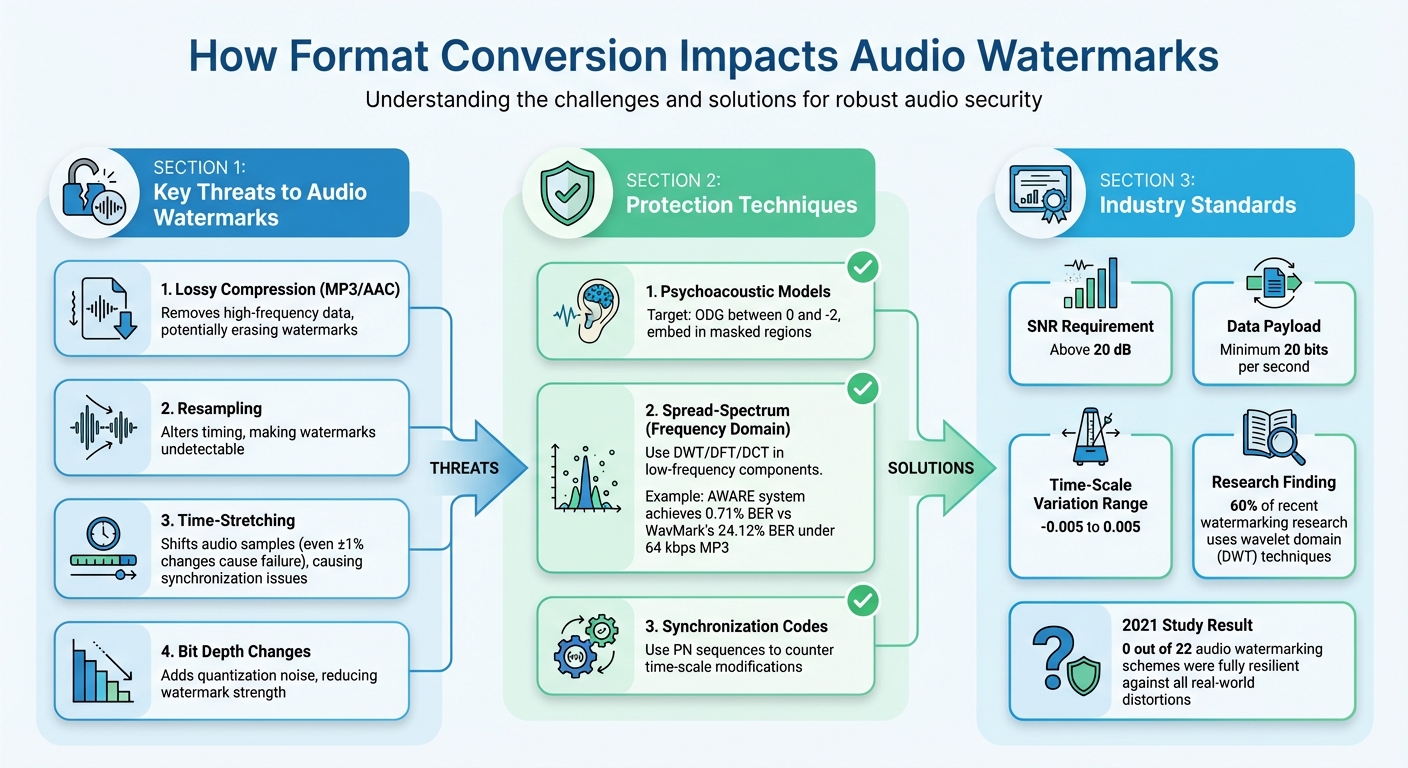
Audio watermarks protect audio files by embedding hidden signals that verify ownership and track usage. However, converting audio formats – like compressing files to MP3 or resampling – can weaken these watermarks by reducing their energy, disrupting synchronization, and introducing noise. Key challenges include:
- Lossy Compression: Removes high-frequency data, potentially erasing watermarks.
- Resampling: Alters timing, making watermarks undetectable.
- Time-Stretching: Shifts audio samples, causing synchronization issues.
- Bit Depth Changes: Adds noise, reducing watermark strength.
To counter these effects, techniques like embedding watermarks in low-frequency components, using psychoacoustic models, and applying spread-spectrum methods improve resilience. Testing watermarks under simulated conditions and leveraging tools like ScoreDetect can also ensure durability during conversions.
How Format Conversion Damages Audio Watermarks: Key Threats and Solutions
Engineer Explains Copy Proof Watermarking
How Format Conversion Damages Audio Watermarks
Converting audio formats can compromise watermarks by weakening their energy, disrupting synchronization, and distorting timing. Each of these effects poses challenges to protecting content, and understanding how they occur is key to improving watermarking techniques. Let’s break down how specific conversion processes impact watermark resilience.
Lossy Compression and Watermark Data Loss
Lossy compression formats like MP3 and AAC are designed to reduce file size by removing audio data that’s deemed less perceptible to human ears. Unfortunately, this process often eliminates high-frequency components where watermark signals may reside. As a result, the watermark’s strength decreases, sometimes to the point where it becomes unrecoverable.
This issue is particularly severe for time-domain watermarking methods such as Least Significant Bit (LSB) schemes and echo hiding, which embed data in the most delicate parts of the audio signal. These methods struggle to survive compression. To address this, the International Federation of the Phonographic Industry (IFPI) suggests that effective watermarking systems should withstand MP3 compression while maintaining a Signal-to-Noise Ratio (SNR) above 20 dB and a data payload exceeding 20 bits per second [3].
Frequency-domain techniques, which use methods like DFT, DWT, or DCT, tend to perform better. By embedding watermarks in low-frequency components that compression algorithms typically preserve, these methods offer greater resilience. However, challenges like resampling and time-scale modifications introduce further complications.
Resampling and Bit Depth Changes
Resampling, which changes the audio’s sampling rate, disrupts the timing of the watermark. This process shifts sample positions, causing detectors to lose synchronization with the watermark. While the watermark may still exist, the misalignment renders it undetectable because the timing relationship between the encoder and decoder is broken.
Bit depth changes, or re-quantization, introduce a different problem. By reducing the bit depth, quantization noise and distortion increase, effectively weakening the watermark’s energy. Unlike resampling, this process doesn’t affect alignment but can completely wash out the embedded data. Researcher Shijun Xiang highlights this issue:
"Audio processing operations (including requantization, the addition of noises, MP3 lossy compression, and low-pass filtering operations) do not cause synchronization problems, but will reduce the watermark energy" [1].
Time-Stretching and Audio Transformations
Time-stretching and time-scale modification (TSM) are among the most difficult threats to watermark durability. These transformations shift audio samples in the time domain, disrupting the index-to-time mapping that watermark detectors depend on. Even a minor adjustment – as small as ±1% – can render traditional watermarking systems ineffective [1].
During digital-to-analog (D/A) and analog-to-digital (A/D) conversions, time-scaling factors typically range between -0.005 and 0.005 [1][3]. Although these changes might seem negligible, they can immediately cause synchronization drift for sensitive watermarks. Audio edits such as splicing, selective cuts, or concatenation further complicate matters by breaking global synchronization. If watermark bits are embedded in narrow time windows without redundancy, reordering or removing frames makes it impossible to reconstruct the original message [5].
How to Create Audio Watermarks That Survive Format Conversion
Designing audio watermarks that can withstand compression, noise, and timing shifts is no small feat. By leveraging the unique characteristics of audio, it’s possible to embed watermarks that maintain both sound quality and ownership integrity, even after format conversion. These techniques aim to address earlier challenges by improving the resilience of watermarks against common audio processing.
Using Psychoacoustic Models for Watermark Embedding
Psychoacoustic models help identify areas in audio where hidden data can be embedded without being noticeable to the human ear. These models pinpoint "masked" regions – parts of the audio where changes are less likely to be heard – allowing for stronger watermark embedding. A key metric here is the Objective Difference Grade (ODG), derived from the PEAQ (Perceptual Evaluation of Audio Quality) model, which ensures the watermark remains imperceptible while maximizing its energy. Ideally, the ODG should stay between 0 and -2 [1][3].
This method adapts the watermark’s strength to the audio content. For instance, louder sections can tolerate larger changes, while quieter parts require more subtle adjustments to avoid detection. Embedding watermarks in the low-frequency sub-bands of the Discrete Wavelet Transform (DWT) is particularly effective, as these frequencies are less affected by compression.
Applying Spread-Spectrum Techniques
Spread-spectrum techniques distribute the watermark across multiple frequencies, making it more likely to survive compression and other audio processing.
Frequency-domain methods such as DWT, DFT, or DCT are more robust compared to time-domain approaches like Least Significant Bit (LSB) schemes. As researcher Shijun Xiang points out:
"The problem of audio watermarking against common audio processing operations can be solved by embedding the watermark in the frequency domain instead of in the time domain" [1].
In October 2025, researchers Kosta Pavlović and his team introduced the AWARE system, which utilizes adversarial optimization in the time-frequency domain. Testing on VCTK and LibriSpeech datasets at 16 bits per second revealed a 0.71% Bit Error Rate (BER) under 64 kbps MP3 compression, outperforming systems like WavMark, which had a 24.12% BER [5]. Customizing the embedding strategy can further enhance performance for specific audio formats.
Tailoring Watermarks for Specific Audio Formats
Different audio formats require unique approaches to embedding watermarks. For formats like MP3 and AAC, which rely on lossy compression, embedding watermarks in the lowest-frequency coefficients is key. These frequencies are preserved during compression, as high-frequency components are typically the first to be discarded [1][3].
Relation-based watermarking offers another solution by focusing on the energy relationships between groups of DWT coefficients rather than their absolute values. This technique is particularly effective against volume changes and amplitude adjustments that often occur during format conversion [1][3]. Additionally, incorporating synchronization codes with pseudo-random noise (PN) sequences helps counter time-scale modifications. These codes allow watermark detectors to locate the watermark and adjust for scaling factors, even after resampling or time-stretching alters the sample positions [1][3].
The International Federation of the Phonographic Industry (IFPI) suggests maintaining a data payload of at least 20 bits per second to ensure watermarks can resist MP3 compression and resampling [3].
sbb-itb-738ac1e
Steps to Prevent Watermark Loss During Format Conversion
To address the challenges of maintaining watermarks during format conversion, there are several strategies you can use. These include rigorous testing, leveraging advanced digital tools, and implementing automated workflows to ensure watermark durability and integrity.
Testing Watermarks Through Simulated Conversions
Before deploying watermarks in real-world scenarios, it’s crucial to test them under conditions that mimic actual format conversions. Start by simulating analog-to-digital (A/D) and digital-to-analog (D/A) conversions, as these processes often introduce issues like volume changes, noise, and time-scale modifications. A simple way to test for hardware distortions is by performing a loopback test – connecting your sound card’s "Line-out" to "Line-in" with a physical cable [1].
You should also test watermarks across standard sampling rates to evaluate how they hold up against various distortions. These distortions generally fall into three categories:
- Signal-level distortions: Examples include MP3 compression, added noise, and low-pass filtering.
- Physical-level distortions: These occur during re-recording through microphones.
- AI-induced distortions: Such as those caused by voice conversion models [6].
To measure the impact on audio quality, use the Perceptual Evaluation of Audio Quality (PEAQ) model. Aim for an Objective Difference Grade (ODG) between 0 and -2, which ensures the watermark remains imperceptible while maintaining its strength [3]. However, a 2021 study revealed that none of the 22 audio watermarking schemes tested were fully resilient against all real-world distortions [6]. This underscores the importance of thorough testing before deployment.
Using Digital Protection Tools for Watermark Management
Tools like ScoreDetect offer a robust solution for embedding and managing watermarks. This tool combines invisible watermarking with blockchain-based checksums, providing verifiable proof of ownership without altering the audio quality. Blockchain technology stores a checksum of your content, ensuring ownership verification without needing to store the actual files.
ScoreDetect also employs resynchronization techniques to address time-scale shifts that occur during format conversions. These synchronization codes calculate scaling factors and adjust watermark positions automatically, ensuring successful extraction [1]. The system maintains an SNR above 20 dB and supports a data payload capacity exceeding 20 bits per second [3].
Additionally, ScoreDetect embeds watermarks in low-frequency sub-bands, which are more likely to survive lossy compression. Tests using Audiowmark, an open-source tool, demonstrated that watermark strength settings up to 30 preserved perceptual quality while achieving 100% recovery rates, even in noisy conditions [7].
Setting Up Automated Content Monitoring Workflows
In today’s fast-paced audio distribution landscape, manual watermark verification is impractical. Automated monitoring systems are essential for keeping track of embedded watermarks across large volumes of content. Tools like ScoreDetect integrate seamlessly with over 6,000 web apps via Zapier, enabling automated workflows that monitor, detect, and enforce watermark integrity. For example, these workflows can trigger actions when unauthorized use is detected. ScoreDetect’s intelligent web scraping achieves a 95% success rate in bypassing preventive measures, while automated takedown notices maintain a 96% success rate.
Blind detection algorithms, which don’t require the original file for verification, further streamline automated monitoring [2]. These systems can correct distortions, such as time scaling variations (typically ranging between -0.005 and 0.005), before extracting watermarks [1].
For content creators and media companies, automated broadcast monitoring offers additional benefits. It tracks usage, identifies unauthorized broadcasts, and facilitates billing or statistical analysis [2]. By continuously checking watermark integrity, these workflows provide immediate alerts when degradation occurs, allowing you to address issues before they escalate into copyright disputes.
Conclusion
This article explored how format conversion challenges the integrity of watermarks and highlighted methods to address these issues effectively.
Key Takeaways on Format Conversion and Watermark Protection
Format conversion can compromise watermark integrity through volume distortion, added noise, and time-scale modifications (TSM) [1][3]. TSM, in particular, disrupts synchronization, making embedded watermarks difficult to detect [1][3]. Techniques like lossy compression, re-sampling, and low-pass filtering further weaken the watermark by reducing its energy [1][4].
To preserve watermark durability, it’s essential to balance imperceptibility, robustness, and capacity – commonly referred to as the "magic triangle" [2]. Embedding watermarks in frequency or wavelet domains, rather than the time domain, has proven more effective against the degradation caused by format conversion. In fact, about 60% of recent watermarking research relies on wavelet domain techniques (DWT) for this reason [2]. Additionally, synchronization codes and maintaining a signal-to-noise ratio above 20 dB play a critical role in ensuring the watermark remains both invisible and recoverable after conversion [3].
A 2021 study analyzing 22 audio watermarking methods revealed that none were fully resistant to all tested distortions [6]. This finding highlights the need for rigorous testing using simulated conversions and automated monitoring systems. These insights pave the way for more advanced tools to protect audio content effectively.
How ScoreDetect Safeguards Audio Content
Given the challenges of format conversion, practical solutions are vital. ScoreDetect addresses these issues with invisible watermarking and blockchain-based verification. By embedding watermarks in low-frequency sub-bands – areas more likely to retain integrity during lossy compression – and employing resynchronization techniques to correct timing shifts, ScoreDetect ensures successful watermark extraction even after multiple conversions.
The platform’s automated monitoring system connects with over 6,000 Zapier-integrated apps, enabling continuous watermark verification. With a 96% success rate in detecting unauthorized usage and sending automated takedown notices, ScoreDetect offers content creators in media, entertainment, and digital business sectors a reliable, end-to-end solution for protecting their audio assets in today’s digital landscape.
FAQs
How can I protect my audio watermarks during format conversion or compression?
To protect your audio watermarks during lossy compression or format conversion, it’s important to rely on techniques built to withstand these processes. One effective method is embedding watermarks into the lower-frequency components of audio, as these frequencies are less affected by compression. Another approach involves adaptive embedding, where the watermark’s strength is adjusted based on the audio content, balancing durability and audio quality.
For stronger protection, explore advanced tools that use synchronization codes and interpolation. These features help safeguard watermark integrity against challenges like time-scale changes and compression artifacts. Together, these methods not only secure your digital audio but also ensure the watermark remains hidden from unauthorized access.
How can I keep audio watermarks intact after resampling?
To keep an audio watermark in sync after resampling, one option is to use synchronization codes alongside interpolation methods. This combination helps adapt to shifts in playback speed or sampling rates, ensuring the watermark aligns with the modified audio signal.
Another approach is relation-based watermarking, which works by embedding the watermark using the energy relationships among groups of Discrete Wavelet Transform (DWT) coefficients. This method makes the watermark more resistant to changes like volume adjustments or noise that might occur during resampling.
Using these strategies together can help the watermark stay intact and detectable, even after common audio processing tweaks.
How do psychoacoustic models make audio watermarks more resilient?
Psychoacoustic models make audio watermarks tougher to tamper with by embedding them in parts of the audio signal that the human ear is less likely to notice and that are less prone to distortion. These models tap into the way our auditory system processes sound, strategically placing watermarks where they’re harder to detect or alter.
By focusing on less perceptible elements – like certain frequencies or time intervals where hearing sensitivity is lower – psychoacoustic models help watermarks survive challenges such as format changes, compression, or filtering. This method keeps the watermark intact and dependable, even when the audio undergoes significant processing.

