Audio watermarking embeds hidden signatures in audio files to verify ownership and protect copyrights. However, older methods often fail under compression, noise, or other distortions. Neural networks are transforming this space by simultaneously improving watermark durability and maintaining audio quality.
Key advancements include:
- Neural Models: These use layers that simulate distortions like noise or compression during training, ensuring watermarks survive common audio transformations.
- Psychoacoustic Loss Functions: Techniques like Noise-to-Mask Ratio (NMR) loss align with human hearing, making watermarks inaudible while retaining quality.
- Waveform vs. Spectrogram Models: Waveform models excel in precise detection, while spectrogram models use frequency masking for better resilience.
- Adversarial Training: Embedders and discriminators work together to create resilient, undetectable watermarks.
- Attack Simulation: Training includes real-world distortions like MP3 compression and time-stretching to ensure watermark survival.
Challenges persist with neural compression codecs like EnCodec, which strip subtle audio details, reducing watermark reliability. Future research focuses on codec-aware designs and advanced optimization methods to address these issues.
Neural watermarking is reshaping content protection, offering tools like ScoreDetect for automated monitoring and blockchain integration for ownership verification.
Responsible AI for Offline Plugins – Tamper-Resistant Neural Audio Watermarking – Kanru Hua ADC 2024
sbb-itb-738ac1e
Neural Network Architectures for Audio Watermarking
Neural Audio Watermarking Model Performance Comparison
Waveform-Based Neural Networks
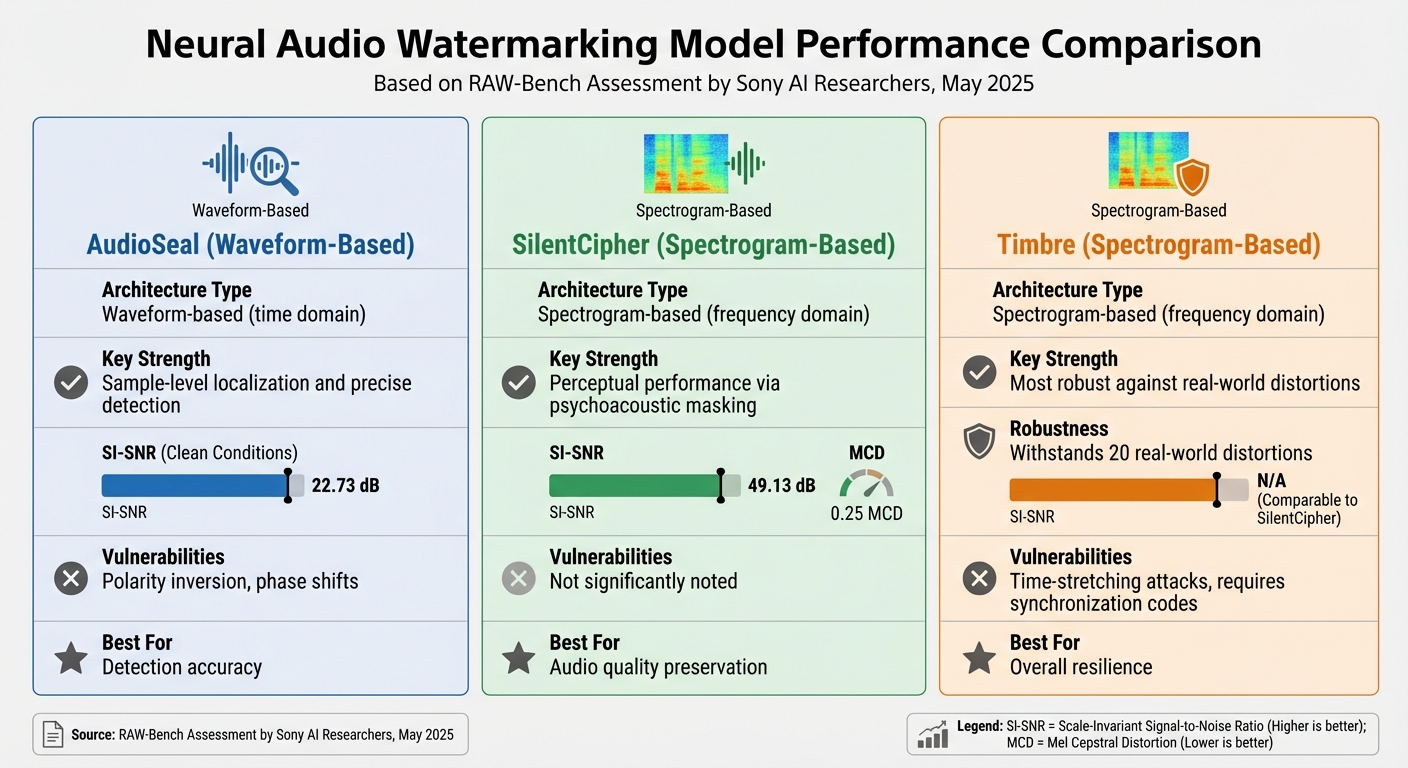
Waveform-based models work directly with raw audio data in the time domain, analyzing the audio at the sample level. A standout example is AudioSeal, a model designed to pinpoint the exact location of a watermark within an audio file. This precision, often referred to as sample-level localization, makes it highly effective at detecting forensic audio watermarking and resisting attacks like sample suppression and gain adjustments [1][4]. However, AudioSeal isn’t without its weaknesses. In testing, it achieved a Scale-Invariant Signal-to-Noise Ratio (SI-SNR) of 22.73 dB under clean conditions but showed vulnerabilities to polarity inversion and phase shifts [1][4]. While waveform-based models shine in detection accuracy, spectrogram-based approaches bring a different set of strengths to the table.
Spectrogram-Based Neural Networks
Spectrogram-based architectures process audio in the frequency domain, often using methods like the Short-Time Fourier Transform (STFT) or Discrete Wavelet Transform (DWT). Models such as SilentCipher and Timbre represent this category [3][4]. These systems take advantage of psychoacoustic masking – embedding watermarks in ways that align with how humans naturally perceive sound.
In May 2025, Sony AI researchers conducted the RAW-Bench assessment, analyzing four major watermarking models. Their study highlighted SilentCipher’s strong perceptual performance, with an SI-SNR of 49.13 dB and a Mel Cepstral Distortion (MCD) of just 0.25. On the other hand, Timbre proved to be the most robust, holding up against 20 real-world distortions. Despite their strengths, spectrogram-based models often require synchronization codes for accurate watermark extraction and are susceptible to time-stretching attacks.
In September 2024, Ping An Technology introduced IDEAW (Invertible Dual-Embedding Audio Watermarking), a model that processes audio in the STFT domain. IDEAW uses a dual-stage invertible neural network to embed two separate components: a "locating code" and a "message." This design speeds up the watermark localization process and adds an extra layer of efficiency [3]. These frequency-domain models continue to evolve, paving the way for adversarial strategies aimed at improving watermark durability.
Adversarial Training Techniques
Adversarial training takes the strengths of both waveform and spectrogram models and pushes them further by directly addressing distortive attacks. This method incorporates a discriminator network, which works to distinguish between original and watermarked audio. The embedder, in turn, is trained to produce watermarks that are both resilient and undetectable. The interaction between these two networks creates a dynamic that enhances the performance of both [3][2].
"The embedder and the discriminator form an adversarial relationship and mutually force each other during training." – Pengcheng Li et al., Ping An Technology [3]
To ensure robustness, adversarial training uses a differentiable attack layer to simulate distortions like Gaussian noise, MP3 compression, filtering, resampling, and amplitude changes. For non-differentiable attacks, such as MP3 or AAC compression, straight-through estimators are employed to maintain gradient flow. Additionally, invertible neural networks rely on "balance blocks" – trainable parameters that ensure symmetry between embedding and extraction while stabilizing the process [1][3].
However, neural compression techniques like EnCodec and Descript Audio Codec present a challenge. These methods strip away imperceptible audio details, reducing bitwise accuracy to nearly 0%, which undermines watermark integrity [4]. Despite these challenges, adversarial training continues to refine watermarking methods, setting the stage for even more resilient approaches in the future.
Training Methods for Durable and Undetectable Watermarking
Advancements in neural architectures have paved the way for training methods that make watermarks both long-lasting and hard to detect.
Loss Functions for Imperceptibility
Creating undetectable watermarks requires training neural networks that align with human auditory perception. Standard metrics like Mean Squared Error (MSE) and Mean Absolute Error (MAE) fall short because they don’t reflect how humans actually hear sound.
The introduction of Noise-to-Mask Ratio (NMR) loss has been a game-changer. By integrating psychoacoustic masking models into the training process, this method ensures that changes to audio remain below the threshold of human hearing. Essentially, it takes advantage of the way our ears naturally mask certain frequencies. In fact, MUSHRA tests showed that 93% of audio clips watermarked using NMR loss were rated as "excellent" in quality, compared to just 28% for clips trained with standard MSE loss [2].
"Models trained with NMR loss generate more transparent watermarks than models trained with the conventionally used MSE loss." – Martin Moritz, Researcher, Tampere University [2]
Modern training approaches often combine multiple loss functions. For instance, Binary Cross Entropy ensures accurate message retrieval, while NMR or adversarial loss handles imperceptibility. These are typically applied in two stages: first, focusing on making the watermark invisible and retaining message integrity, and second, simulating attacks to improve durability. The adversarial strategy uses a discriminator network to differentiate between original and watermarked audio, forcing the embedder to produce audio that sounds natural [1][2][3].
According to objective tests using the Perceptual Evaluation of Audio Quality (PEAQ) metric, 95% of audio segments watermarked with NMR-based loss received ratings between 0 ("imperceptible") and -1 ("perceptible but not annoying") [2].
To ensure these imperceptible watermarks hold up in real-world conditions, training also incorporates simulations of potential distortions, often utilizing AI tools for piracy detection to identify vulnerabilities.
Simulating Attacks During Training
Training models to withstand distortions is crucial for making watermarking systems practical. This is especially critical for high-stakes environments like watermarking for live sports streams, where speed and durability are paramount. An "attack layer" is often added between the embedder and extractor during training. This layer mimics real-world degradations like Gaussian noise, MP3/AAC compression, filtering, resampling, and time-stretching. The goal is to ensure reliable message extraction even from degraded audio signals [1][3][4].
In late 2024, researchers at Ping An Technology introduced the IDEAW (Invertible Dual-Embedding Audio Watermarking) model, which used balance blocks to counteract the asymmetry introduced by the attack layer.
"The attack layer which simulates common damages on the watermarked media is introduced into the Embedder-Extractor structure to guarantee the robustness." – Pengcheng Li et al., Ping An Technology [3]
Neural codecs, like EnCodec and Descript Audio Codec (DAC), present a unique challenge. These compression methods often strip away subtle audio details, reducing bitwise accuracy to below 50%, even when models are specifically trained to resist them [4].
"Neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions." – Yigitcan Ozer and team, Sony AI [4]
In 2025, ETH Zurich‘s Timbru model tackled this issue by simulating DAC regeneration attacks during gradient optimization. This approach significantly improved the model’s ability to withstand previously unseen neural codec attacks [1].
For non-differentiable attacks, such as MP3 or AAC compression, straight-through estimators are used to maintain gradient flow during training [1]. A Sony AI study from 2025 evaluated four major models using a pipeline of 20 real-world distortions. The study found that retraining with a "strict" attack pipeline greatly improved bitwise accuracy against challenges like polarity inversion and time jittering [4]. However, these improvements often come at the cost of lower Signal-to-Noise Ratio (SNR) values, highlighting the delicate balance required during training [2][4].
These advancements build on earlier adversarial methods, pushing watermarking resilience to new levels.
Using Neural Networks in Audio Watermarking Systems
Training neural networks to embed robust watermarks is just the first step. The real challenge lies in integrating these watermarks into systems that businesses can actually use. Neural watermarking needs to fit seamlessly into a larger content protection framework.
Integration with Content Protection Platforms
ScoreDetect offers a solution that combines invisible watermarking with automated tools for discovery, analysis, and takedown. The watermarking process embeds imperceptible identifiers into audio files, preventing unauthorized use by resisting removal attacks. Meanwhile, the platform’s web scraping technology, which boasts a 95% success rate in bypassing prevention measures, actively searches for pirated content across the internet.
The integration process uses a two-stage method. First, a lightweight "locating code" enables quick synchronization. Then, the actual message payload, containing ownership or licensing details, is embedded. This approach addresses a key issue highlighted by Pengcheng Li from Ping An Technology:
"Localization efficiency is an issue that neural audio watermarking must face" [3].
Efficient localization is crucial. Without it, systems waste valuable computational resources scanning entire audio files. For businesses in media, entertainment, and content creation, this integration means watermarked audio can be tracked automatically across distribution channels. When unauthorized use is detected, ScoreDetect can issue delisting notices with over 96% success. This smooth integration also sets the stage for verification measures using blockchain technology.
Combining Watermarking with Blockchain Technology
Embedding a watermark is only part of the equation. Verifying ownership is equally important. Blockchain technology provides an immutable layer of verification to complement neural watermarking. While the watermark identifies the content, blockchain creates a permanent record of ownership. ScoreDetect achieves this by capturing a checksum of the content and recording it on the blockchain. This method avoids the storage challenges of placing large media files directly on the chain.
This combination also addresses a major weakness in neural watermarking: overwriting attacks. Research has shown that attackers can embed fake watermarks over legitimate ones, effectively erasing the original watermark with nearly 100% success [5]. Blockchain timestamps counter this vulnerability by providing verifiable proof of ownership that predates any forged watermark. The system uses perceptual hashing instead of traditional cryptographic hashes, ensuring the blockchain record remains valid even if the audio is compressed or converted to another format.
Conclusion
Key Takeaways for Enterprises
Neural networks are transforming audio watermarking by improving both imperceptibility and robustness. By learning optimal embedding patterns and simulating real-world attacks during training, these systems outperform traditional methods. For example, models using NMR loss classify over 95% of audio segments as imperceptible or barely perceptible on the PEAQ scale, compared to just 25% for MSE-trained models [2]. This is a game-changer for industries like media, entertainment, and content creation, where audio quality directly influences user experience.
Pengcheng Li highlighted the strength of neural audio watermarking in handling diverse attacks during training [3]. These systems are designed to withstand real-world distortions, ensuring watermarks remain intact through actual distribution channels. Pairing neural watermarking with tools like ScoreDetect adds another layer of protection, enabling automated content monitoring and takedown capabilities. While these advancements mark a significant leap forward, there’s still work to be done to tackle new challenges on the horizon.
Future Directions in Audio Watermarking
The future of audio watermarking faces a critical challenge: neural codecs. As Yigitcan Ozer from Sony AI explains:
"Neural codecs will end up removing imperceptible watermarks… they compete for the same space" [4].
With streaming platforms increasingly adopting neural compression for high-fidelity audio, watermarking research is shifting toward codec-aware designs. These approaches aim to embed data within the latent space of audio models, ensuring watermarks remain intact even under advanced compression techniques.
Innovative methods like cross-attention mechanisms and post-hoc gradient optimization (e.g., Timbru) are emerging as promising alternatives. These techniques focus on per-audio optimization rather than relying on massive pre-trained models. Impressively, they achieve nearly 100% bit recovery rates against smoothing attacks without requiring a training dataset [1]. However, a 2025 study revealed that no current watermarking methods are robust enough to withstand all tested real-world distortions, including AI-induced and physical-level attacks [6]. This underscores the need for future research to address vulnerabilities like regeneration attacks, over-the-air recording, and voice conversion, which remain significant hurdles.
Neural network-driven watermarking is reshaping the field, offering businesses stronger protection and opening up new research opportunities to tackle these evolving challenges.
FAQs
How do neural networks make audio watermarks more robust against distortions?
Neural networks are transforming audio watermarking by replacing traditional signal processing techniques with end-to-end AI models. These models are designed to optimize two key aspects: making the watermark undetectable to human ears while ensuring it stays intact even after challenges like compression or added noise. By analyzing the entire audio waveform, neural networks can tackle real-world issues more effectively than older methods.
To boost the watermark’s resilience, the training process includes simulated distortions such as filtering, resampling, time-stretching, and reverberation. This helps the network learn to withstand these types of alterations, making the watermark naturally resistant to such changes. ScoreDetect takes full advantage of these advancements, offering AI-driven watermarks that remain undetectable to listeners but robust enough to survive common audio processing. This ensures reliable copyright protection for digital content in the U.S. market.
How do psychoacoustic loss functions help preserve audio quality in watermarking?
Psychoacoustic loss functions play a key role in ensuring that audio watermarking remains undetectable to listeners by taking advantage of how the human ear processes sound. These functions simulate the ear’s masking effect, focusing only on distortions that would stand out – like those surpassing the noise-to-mask ratio (NMR). This approach allows watermarking systems to embed signals in parts of the audio spectrum that are less sensitive, preserving the overall sound quality.
When deep-learning models are trained using NMR-based loss, they deliver better transparency compared to older techniques like mean-squared-error (MSE). The result? Watermarking that’s virtually “invisible” to the listener but still strong enough to resist tampering or interference.
How does adversarial training improve the resilience of audio watermarks?
Adversarial training strengthens the durability of audio watermarks by simulating various attacks during the neural network’s training phase. By exposing the system to challenges like compression, noise addition, filtering, resampling, and time-stretching, it learns to embed watermarks in parts of the audio signal that can endure these alterations.
This approach ensures the watermark stays intact and recoverable even after significant processing, such as streaming, editing, or deliberate tampering. The outcome is a resilient, invisible watermark that preserves its integrity throughout the content’s use, all without affecting the audio quality.
ScoreDetect leverages these advanced methods to produce discreet yet durable watermarks. These watermarks safeguard digital content from piracy while enabling effortless detection for verification purposes.

