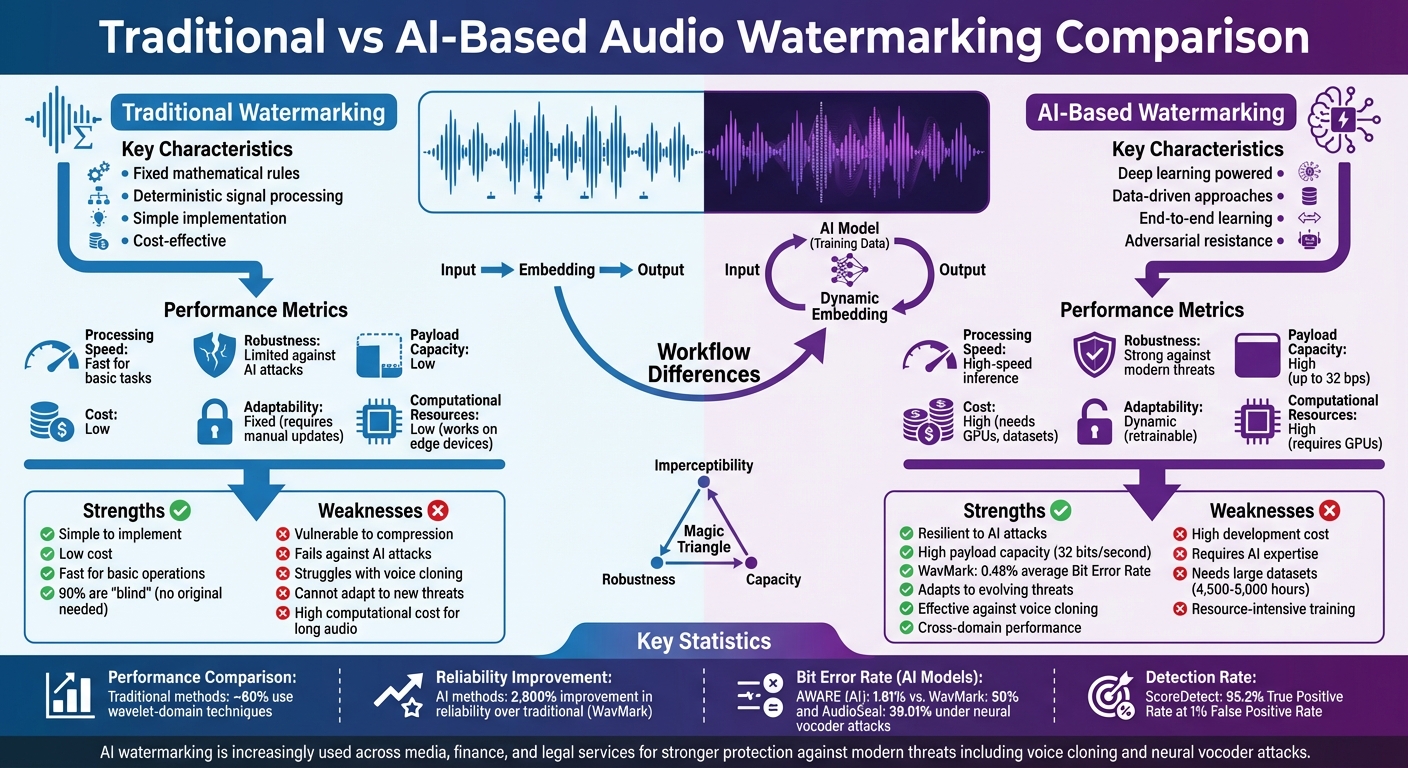
Audio watermarking embeds hidden markers in audio files to protect copyright, verify ownership, and deter piracy. Traditional methods like Least Significant Bit (LSB), echo hiding, and frequency-domain techniques rely on fixed mathematical rules but struggle against modern challenges like AI-driven audio manipulation and compression. Meanwhile, AI-based watermarking uses deep learning to create adaptive, resilient watermarks that can withstand advanced attacks, including neural vocoder resynthesis and voice cloning.
Key differences include:
- Traditional methods: Simple, cost-effective, but vulnerable to AI attacks and compression.
- AI-based methods: Resilient, scalable, and effective against modern threats but require significant computational resources.
Quick Comparison:
| Feature | Traditional Watermarking | AI-Based Watermarking |
|---|---|---|
| Processing Speed | Fast for basic tasks | High-speed inference |
| Robustness | Limited against AI attacks | Strong against modern threats |
| Payload Capacity | Low | High (up to 32 bps) |
| Cost | Low | High (needs GPUs, datasets) |
AI watermarking is increasingly used across industries like media, finance, and legal services, offering stronger protection for audio assets. Platforms like ScoreDetect combine AI with blockchain for secure, scalable solutions, ensuring content integrity even against aggressive tampering.
Traditional vs AI-Based Audio Watermarking: Key Differences Comparison
AI Music Copyright: The Watermarking Solution Explained
What Is Traditional Audio Watermarking?
Traditional audio watermarking uses deterministic signal processing techniques to embed information directly into audio files. This process integrates watermark data into the audio waveform, making it difficult to remove without degrading the sound quality.
While copyright protection is a primary goal, traditional watermarking also supports other functions, including proving ownership, verifying authenticity, managing content, monitoring broadcasts for billing purposes, and enabling second-screen services[1][2].
One of the biggest challenges in traditional watermarking is balancing the "magic triangle" – a trade-off between imperceptibility, robustness, and capacity. As Carlos Jair Santin-Cruz puts it:
"The trade-offs between imperceptibility, robustness, and capacity… are known as ‘the magic triangle’ because improving one performance criterion harms the other two" [1].
For example, making a watermark more resistant to attacks often makes it more noticeable, while embedding more data can reduce both its imperceptibility and its ability to withstand manipulation. Interestingly, about 60% of recent research focuses on wavelet-domain techniques to address these trade-offs[1].
Common Traditional Audio Watermarking Methods
Traditional watermarking methods can be categorized based on how they embed information into the audio signal:
- Time-domain methods: These modify audio samples directly. For instance, Least Significant Bit (LSB) replaces the lowest-order bits of digital samples with watermark data. While simple, this method is highly vulnerable to compression – basic MP3 encoding can easily destroy the watermark. Another approach, echo hiding, introduces tiny, imperceptible delays into the audio signal, with the delay representing the bit value. However, this method struggles with alterations like pitch shifting or tempo changes.
- Frequency-domain techniques: These transform the audio signal using mathematical methods. The Discrete Cosine Transform (DCT) embeds watermarks in mid-frequency coefficients to balance robustness and imperceptibility, while the Discrete Wavelet Transform (DWT) places watermarks in sub-band coefficients, making them more resistant to compression. The Discrete Fourier Transform (DFT) modifies the phase or magnitude spectrum to embed data.
- Spread-spectrum techniques: These distribute the watermark across a wide frequency range using a pseudo-noise sequence. While this makes the watermark harder to detect or remove, it requires more computational power.
- Quantization-based methods: Techniques like Quantization Index Modulation (QIM) map the audio signal to specific quantized levels. A variation, Rational Dither Modulation (RDM), adjusts the quantization step recursively to improve robustness. However, both methods are sensitive to gain scaling attacks.
- Matrix decomposition techniques: Methods like Singular Value Decomposition (SVD) break the audio into matrices and embed watermarks in the singular values. These watermarks are stable under common transformations but come with high computational demands.
Here’s a quick comparison of these methods:
| Technique | Domain | Method | Limitation |
|---|---|---|---|
| LSB | Time | Replaces low-order bits of samples | Easily removed by compression or noise |
| Echo Hiding | Time | Adds short, imperceptible delays | Vulnerable to pitch or tempo changes |
| DCT | Frequency | Modifies cosine coefficients | Can introduce audible artifacts if overused |
| DWT | Wavelet | Modifies sub-band coefficients | High computational complexity |
| QIM | Quantization | Maps signal to quantized levels | Sensitive to gain scaling attacks |
| SVD | Matrix | Modifies singular values | High mathematical overhead |
Each of these methods has its strengths but also comes with specific vulnerabilities.
Limitations of Traditional Methods
Despite their utility, traditional audio watermarking methods face several challenges, especially in the face of modern piracy and technological advancements. The most persistent issue is the magic triangle trade-off, where improving one aspect – like robustness – often compromises imperceptibility or capacity.
Signal-level distortions such as MP3 compression, noise addition, and low-pass filtering can severely degrade or erase watermarks[2]. Techniques like pitch shifting, time stretching, and equalization further complicate detection[4]. Physical-level attacks, where audio is played through speakers and re-recorded, introduce environmental noise and reverberation, further reducing watermark integrity[2].
A more recent threat comes from AI-driven compression tools. Neural codecs like Encodec and Descript Audio Codec are designed to discard perceptually irrelevant information to save space, which is often where traditional watermarks reside[7]. Because these watermarks are typically added as low-magnitude perturbations (at signal-to-noise ratios of 20–30 dB), they are particularly vulnerable to modern AI-based signal processing. Benchmarks show that neural codecs and denoisers can suppress watermark detection rates to nearly zero[7].
Another issue is scalability. Traditional methods often struggle to process large volumes of audio simultaneously, as each file requires specific, resource-intensive processing. Frequency-domain and matrix decomposition techniques, in particular, can become impractical for large-scale applications, limiting their use in enterprise-level content protection.
These challenges underscore the growing need for more advanced, AI-driven approaches to audio watermarking.
How AI Changes Audio Watermarking
AI is transforming audio watermarking by shifting from manual signal-processing rules to data-driven approaches. Modern systems leverage deep neural networks (DNNs) to learn both embedding and detection directly from large audio datasets[5]. This allows watermarks to evolve with new threats without requiring a complete overhaul.
One of the most important advancements is end-to-end learning, where embedding and detection systems are trained together. This creates watermarks designed for practical, real-world scenarios rather than just theoretical ones. Patrick O’Reilly from Northwestern University highlights this shift:
"Deep neural network-based watermarking methods outperform signal-processing methods in their ability to embed human-imperceptible signatures that remain detectable when watermarked audio is transformed"[7].
Another breakthrough is adversarial resistance. Techniques like AWARE (Audio Watermarking via Adversarial Resistance to Edits) use adversarial optimization to create watermarks that consider both human hearing and signal structure[6]. By embedding stronger signals in louder sections of audio, these systems ensure the watermark remains hidden yet resilient, avoiding uniform modifications across the entire file.
AI also addresses a major flaw in older methods: temporal robustness. Traditional watermarks often fail when audio is edited. AI-driven detectors, using tools like the Bitwise Readout Head (BRH), can analyze evidence across the signal, making them time-order-agnostic. This ensures watermarks remain detectable even if the audio is chopped or rearranged[6]. These advancements pave the way for more reliable and adaptive watermarking.
AI Techniques Used in Audio Watermarking
AI-powered watermarking relies on specialized techniques that deliver robust, imperceptible signatures.
- Invertible Neural Networks (INN) are central to systems like WavMark. These networks enable joint training for embedding and detection, supporting high-capacity payloads – up to 32 bits per second – that can withstand common signal-processing attacks[3]. The "invertible" design ensures the network can both hide and extract data using reversible operations.
- Hybrid-domain processing combines time and frequency features, often using Mel-spectrograms to create more durable signatures. This approach integrates perceptual insights into the watermarking process, improving resilience.
- Collaborative synthesis embeds watermarks directly into neural vocoders during audio creation. This makes the watermark part of the synthesis process, making removal nearly impossible without damaging the audio quality[6][7].
- Bitwise Readout Heads allow reliable decoding even when audio is altered through cuts, splicing, or desynchronization. By aggregating evidence across time, these detectors ensure detection without requiring precise synchronization[6].
Together, these techniques produce watermarks that are robust, adaptable, and imperceptible.
Advantages of AI in Audio Watermarking
AI brings a host of advantages to audio watermarking, making it far more effective than traditional methods.
- Enhanced Reliability: Systems like WavMark achieve an average Bit Error Rate (BER) of 0.48% across ten common attacks, a dramatic improvement – over 2,800% better than earlier state-of-the-art tools[3].
- Improved Imperceptibility: AI systems learn from data to optimize perceptual budgets, embedding stronger signals in louder sections of audio where they remain undetectable to human ears. This dynamic adjustment balances robustness, imperceptibility, and capacity.
- Resistance to AI-Generated Content: As AI-generated audio becomes more common, traditional watermarks often fail against transformations like voice cloning or neural vocoders. AI-based watermarks are specifically designed to survive these challenges. Kosta Pavlović from DeepMark explains:
"Watermarking has re-emerged as a practical mechanism to label both synthetic and authentic content to support provenance, traceability, and downstream moderation"[6].
- Scalability Across Domains: AI systems like AudioSeal and WavMark generalize well across various audio types – speech, music, and environmental sounds – even when trained primarily on one domain[5]. This cross-domain performance simplifies content protection for diverse libraries.
Perhaps the most critical advantage is adaptability. Traditional watermarks rely on fixed rules that quickly become obsolete as new attack methods emerge. AI systems, however, can be retrained to counter evolving threats, including AI-driven removal techniques. Yizhu Wen and colleagues from the University of Hawaii underline this adaptability:
"AI-based watermarking offers a more adaptable and flexible solution to watermark design… providing higher resilience against advanced AI-based detection and removal techniques than traditional methods"[2].
Traditional vs. AI-Based Audio Watermarking
When it comes to safeguarding audio content, businesses often weigh the pros and cons of traditional watermarking methods against newer AI-based approaches. Performance, speed, and scalability are key factors in this comparison.
Efficiency, Accuracy, and Scalability Comparison
Traditional audio watermarking relies on deterministic signal processing – essentially, fixed mathematical rules to embed data into audio. Techniques like LSB (Least Significant Bit) and echo hiding are straightforward and computationally light, but they stumble when dealing with long audio files or real-time requirements. As highlighted in a study:
"The main weakness of these [traditional transform-domain] systems is their high computational cost, especially for long-duration audio signals. Therefore, they are not desirable for real-time security applications where speed is a critical factor." – Scientific Reports [8]
AI-based watermarking, on the other hand, employs deep neural networks to devise embedding strategies by analyzing massive datasets. For instance, tools like AudioSeal and WavMark were trained on 4,500 to 5,000 hours of audio data [5]. While training these models is resource-intensive, their ability to process audio quickly and adapt to new threats gives them a distinct edge.
AI methods also tackle the "magic triangle" problem – balancing fidelity, robustness, and payload capacity – by learning patterns that allow for complex watermark embedding without compromising audio quality. For example, WavMark achieves a payload capacity of 32 bits per second with an average Bit Error Rate of just 0.48% under common attack scenarios, a leap forward compared to older methods [3].
Scalability is another dividing line. Traditional systems often struggle to keep up with the growing demand for multimedia processing unless supported by parallel architectures. Using 16-core parallel processing can boost efficiency by about 90% [8]. In contrast, AI-based systems naturally scale better for large content libraries, though they require integration with generative models for seamless deployment [2].
| Feature | Traditional Watermarking | AI-Based Watermarking |
|---|---|---|
| Processing Speed | Fast for simple methods; slower for advanced ones | High-speed inference; training demands significant resources |
| Computational Resources | Low; works well on edge devices | High; needs GPUs for training and deployment |
| Robustness | Strong against basic distortions; weak against AI attacks | Effective against AI-driven threats like voice cloning |
| Payload Capacity | Low | High (up to 32 bits per second) |
| Adaptability | Fixed; requires manual updates for new threats | Dynamic; retraining enables adaptation to evolving attacks |
| Development Cost | Lower; based on established techniques | Higher; requires AI expertise and large datasets |
These distinctions highlight how each approach handles the challenges posed by modern piracy techniques.
Protection Against Modern Attacks
The ultimate measure of any watermarking system is its ability to withstand contemporary digital attacks. Traditional methods perform reasonably well against basic distortions such as compression, filtering, and noise addition. Around 90% of these systems are "blind", meaning they can extract watermarks without needing the original audio, simplifying their deployment [1]. Wavelet-domain techniques also strike a good balance between robustness and subtlety.
However, traditional methods falter against advanced threats like voice cloning, neural vocoder resynthesis, and style transfer – all powered by generative AI. A study examining 22 watermarking schemes concluded:
"None of the surveyed watermarking schemes is robust enough to withstand all tested distortions in practice." – Yizhu Wen et al., University of Hawaii at Manoa [2]
AI-based watermarking systems were designed with these modern threats in mind. For instance, AWARE uses time-order-agnostic detectors and Bitwise Readout Heads to recover watermarks even when audio is spliced, reordered, or cut [6]. In tests involving neural vocoder resynthesis, AWARE maintained a Bit Error Rate of just 1.61%, while traditional methods like WavMark and AudioSeal showed much higher error rates of 50% and 39.01%, respectively [6].
Both approaches face challenges from neural compression. Modern codecs like Encodec and Descript Audio Codec remove imperceptible data – including watermarks – to save space. As one researcher explains:
"Watermarking algorithms and neural codecs compete for the same space… neural codecs will end up removing imperceptible watermarks." – Yigitcan Özer et al., Sony AI [5]
In benchmarks, neural compression rendered some AI watermarking models nearly ineffective, reducing their bitwise accuracy to almost 0.00 [5]. Physical-level attacks, such as playing and re-recording audio (known as the "analog hole"), remain a vulnerability for both traditional and AI-based systems [2]. However, AI watermarking demonstrates stronger resistance to digital attacks, making it a more practical solution for protecting content in today’s landscape.
sbb-itb-738ac1e
Where AI Audio Watermarking Is Used Today
AI-powered audio watermarking has become a game-changer for protecting assets across various industries. From safeguarding music catalogs to combating financial fraud, this technology addresses challenges that traditional methods often can’t manage effectively on a large scale. Here’s a closer look at how businesses and large-scale content systems are benefiting from these advancements.
Business and Enterprise Applications
AI watermarking has become a critical tool for industries like media, finance, and legal services. By adapting to evolving threats, it provides a higher level of security for audio assets. For example, media and entertainment companies use this technology to protect music, podcasts, and audiobooks. Watermarks help prove ownership, prevent unauthorized use, and block tampering, giving creators more control over their work. In broadcasting and streaming, watermarks simplify processes such as automated content identification, monitoring for unauthorized broadcasts, and even billing and analytics.
In the financial sector, AI watermarking is a key defense against voice cloning and fraud. One notable case involved AI-generated voice deepfakes that were used to steal $243,000 through a fraudulent transfer [2]. Educational institutions and legal professionals also use watermarking for managing and verifying audio content. It automates the organization of large audio collections and ensures the integrity of recordings used in critical situations, such as legal evidence. These capabilities not only help prevent fraud but also maintain the credibility of audio content in sensitive environments.
AI for Large-Scale Content Protection
One of the standout features of AI watermarking is its ability to scale effectively. Unlike traditional methods, it offers real-time protection and tracking for massive audio libraries. Advanced systems ensure high data capacity while keeping error rates minimal, making them ideal for managing and monitoring extensive collections of audio content.
Web3 platforms and decentralized networks are increasingly adopting AI watermarking alongside blockchain technology. This combination helps track royalties and prevents unauthorized creation of audio NFTs, offering a secure and tamper-proof way to verify the origin of audio assets. These integrations are paving the way for more reliable and transparent content management in the digital age.
ScoreDetect‘s AI-Enhanced Audio Watermarking Solution
ScoreDetect combines the power of AI and blockchain to safeguard audio content on a large scale. By embedding nearly invisible watermarks directly into audio waveforms through neural networks, the system ensures these marks remain intact even after common audio alterations like pitch shifting, time stretching, or MP3 compression. This approach addresses the weaknesses of traditional metadata tags, creating a watermarking solution that’s far more resilient to tampering.
How ScoreDetect Combines AI and Blockchain
ScoreDetect uses a two-step verification process that merges AI’s adaptability with blockchain’s reliability to deliver robust protection. Here’s how it works:
- Registration: The platform extracts a unique fingerprint from audio files using advanced techniques like MFCCs, chromagrams, and Constant-Q Transforms. This fingerprint is then anchored on the Ethereum blockchain via smart contracts, creating an unalterable record of ownership. The process is incredibly efficient, with upload times of just 0.017 seconds and contract execution times of 0.044 seconds [4].
- Monitoring: AI models come into play during the monitoring phase, adapting to changes in audio signals to accurately match fingerprints – even if the audio has been modified. The system achieves impressive results, including an AUC of 0.957 and a 95.2% True Positive Rate at just 1% False Positive Rate [4]. This dual-layered approach effectively balances the "magic triangle" of watermarking: imperceptibility, robustness, and capacity, while adding blockchain-backed security [1] [4].
Key Features of ScoreDetect
ScoreDetect’s Enterprise plan is designed to automate audio content protection with four essential functions:
- Prevent: Embeds undetectable, AI-enhanced watermarks into audio files that remain intact even after attempts to alter or remove them.
- Discover: Uses advanced web scraping technology with a 95% success rate to locate pirated audio content online.
- Analyze: Provides detailed assessments and quantitative evidence of unauthorized use.
- Take Down: Issues takedown notices with a 96% success rate in removing pirated content from the web.
To streamline workflows, ScoreDetect integrates with over 6,000 web apps via Zapier. Its WordPress plugin adds another layer of functionality by capturing every published article or audio file, creating blockchain-verified ownership records while enhancing SEO through stronger E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) signals.
This automation marks a shift from traditional, labor-intensive copyright enforcement methods. For industries like media, entertainment, finance, legal services, and content creation, ScoreDetect offers the scalability to protect extensive audio libraries without requiring significant manual effort. It’s a game-changer for organizations looking to safeguard their content efficiently and effectively.
Conclusion
The move from older methods to AI-based audio watermarking marks a major leap in securing audio content. Traditional watermarking techniques, which rely on deterministic signal processing, often struggle against challenges like compression, re-recording, and other forms of distortion. AI-powered watermarking tackles these limitations by embedding identification markers directly during content creation. This approach results in tamper-resistant signatures that can withstand even aggressive attempts to remove them, redefining how businesses protect their audio assets.
Platforms like ScoreDetect showcase the potential of AI-driven watermarking to not only solve these challenges but also reshape content security. By automating processes and delivering highly accurate detection rates, ScoreDetect stands out with a 95.2% True Positive Rate at just a 1% False Positive Rate [4]. Moreover, it seamlessly integrates watermarking into content-generation workflows, making it scalable and efficient.
"SynthID’s approach differs fundamentally from traditional watermarking by integrating identification markers at the generation level rather than as removable metadata, creating a substantially more tamper-resistant system." – Karan Bhutani [9]
ScoreDetect takes this a step further by combining AI’s adaptability with the permanence of blockchain technology. The platform embeds invisible watermarks that can endure pitch shifting, time stretching, and compression. These watermarks are then anchored on the Ethereum blockchain, providing verifiable proof of ownership. This fusion of AI and blockchain meets modern content protection needs with a solution that is both scalable and automated.
As AI-generated content continues to grow and removal techniques become more advanced, AI-powered watermarking offers the durability, precision, and scalability required to protect audio content effectively in an ever-evolving digital landscape.
FAQs
How does AI-based audio watermarking offer better protection against modern audio manipulation techniques?
AI-powered audio watermarking steps up protection by embedding invisible and durable watermarks into audio files. These watermarks are designed to withstand common challenges like compression, signal processing, or even intentional tampering.
Using techniques like adversarial optimization and machine learning, this approach ensures watermarks remain both resilient and easy to detect, even when faced with aggressive attempts to alter the audio. It’s a highly effective solution for protecting audio content in an ever-evolving digital world.
What kind of computing power is needed for AI-based audio watermarking?
AI-driven audio watermarking demands powerful computing resources, primarily because of the intricate deep learning models at play. Training these models typically involves GPUs or TPUs, which can handle the massive datasets and fine-tune neural network parameters. This level of processing ensures the watermarking remains resilient against various audio transformations or attempts at tampering.
Even for real-time detection, substantial computational capability is often required – especially when dealing with high-quality audio streams or managing extensive content libraries. Techniques such as adversarial training and data augmentation, while enhancing the model’s robustness, can further increase these resource demands. Though these requirements surpass those of traditional watermarking methods, they deliver greater accuracy, scalability, and durability in safeguarding digital audio content.
Which industries benefit the most from AI-based audio watermarking?
AI-driven audio watermarking has become a cornerstone in industries where safeguarding content, verifying its source, and tackling piracy are top priorities. In the media and entertainment sector, this technology protects copyrighted audio – like music, podcasts, and other sound-based content – from unauthorized sharing or misuse. It’s also a critical tool in cybersecurity, helping to prevent the exploitation of digital assets, especially as AI-generated synthetic audio becomes more prevalent.
Beyond that, industries like education, government, and legal services depend on audio watermarking to confirm the origin of recordings and ensure the integrity of sensitive communications. With advanced generative AI models making voice fraud and impersonation more sophisticated, this technology has become essential for maintaining authenticity and safeguarding intellectual property.

