Copyright enforcement is harder than ever. Why? Because digital piracy now spans multiple formats – text, images, audio, and video. A single book can appear as a scanned PDF, a cropped image, or even an audio readout. Traditional detection tools, which focus on one format at a time, can’t keep up with this level of transformation.
The solution? Multimodal matching. This AI-driven approach identifies altered copyrighted content across formats by analyzing images, videos, audio, and text simultaneously. It works even when content is cropped, pitch-shifted, paraphrased, or otherwise modified to evade detection.
Key Points:
- Why traditional methods fail: Single-format tools miss cross-format piracy and struggle with large-scale databases.
- How multimodal matching works: AI creates fingerprints for content, enabling detection of altered material across various formats.
- Scalability: Advanced techniques like Approximate Nearest Neighbor (ANN) search handle billions of assets with sub-second response times.
- Practical benefits: Reduces false positives, consolidates related alerts, and provides legally defensible evidence for enforcement.
This approach is already helping rights holders tackle piracy at scale while improving efficiency and accuracy.
Copyright Enforcement Challenges Across Multiple Content Types
Why Single-Format Detection Methods Fall Short
Traditional detection tools that focus solely on images, text, or audio fail to track copyrighted content distributed across multiple formats. Each type of content comes with its own set of evasion tactics: images are cropped, filtered, or posted at lower resolutions; videos are altered by speeding up, slowing down, or clipping into shorter segments; audio files are manipulated with pitch changes, tempo adjustments, or layered with background noise; and text is paraphrased, translated, or reformatted [1]. Systems designed to handle just one of these transformations often miss the rest, leaving gaps that infringers can exploit.
"A single pirated book can appear in dozens of formats, scanned PDFs, text pasted into forums, cropped images of pages, or audio readouts." – Nikhil John, InCyan [1]
The issue becomes even more complex with semantic disconnects. Tools like CLIP or BLIP2, which attempt to align text with images, often struggle when captions and visuals have minimal semantic overlap [4]. For example, a system that evaluates text and images separately might miss instances where they are combined to distribute copyrighted content.
On top of these challenges, the sheer volume of content being uploaded daily overwhelms traditional detection systems.
The Growing Scale of Digital Piracy
Major social media and video-sharing platforms now handle hundreds of millions of uploads daily [2]. Music catalogs contain tens of millions of tracks, many of which appear in remixes or user-generated content [2]. What used to be considered a "large" database – one million fingerprints – is now dwarfed by the billion-scale searches required in today’s environments [2].
This massive scale introduces serious challenges. At billions of entries, brute-force fingerprint scanning becomes computationally unfeasible [2].
"A design that works comfortably for a million assets can fail outright at a billion. Memory consumption explodes. Index build times stretch from hours to weeks." – Nikhil John, InCyan [2]
Linear search methods simply can’t keep up with the internet’s pace. Manual reviews of millions of alerts are impractical, so enforcement teams need systems that can group related instances – like a scanned PDF, a forum post, and a cropped image – into a single actionable "incident" [1]. Without this kind of cross-platform clustering, rights holders are buried under irrelevant alerts while piracy continues unchecked.
sbb-itb-738ac1e
AI Music Creators Will Be EXPOSED
How Multimodal Matching Solves Copyright Detection Problems
When it comes to copyright detection, relying on single-format tools often falls short. Multimodal matching steps in to tackle these limitations by analyzing multiple content types simultaneously. Instead of comparing files bit-by-bit, advanced AI models create compact vectors that group similar content together – even when that content has been altered. For example, a cropped image, a pitch-shifted audio clip, or a paraphrased text excerpt can all be identified as originating from the same source, even after substantial changes [2].
This system works by using modality-specific analysis, which is tailored to the ways different types of content are typically modified:
- Images: Models detect elements like logos, visual motifs, and layout patterns that remain recognizable after cropping, filters, or collages [1].
- Videos: By aligning temporal segments and combining frame sampling with audio fingerprinting, the system catches partial copies – even if the playback speed or aspect ratio has been altered [1].
- Audio: Detection methods handle pitch shifts, tempo changes, and background noise to identify short clips like song hooks [1].
- Text: Tools use semantic similarity and Named Entity Recognition (NER) to flag copyrighted material, even when it’s paraphrased or translated [1].
One of the standout features of this approach is its ability to operate at massive scale. Traditional methods would take about 12 days to search one billion assets on a single CPU core [2]. Multimodal systems, however, use Approximate Nearest Neighbor (ANN) search with graph-based structures like Hierarchical Navigable Small World (HNSW) graphs. This allows for sublinear search complexity – essentially, doubling the database size only adds a small, fixed amount of processing time per query [2]. This scalability makes it possible to handle enormous volumes of content efficiently.
The Technical Process Behind Multimodal Matching
The process starts with neural fingerprinting, which converts each asset into a compact vector. These fingerprints are typically 512-dimensional float vectors. However, storing such data at scale requires terabytes of memory [2]. To address this, systems use Product Quantization (PQ) to compress vectors into shorter codes, enabling large indexes to stay in memory and deliver results with sub-second latency [2].
The search itself follows a multi-stage pipeline for maximum efficiency:
- Coarse filtering: Techniques like Locality Sensitive Hashing quickly generate initial candidate matches [2].
- Precise re-ranking: High-precision vectors are used to verify matches during this stage [2].
- GPU acceleration: This speeds up vector comparisons, making real-time screening possible, even on platforms with hundreds of millions of daily uploads [2].
To tie it all together, cross-platform clustering groups near-duplicates and derivatives into unified "incidents" [1]. For instance, if a pirated book appears in various formats across multiple platforms, the system links these occurrences into a single case. This reduces thousands of alerts into manageable, actionable cases for enforcement teams [1].
Benefits of Multimodal Matching
The benefits of multimodal matching become clear when considering its practical applications. The most obvious advantage is its ability to handle modifications that would defeat single-format tools. Whether content is cropped, filtered, compressed, or translated, multimodal fingerprints retain their effectiveness [1]. Even fragments of original content can be matched accurately.
Another key benefit is reduced reviewer fatigue. Instead of sifting through thousands of nearly identical alerts, reviewers work on consolidated cases that include all related evidence [1]. With false positive rates kept between 5% and 15%, reviewers can focus on genuine infringements [1].
Additionally, the system introduces risk-aware scoring, which combines AI confidence levels with contextual factors like asset value, jurisdiction, and audience size. This ensures that the most critical cases get immediate attention, while lower-priority cases are addressed later [1].
"Accuracy without scale delivers impressive demos that collapse under production volume." – Nikhil John, InCyan [2]
For legal purposes, multimodal systems provide capture artifacts such as screenshots, HTML snapshots, or media clips. These artifacts create a reproducible chain of custody, ensuring that detections hold up in court [1]. By tracking transformations across formats and providing high-quality evidence, multimodal matching has become an essential tool for comprehensive copyright protection in today’s digital world.
InCyan‘s Idem: Multimodal Matching Platform
InCyan’s Idem serves as the backbone of a robust copyright enforcement system. Using AI-driven fingerprinting, this platform links observed content usage back to its original source, handling a staggering scale of a billion assets. What sets Idem apart is its ability to achieve 99% identification accuracy with response times under a second – without the heavy computational demands of traditional methods [5].
Idem’s Core Capabilities
Idem’s standout feature is its evasion-proof technology, which detects content even after significant alterations. It can identify material where only 10% of the original remains [5]. This adaptability spans all types of media:
- Images remain identifiable despite cropping or filters.
- Videos are detected even with speed or aspect ratio changes.
- Audio clips are recognized despite pitch adjustments.
- Text matches even when paraphrased or translated.
The platform uses specialized models to create compact fingerprints, mapping similar content to nearby points in a high-dimensional space. This approach focuses on similarity detection rather than exact matches. To handle the demands of enterprise-scale operations, Idem employs Approximate Nearest Neighbor (ANN) search with cutting-edge techniques like Hierarchical Navigable Small World (HNSW) graphs, Product Quantization (PQ) for compressing vectors, and GPU acceleration. These technologies allow it to process millions of events daily while maintaining latency in the range of tens to low hundreds of milliseconds [2].
How Idem Works with Other InCyan Tools
Idem’s advanced capabilities are amplified when integrated with other AI tools for piracy detection, creating a seamless copyright protection workflow. For instance, when combined with Tectus, InCyan’s invisible watermarking solution, Idem can detect and verify embedded signals even after content transformations. As Nikhil John from InCyan highlights:
"Properly designed invisible watermarks can survive transformations and act as a latent serial number for the work itself" [3].
Idem’s blind detection feature allows it to identify ownership signals in suspect assets without needing the unmarked original file [3].
The platform also pairs with ScoreDetect to provide how blockchain enhances digital watermarking and copyright proof. This integration strengthens InCyan’s end-to-end enforcement system by logging Idem’s matching data and identification results on cryptographically secure ledgers. These records form a tamper-evident audit trail that supports legal enforcement [3]. Every detection event is meticulously documented with cryptographic hashes and versioned results, ensuring a reliable chain of custody for court proceedings [3].
How to Implement Multimodal Matching for Copyright Enforcement
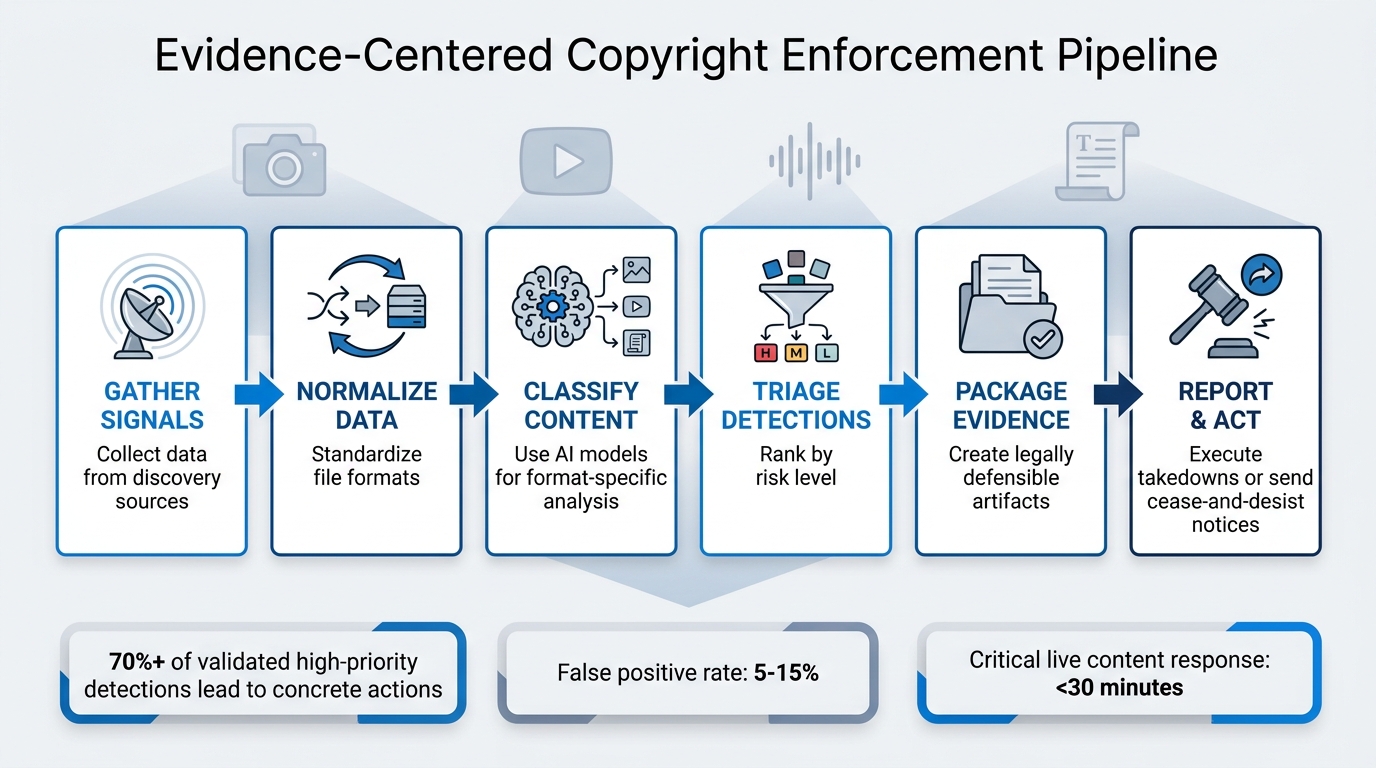
6-Step Multimodal Copyright Enforcement Pipeline
Implementing multimodal matching turns raw detection signals into actionable copyright enforcement steps. At the heart of this process is what InCyan refers to as an evidence-centered operating model. This approach ensures that all data flows through a structured framework, creating a traceable path from detection to takedown [1].
The process follows a six-step pipeline designed to handle all types of content formats:
- Gather signals from various discovery sources
- Normalize data by standardizing file formats
- Classify content using AI models tailored to specific formats
- Triage detections by risk level
- Package evidence into legally defensible artifacts
- Report and act – either executing takedowns or sending cease-and-desist notices [1]
This system ensures that specialized detection models handle each type of content, whether it’s a cropped logo, a pitch-shifted audio file, or a paraphrased article, while maintaining a unified enforcement process.
A key feature of this approach is incident clustering, which consolidates related detections into a single case. For example, if a pirated eBook appears as a PDF on one platform (which can be protected with invisible watermarks), as text snippets on another, and as an audio reading elsewhere, the system groups them into one incident [1]. This reduces reviewer fatigue and provides a clearer picture of infringement scale. The most effective systems achieve a high enforcement success rate, with at least 70% of validated high-priority detections leading to concrete actions [1].
Setting Up Automated Copyright Protection Workflows
Establishing this system can be done over a 90-day timeline, broken into distinct phases. The first week focuses on defining the program’s goals and success metrics. Over the next two weeks, teams create a prioritized inventory of assets and map discovery sources across platforms like websites, social media, and peer-to-peer networks. By week five, technical teams set up API integrations and implement data schemas to connect assets, usage data, and evidence artifacts. A pilot launch occurs in week nine, allowing teams to fine-tune confidence thresholds based on real-world results [1].
ScoreDetect plays an essential role in this workflow by offering blockchain-based proof of ownership, which strengthens the evidence package. When Idem detects a match, ScoreDetect timestamps the event using cryptographic hashes, creating a tamper-proof audit trail. For businesses using WordPress, the ScoreDetect plugin automatically tracks every published or updated article, producing ownership records to support enforcement actions.
Automation can be extended further with Zapier, which integrates ScoreDetect with over 6,000 web applications. This enables custom workflows, such as automatically generating takedown notices for high-confidence matches flagged by Idem or routing medium-confidence cases to reviewers through project management tools. These integrations, combined with InCyan’s suite of tools, ensure that every detection – from Idem’s multimodal matching to ScoreDetect’s blockchain timestamps – fits seamlessly into a unified enforcement strategy. The system operates within defined service level agreements, such as responding to critical live content within 30 minutes and addressing lower-priority cases by the next business day, all while maintaining a false positive rate between 5% and 15% [1].
| Phase | Timeline | Key Activities | Tools Used |
|---|---|---|---|
| Strategy | Weeks 1–2 | Define goals, compile asset inventory, map sources | ScoreDetect (ownership proof), Idem (fingerprinting) |
| Setup | Weeks 3–5 | Configure APIs, implement data schemas, secure storage | ScoreDetect (blockchain timestamps), Zapier (automation) |
| Configuration | Weeks 6–8 | Enable modality-specific models, set thresholds, design triage | Idem (classification), Tectus (watermarking) |
| Execution | Weeks 9–11 | Launch pilot, refine thresholds, establish dashboards | ScoreDetect (logging), Indago (enforcement) |
| Governance | Weeks 12–13 | Review performance, plan scaling, schedule reviews | Full InCyan suite integration |
Case Examples of Multimodal Matching in Action
With the technical framework in place, real-world applications highlight the system’s effectiveness across various content types.
Media companies managing large content libraries use risk-based prioritization to combine machine confidence scores with business context. For example, detections are evaluated based on factors such as the asset’s commercial value, the size of the infringing platform’s audience, and the jurisdiction where the infringement occurs [1]. High-value assets on high-traffic platforms receive immediate attention, while lower-priority cases are batched for processing during off-peak hours.
Publishing houses protecting text-based intellectual property use human-in-the-loop calibration to refine their automated systems. Edge cases are routed to experienced reviewers, who provide structured feedback to improve model accuracy. This ensures that critical decisions, like issuing DMCA notices, are informed by human judgment [1].
The evidence packaging step is essential for legal enforcement. Each detection bundle includes artifacts like screenshots, HTML snapshots, and media samples, along with protocol logs documenting how and when the content was accessed [1]. This approach ensures a complete chain of custody, enabling organizations to present defensible evidence in court or during disputes with platforms. By unifying detection and reporting, the system eliminates redundant efforts and prevents coverage gaps.
Conclusion
Copyright enforcement has become increasingly complex, requiring solutions that can handle massive amounts of content across multiple media types. As Nikhil John from InCyan puts it:
"Scale is not an optional optimisation. It is a defining constraint. Any credible content identification strategy must treat billion-scale search as the default, not as a future upgrade." [2]
Organizations safeguarding their digital assets need tools that are versatile and capable of handling high volumes without breaking down.
Idem addresses these challenges with its advanced identification capabilities, able to detect ownership even when only 10% of the original content remains after being altered. Paired with ScoreDetect, businesses benefit from tamper-proof ownership records created through cryptographic hashes. These records simplify the process of building strong evidence chains, making legal tools for combating digital piracy more effective and defensible.
The shift toward evidence-based models enhances enforcement by converting raw detection data into actionable intelligence. Instead of chasing individual URLs, multimodal matching groups related infringements into cohesive incidents. This approach not only reduces reviewer fatigue but also provides a clearer view of piracy across platforms like websites, social media, and peer-to-peer networks [1]. With false positives limited to just 5%-15%, enforcement efforts can focus on genuine threats [1]. These advancements integrate seamlessly with InCyan’s tools, creating a unified and efficient enforcement strategy.
For businesses managing extensive content libraries – whether in media, publishing, or other industries – InCyan’s multimodal matching platform, combined with ScoreDetect’s verification system, offers a comprehensive solution. The platform handles billion-scale databases with sub-second query speeds, and integrations like Zapier and WordPress enable even smaller teams to access enterprise-level copyright enforcement, maintaining both speed and accuracy.
FAQs
What is multimodal matching?
Multimodal matching is a process used to identify and verify digital content across different media formats, including images, videos, and audio. By leveraging advanced AI, it can pinpoint ownership or detect unauthorized use, even if the content has been altered through cropping, compression, or editing. This method plays a key role in copyright enforcement, making it possible to track and address infringements across various platforms while safeguarding digital assets.
How does it detect heavily altered content?
ScoreDetect leverages cutting-edge multimodal matching techniques to pinpoint content ownership, even when the material has undergone extensive changes like cropping, compression, mobile edits, or meme-style tweaks. Its proprietary AI-driven algorithms work across multiple content types – images, audio, and video – at the same time. Impressively, it can identify infringing content even if just 10% of the original asset is intact. This powerful system maintains accuracy, even with heavy edits or format transformations.
What do I need to implement it at scale?
To use ScoreDetect on a large scale, you’ll need a solid infrastructure that can handle billions of digital assets. This means incorporating tools like high-dimensional indexing, distributed systems, and AI-powered content matching to maintain both precision and efficiency. Adding blockchain-based timestamping strengthens security, while automation workflows streamline operations for managing massive amounts of data. It’s also crucial to regularly fine-tune the system – whether that’s updating algorithms or expanding infrastructure – to keep up with increasing content demands and ever-changing piracy methods.

