Audio watermarking embeds hidden data into sound files to safeguard intellectual property. It’s more secure than metadata because it integrates directly into the audio, making it harder to remove. Yet, applying it across platforms is complex due to:
- File Compression: Formats like MP3 and AAC often remove watermarks during compression.
- Playback Distortions: Noise, room acoustics, and hardware differences can disrupt detection.
- AI Threats: Generative AI tools and neural codecs can erase watermarks entirely.
Emerging solutions like transfer learning and blockchain integration offer ways to improve watermark reliability. Systems like AWARE and ScoreDetect are leading advancements, delivering better detection rates and copyright protection without compromising audio quality. However, challenges remain in creating universal standards and handling combined distortions across platforms.
I Put a Secret Audio Watermark in a Video File
Main Challenges in Cross-Platform Audio Watermarking
Implementing audio watermarking across various platforms and devices isn’t without its hurdles. These challenges can be grouped into three main areas: issues arising from digital signal processing, distortions caused by real-world playback, and new threats introduced by AI-driven tools.
Signal-Level Problems
Digital audio files are constantly transformed as they move through different platforms. Compression formats like MP3, AAC, and OGG are designed to strip away what they deem unnecessary data, which often includes the watermark. The challenge grows with modern neural codecs like Encodec and Descript Audio Codec, which are specifically built to eliminate subtle embedded signals to save storage.
"Watermarking algorithms and neural codecs compete for the same space… neural codecs will end up removing imperceptible watermarks." – Yigitcan Özer, Researcher, Sony AI [7]
Other common processes like format conversions, cropping, splicing, and frame reordering can disrupt the synchronization needed to detect watermarks. Bitrate reductions, especially down to 64 kbps, can degrade the watermark so much that it becomes unrecognizable [1]. Even minor modifications – like pitch shifting or reducing bit depth – can cause significant spikes in bit error rates [1][7].
Spectral manipulations are another challenge. Techniques like low-pass, high-pass, and notch filtering can erase watermarks embedded in specific frequency ranges. While many watermarking systems struggle under these conditions, advanced models like AWARE have demonstrated resilience, maintaining a 0.00% error rate despite such stress [1].
But digital processing is only part of the story. Real-world playback introduces its own set of challenges.
Physical-Level Problems
Once audio is played through speakers and captured by microphones, watermarks face unpredictable distortions [8].
Ambient noise, electrical interference, and room acoustics can mask or distort the subtle patterns of a watermark. The distance between the playback device and microphone also plays a critical role. In May 2019, Amazon researchers Mohamed Mansour and Yuan-Yen Tai presented a watermarking algorithm at the ICASSP conference that could detect watermarks at distances over 20 feet – but only when the watermark was embedded in at least two seconds of audio [8].
"Watermarking schemes designed for on-device processing tend to break down, however, when a signal is broadcast over a loudspeaker, captured by a microphone, and only then inspected for watermarks." – Yuan-Yen Tai, Research Scientist, Amazon [8]
Hardware inconsistencies, like differences in microphone quality across Android devices, further complicate detection. About 90% of today’s audio watermarking systems operate "blind", meaning they don’t rely on the original signal for comparison. This makes them especially vulnerable to distortions caused by hardware variations [3][9].
Adding to these difficulties, AI technologies are introducing entirely new threats to watermark resilience.
AI-Related Challenges
The rise of generative AI has created a fresh set of obstacles. Tools like voice conversion software and text-to-speech systems can recreate audio that mimics the original but removes the embedded watermark. Under neural compression attacks using codecs like Descript Audio Codec, the accuracy of some leading watermarking systems drops to 0.33 or even 0, making the watermark undetectable [7].
"None of the surveyed watermarking schemes is robust enough to withstand all tested distortions in practice." – Yizhu Wen, University of Hawaii at Manoa [4]
Human hearing poses an additional limitation. Unlike visual watermarks, audio watermarks must remain imperceptible to listeners. However, strengthening the watermark to make it more robust often introduces audible distortions, defeating the purpose of keeping the protection invisible [3].
Why Current Watermarking Methods Fall Short
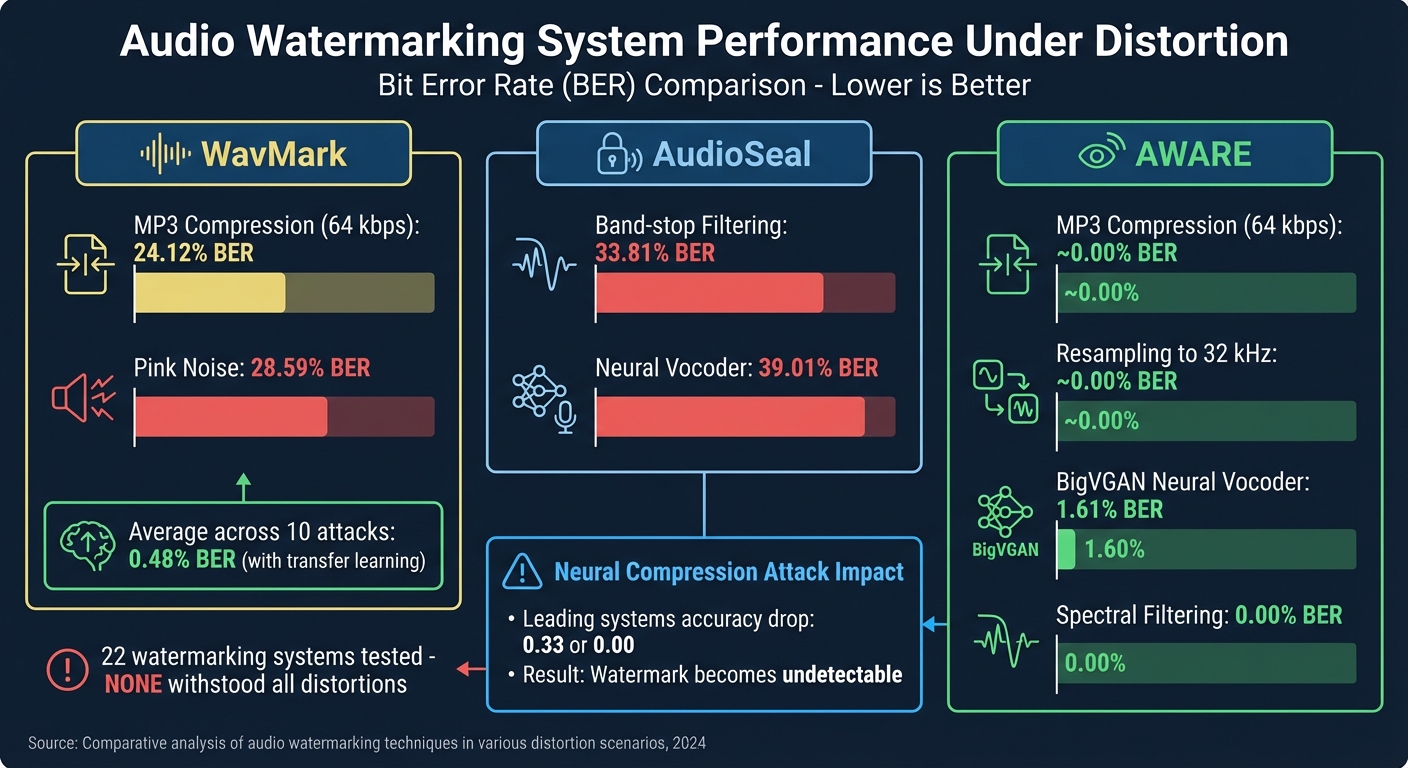
Audio Watermarking Performance: BER Comparison Across Distortion Types
As previously discussed, technical and physical distortions already pose significant challenges for watermarking methods. On top of that, two other major issues further diminish their reliability.
No Standard Across Platforms
There’s no universal approach to how audio is processed, compressed, or played across different devices and services. This lack of consistency creates a fragmented landscape where watermarks that survive on one platform may completely fail on another.
Neural codecs, designed to eliminate imperceptible audio elements, often strip out watermarks during compression. A 2025 study revealed that leading watermarking models had a 0.00% bitwise accuracy when subjected to rigorous neural compression attacks [7].
"Watermarking algorithms and neural codecs compete for the same space… if we consider the limit situation where both algorithms successfully achieve their purpose, we believe that neural codecs will end up removing imperceptible watermarks." – Yigitcan Özer, Researcher, Sony AI [7]
Every platform employs its own unique compression algorithms, playback standards, and processing methods. For instance, a watermark that works with Encodec might fail entirely with Descript Audio Codec. Without a standardized framework, developers are left scrambling to adapt with every new codec or platform update. This inconsistency not only intensifies competition between codecs but also opens up vulnerabilities when multiple distortions are applied.
Weakness Against Multiple Distortions
Adding to the platform inconsistencies, real-world audio often encounters compounded distortions that further undermine watermark durability. Audio files face challenges such as heavy compression, low-quality playback, background noise, and repeated re-encoding – all of which can degrade watermark integrity.
Deep learning-based watermarking models are trained to handle "attack layers", which are artificial distortions meant to simulate real-world conditions. However, these models tend to overfit to their training data, leaving them vulnerable to unexpected combinations of distortions. A 2025 review of 22 audio watermarking systems found that none were resilient enough to withstand all tested real-world distortions [4].
For example, under MP3 compression at 64 kbps, WavMark’s Bit Error Rate (BER) spiked to 24.12%, and when exposed to pink noise, it rose to 28.59%. AudioSeal fared even worse, with a BER of 33.81% under band-stop filtering and 39.01% after passing through a neural vocoder [1]. These aren’t rare occurrences – they’re everyday scenarios on platforms like YouTube, Spotify, and TikTok.
"Reliably detecting synchronization markers is nearly as difficult as extracting the watermark itself, and thus inherits similar failure modes under distortion." – Kosta Pavlović, Researcher, DeepMark [1]
Physical distortions add yet another layer of complexity. For instance, when audio is played through speakers and re-recorded – a common piracy tactic – environmental noise and device-specific frequency responses often destroy the embedded signal. Most existing solutions focus solely on signal-level distortions and are ill-equipped to handle this "air-gap" scenario [4].
sbb-itb-738ac1e
Transfer Learning as a Solution
Transfer learning offers a practical way to address the challenges of cross-platform inconsistencies, providing a method to strengthen the resilience of digital watermarks. By using a pre-trained model, transfer learning enables systems to adapt effectively to different platforms and distortion types, ensuring consistent watermark performance across varied playback conditions.
How Transfer Learning Works in Audio Watermarking
The process begins with a base model trained on extensive audio datasets like LibriSpeech or Common Voice. These datasets help the model identify general patterns in audio behavior under various conditions. Once trained, the model can then adapt to platform-specific challenges without requiring a complete retraining process.
In October 2020, Meta AI researchers Changhan Wang, Jiatao Gu, and Juan Pino showcased this approach in speech recognition. By incorporating speech-to-text translation as an auxiliary task, they achieved a 24.6% reduction in Word Error Rate for low-resource languages. This demonstrated that knowledge from a high-resource "source" task can significantly enhance the performance of a "target" model in less predictable environments [10].
"Transfer learning from high-resource languages is known to be an efficient way to improve end-to-end automatic speech recognition (ASR) for low-resource languages." – Meta AI [10]
When applied to audio watermarking, transfer learning enhances robustness by designing architectures that can withstand various conditions, rather than trying to account for every possible attack scenario [1].
A notable advancement came in October 2025 with the introduction of the AWARE system (Audio Watermarking via Adversarial Resistance to Edits), developed by Kosta Pavlović and his team. AWARE employs a Bitwise Readout Head (BRH) to gather temporal evidence across audio segments, ensuring stability across platforms. It achieved near-zero Bit Error Rates (BER) under conditions like MP3 compression at 64 kbps and resampling to 32 kHz. Even when processed through a BigVGAN neural vocoder, it maintained a BER of just 1.61%, a vast improvement over AudioSeal’s 39.01% BER under the same conditions [1].
"If the architecture is not inherently robust, no amount of augmentation or attack-layer engineering will make training reliably effective." – Kosta Pavlović, Lead Researcher, DeepMark [1]
Benefits of Transfer Learning for Different Environments
The advancements in transfer learning bring real-world advantages to cross-platform watermarking, offering improved generalization, temporal resilience, and feature stability.
1. Better Generalization
Transfer learning enables models to handle unseen distortions. By relying on standard representations like Mel-spectrograms, these systems align with modern audio processing methods [1]. This means watermarks trained on one compression algorithm can survive when exposed to different codecs.
2. Temporal Resilience
Time-order-agnostic detectors aggregate evidence over time, ensuring watermarks remain detectable even when audio is spliced, cut, or rearranged – common occurrences on social media platforms [1]. For instance, the SyncGuard model from Fudan University, introduced in August 2025, maintained 100% extraction accuracy even when 85% of the watermarked audio was cropped [11].
3. Feature Stability
Pre-trained models ensure consistent watermark performance across various playback environments. For example, Mel-based detectors remain reliable, while simpler STFT-only variants degrade significantly under neural vocoder resynthesis [1].
"The Mel-based detector remains highly reliable, whereas the STFT-only variant degrades sharply [under neural vocoder resynthesis]." – Kosta Pavlović et al., Researchers [1]
These advancements translate into impressive real-world results. The WavMark framework, which incorporates transfer learning, achieved an average BER of just 0.48% across ten common attack scenarios – a massive improvement, reducing error rates by over 2,800% compared to earlier tools [2].
How ScoreDetect Solves Cross-Platform Watermarking Problems
ScoreDetect tackles the difficulties of cross-platform watermarking with a combination of advanced AI techniques and blockchain technology, all while maintaining high audio quality.
Invisible and Non-Invasive Watermarking
Using AI-driven adversarial optimization in the time–frequency domain, ScoreDetect embeds watermarks in a way that’s practically undetectable to the human ear. It smartly adjusts the watermarking intensity – making larger modifications in louder audio segments and keeping changes minimal in quieter parts. This ensures the audio remains natural and unaltered. The system employs a Bitwise Readout Head (BRH), which compiles temporal evidence into per-bit scores. This allows ScoreDetect to reliably detect watermarks, even in audio that’s been spliced, cut, or rearranged [1]. These techniques ensure seamless and effective watermarking without compromising the listening experience.
AI-Driven Detection and Takedown Performance
ScoreDetect boasts a 95% success rate in discovering watermarked content and a 96% takedown rate for infringing material. The system’s AI is designed to withstand modern challenges, including neural codecs like Encodec and Descript Audio Codec. It also resists common distortions such as low-pass filtering, MP3 compression, and added noise – all without relying on manual attack simulations [7]. Impressively, ScoreDetect can identify watermarks in audio clips as short as one second, providing a strong defense against voice fraud, impersonation, and unauthorized AI-generated content [2].
Blockchain Integration for Copyright Protection
To strengthen copyright protection, ScoreDetect integrates blockchain technology. By creating blockchain-based checksums, it establishes an unchangeable record of ownership without requiring the storage of original audio files. This immutable record, coupled with the embedded watermark, offers dual-layer protection. It also enables real-time authenticity checks, giving content creators clear and measurable evidence to combat illegal distribution and reduce financial losses from unauthorized streaming [5][6].
Conclusion
Cross-platform audio watermarking faces ongoing challenges from various distortions and the rapid evolution of codec technologies. Factors like compression, ambient noise, and playback distortions continue to test its reliability.
To address these hurdles, techniques such as transfer learning and adversarial training have proven effective. By incorporating simulated attack layers, AI models can adapt to real-world conditions automatically, enhancing their resilience against such distortions [12][7]. This combination of advanced AI methods with strong watermark embedding techniques is shaping a more secure future for audio content protection.
ScoreDetect takes this a step further by merging these AI-driven methods with blockchain-based copyright verification. Its non-invasive watermarking ensures audio quality remains intact, while achieving a 95% discovery rate and a 96% takedown rate, showcasing its effectiveness in practical applications. The integration of blockchain technology adds an immutable ownership record, offering a dual-layer approach to content protection that is both proactive and verifiable.
As Kosta Pavlović of AWARE aptly puts it, "If the architecture is not inherently robust, no amount of augmentation or attack-layer engineering will make training reliably effective" [1]. These advancements in AI-driven watermarking are setting a new standard for safeguarding audio content in today’s complex and ever-changing digital environment.
FAQs
What challenges does file compression create for audio watermarking?
File compression poses a tough hurdle for audio watermarking. Compression techniques often distort audio signals, which can interfere with or completely erase embedded watermarks. This challenge becomes even greater with advanced methods like neural compression, which modify audio in ways that make detecting or extracting watermarks much harder.
To combat this, many watermarking systems are designed to endure common audio manipulations, including compression. While this enhances their ability to hold up under pressure, severe compression can still lead to signal damage, loss of synchronization, or even complete removal of the watermark. As compression methods continue to advance, creating watermarking solutions that work seamlessly across different platforms and formats remains a key priority for protecting digital content.
How does AI enhance the effectiveness of audio watermarking?
AI has brought a game-changing edge to audio watermarking, making it stronger, more flexible, and more secure. With advanced methods like deep learning and adversarial optimization, it’s now possible to create watermarks that are nearly impossible to detect yet can survive challenges like desynchronization, temporal edits, and even manipulation by AI tools.
For instance, AI-powered models can embed watermarks that adapt dynamically to shifts in the audio’s time–frequency domain, making them much harder to tamper with. On top of that, neural network-based techniques introduce key-controlled embedding and decoding, which not only boosts security but also allows multiple watermarks to coexist without clashing. These advancements ensure that audio watermarks remain a reliable tool for protecting content in today’s rapidly changing digital world.
How does transfer learning enhance the robustness of audio watermarking?
Transfer learning brings a new level of resilience to audio watermarking by utilizing pre-trained models to handle various audio distortions and attacks. By tapping into knowledge gained from extensive and varied datasets, it equips the system to endure common challenges like compression, added noise, or resampling – issues frequently encountered in digital content distribution.
This method also enhances the training of models to consistently detect and decode watermarks, even in tough scenarios like desynchronization or repeated embedding. By fine-tuning models on a wide range of audio conditions and simulated attacks, transfer learning bolsters the system’s defenses, offering stronger protection against tampering or removal attempts – a critical aspect of safeguarding digital rights.

