
Neural codecs and voice conversion challenge the reliability of watermarks by introducing major distortions and transformations to audio signals. Neural processing changes the low-level features of the audio, while voice conversion tweaks elements like pitch and timing. These alterations make it much harder to identify or extract embedded watermark data. On top of that, techniques such as polarity inversion, time stretching, and adversarial attacks further weaken the durability of watermarks, especially in systems that rely on neural processing.
What would ‘key-based’ audio watermarking change in practice?
Key-based audio watermarking steps up security by incorporating cryptographic keys for both embedding and detection. This means that only individuals with the correct key can insert or retrieve the watermark, making it much tougher for unauthorized parties to tamper with or remove it. While managing these keys securely is crucial, this method greatly bolsters protection against attacks like overwriting. It also enhances the reliability of watermarks, making them a strong tool for copyright protection and verifying sources – particularly in AI-focused applications.

