AI systems today rely heavily on datasets that combine multiple data types – like text, images, audio, and 3D scans. To train these systems effectively, annotations across these formats must align perfectly. For example, a pedestrian marked in a camera image must match the same object in a LiDAR scan. This process, called multimodal content matching, ensures consistency across formats, which is critical for applications like autonomous vehicles, vision-language models, and even content protection.
Key Takeaways
- Why It Matters: Misaligned annotations lead to errors, like AI "hallucinating" nonexistent objects, which can hurt performance and trust.
- Challenges: Syncing data from sensors with different speeds (e.g., LiDAR vs. cameras) and managing errors due to temporal drift or spatial misalignment.
- Techniques: Tools like Dynamic Time Warping (DTW), adversarial training, and transfer learning improve cross-modal alignment.
- Real-World Examples: Autonomous vehicles, retail monitoring, and healthcare imaging benefit from precise multimodal annotations.
- Security: Advanced tools like Idem and Tectus protect datasets and annotations from misuse or tampering.
By addressing these challenges with structured quality checks, advanced algorithms, and secure annotation layers, multimodal content matching is reshaping how industries manage and secure their data.
Master Encord’s Multimodal AI Data Platform: Multimodal Curation & Annotation
sbb-itb-738ac1e
How Multimodal Content Matching Works
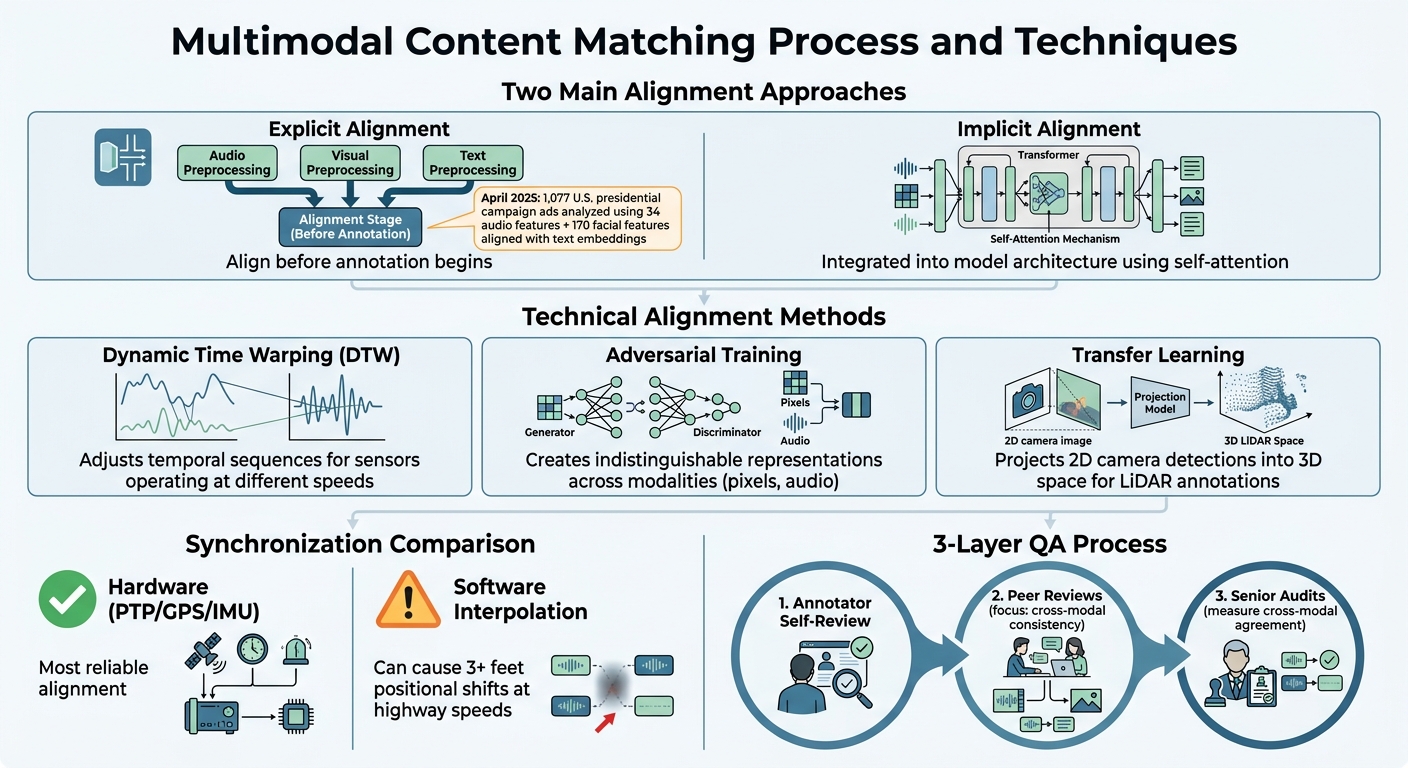
Multimodal Content Matching Workflow and Key Techniques
Multimodal content matching builds on the alignment challenges discussed earlier, using advanced techniques to ensure accurate connections across various data formats.
At its core, multimodal content matching depends on alignment techniques to link information from different modalities. For instance, it ensures that a bounding box around a pedestrian in a camera image matches the same object in a 3D LiDAR point cloud. While synchronization issues like mismatched timestamps or spatial coordinates can complicate this process, these alignment methods fine-tune both aspects to establish precise cross-modal connections [1].
There are two main approaches to alignment. Explicit alignment involves preprocessing steps where separate models align elements across modalities before annotation begins. On the other hand, implicit alignment integrates this process directly into model architecture, often leveraging transformer-based self-attention to dynamically assess cross-modal feature relevance [6]. A notable example occurred in April 2025, when researchers used implicit alignment to analyze 1,077 U.S. presidential campaign ads. They aligned 34 audio features and 170 facial features with text embeddings to predict tonal patterns [6].
Cross-Modality Alignment Methods
The technical backbone of multimodal matching consists of several specialized algorithms:
- Dynamic Time Warping (DTW): This method adjusts temporal sequences, ensuring modalities align even when sensors operate at different speeds [6].
- Adversarial training: By creating indistinguishable representations of data from different modalities (like pixels or audio waves), this technique ensures high-quality mapping [6].
- Transfer learning: This approach improves efficiency by projecting annotations from one modality to another. For example, 2D camera detections can be projected into 3D space, providing a starting point for LiDAR annotations and reducing manual labeling time [1].
Hardware synchronization methods, such as PTP or shared GPS/IMU, remain the most reliable for aligning data. In contrast, software-based interpolation, though more accessible, can result in positional shifts of over three feet at highway speeds, which is far from ideal [1].
These strategies form a solid foundation for reducing errors and improving annotation accuracy.
Reducing Annotation Errors
To minimize mistakes, a structured quality assurance (QA) process is essential. The most effective setup involves three layers: annotator self-review, peer reviews that focus on cross-modal consistency, and senior audits to measure agreement across modalities [1].
Unified taxonomies play a critical role in preventing inconsistencies. By clearly defining relationships in annotation guidelines, they ensure that labels remain consistent. For example, every 3D cuboid must correspond to a 2D bounding box, and labels like "pedestrian" must be identical across all formats, including video frames, point clouds, and image annotations [1][5]. Adding prefix prompts – clear instructions or questions like "What is the book title?" – early in the workflow helps annotators focus on specific details, reducing variability and improving label accuracy [7]. Additionally, annotators should flag synchronization issues rather than forcing inaccurate labels, which helps maintain clean data pipelines [1].
Domain-Specific Dataset Applications
Multimodal content matching isn’t just a theoretical concept; it’s actively reshaping how industries tackle their unique challenges. Each sector has specific needs, and addressing them often requires tailored annotation methods.
Open-Vocabulary Segmentation
Traditional segmentation methods rely on fixed label sets, but open-vocabulary segmentation takes a different approach. It uses natural language to identify and segment objects, going beyond predefined categories. This method links written or spoken descriptions directly to specific parts of an image or even a 3D scene, allowing for much finer detail than conventional methods [4].
In November 2025, researchers at the University of Pennsylvania introduced DenseAnnotate, a platform driven by audio input. They enlisted over 1,000 annotators to curate a dataset comprising 3,531 images and 898 3D scenes. Instead of typing, annotators narrated their observations, resulting in 19,000 object captions and 8,746 image captions across 20 languages. This speech-based approach improved cultural alignment by 47%, enhanced 3D spatial understanding by 54%, and sped up annotation processes by 40% [4].
Here’s a practical example: in retail, vision-language models can now detect specific scenarios like "out-of-stock items on the top shelf" or "damaged packaging near the expiration date", even if these situations weren’t part of the training data. In healthcare, this technology can identify anatomical features described in radiology reports, even when the terminology varies from one institution to another.
These advancements demonstrate how robust multimodal techniques are essential for the functionality of advanced vision-language models.
Training Vision-Language Models
High-quality multimodal annotations are the backbone of effective vision-language models, which are used in applications like content recommendations and safety filters. These models rely on precise datasets where text descriptions align accurately with corresponding images. However, traditional datasets often fall short, offering only broad image-text pairings that miss the finer details necessary for deeper reasoning [8].
In July 2024, a collaboration between the University of Rochester and Adobe Research introduced FineMatch, a benchmark featuring 49,906 human-annotated image-text pairs. This benchmark was designed to pinpoint and fix subtle mismatches in categories like Entity, Relation, Attribute, and Number. They also introduced the ITM-IoU metric, which evaluates predictions at both character and semantic levels, reducing errors like hallucinations in text-to-image generation systems [2]. Interestingly, studies found that roughly 40% of the LAION dataset and 20% of the Datacomp dataset include images with textual content that overlaps with captions, which can skew model evaluations [3].
"When we deployed AI career coaching to LATAM job seekers, our first model broke because users recorded goals in Spanish but submitted resumes in English. Human behavior upends annotation assumptions across modalities, and we had to re-label 40% of our training set for code-switching patterns." – Renzo Proano, Team Principal, Berelvant AI [1]
This quote underscores the importance of accounting for cultural and linguistic nuances in multimodal annotation. For instance, native speakers can identify code-switching patterns and subtle cultural elements that automated systems often miss.
In other industries, the stakes are equally high. Autonomous vehicles, for example, generate up to 2 TB of data daily [1]. Multimodal annotation ensures that 2D bounding boxes from cameras align correctly with 3D cuboids from LiDAR, a critical step in building safe perception systems. Similarly, in smart home technology, vision-language models trained on carefully annotated datasets can predict user intentions, like adjusting lighting or thermostats based on activity, enhancing both energy efficiency and comfort [8].
Multimodal Matching for Content Protection
As datasets grow in complexity and value, safeguarding the intellectual property within them is becoming increasingly important. Multimodal datasets – those combining inputs like text, images, and audio – pose unique challenges because AI meaning is distributed across multiple inputs, rather than confined to a single one [5]. This makes it easier for pirates to manipulate or strip individual components, emphasizing the need for robust cross-modal security measures.
To address these challenges, advanced matching solutions are being developed to protect both the data and its annotations.
Content Identification with Idem
InCyan’s Idem platform is designed to tackle the issue of content misuse through a highly resilient identification system. Unlike traditional detection tools that falter when content is altered, Idem’s AI-driven multimodal matching engine can recognize content even after significant transformations. Whether it’s mobile edits, memes, cropping, or compression, Idem can identify ownership even when only 10% of the original asset remains visible.
This technology ensures the integrity of datasets by preventing the misuse of annotation relationships. For example, in autonomous driving datasets, annotations like 2D bounding boxes from cameras must align perfectly with 3D cuboids from LiDAR. Idem’s multimodal matching ensures that even if pirates modify individual frames or sensor data, the intellectual property remains identifiable across formats. It also combats "concept misalignment", where category labels or names are altered to obscure the use of proprietary data [9].
While Idem excels in identification, it works hand-in-hand with watermarking technologies to provide a comprehensive security solution.
Protecting Annotations with Tectus
InCyan’s Tectus platform offers invisible watermarking to embed ownership proof directly into digital assets. This blind watermarking solution delivers an undetectable yet defensible layer of protection, enabling swift copyright enforcement without disrupting the user experience.
For annotated datasets, Tectus focuses on a critical yet often overlooked area: securing the annotation layer itself. With Multimodal Large Language Models (MLLMs) reducing annotation costs to just 1/1000th of traditional manual efforts [9], the annotations represent a significant investment of computational resources and expertise. Protecting these annotations is essential to preserving the overall value of the dataset.
Tectus embeds invisible watermarks directly into the metadata layer of datasets, ensuring that even if raw images or text are extracted, the origins of the annotation work remain traceable. This traceability extends through dataset redistribution and format changes, providing a reliable way to verify ownership and protect intellectual property.
The Future of Multimodal Content Matching in Dataset Annotation
As the field of dataset annotation evolves, the focus is shifting from merely collecting more data to ensuring that different modalities – like spatial, temporal, and contextual elements – stay meaningfully aligned. The Toloka Team highlights this shift, stating, "Accuracy is no longer evaluated per data type but across their interaction. Labels that appear internally consistent within one modality can conflict when interpreted alongside others" [5]. This underscores the growing complexity in managing relationships between modalities.
Emerging tools and techniques are addressing these challenges. Model-in-the-loop frameworks now leverage pre-trained models to generate initial labels, which human annotators refine using active learning and iterative feedback. Cross-modal transfer learning is also gaining traction, enabling annotators to project 2D detections into 3D space to create foundational cuboids for LiDAR data [1]. Additionally, triple-modality integration – which combines text, image, and audio – shows promise in reducing ambiguity and preserving more information during content detection [10].
A significant milestone in this area came in February 2026 with the introduction of the EcoDatum framework. This framework employs a search-based optimization algorithm for weak supervision and achieved first place on the DataComp leaderboard, scoring an average of 0.182 across 38 evaluation datasets. This marked a 28% improvement over the baseline [3]. By automating quality scoring, EcoDatum has demonstrated how high-quality signals can be identified even in noisy, web-crawled data, paving the way for better dataset integrity and stronger security measures.
Security is another critical aspect of future systems. Automated validation layers are being developed to ensure that 3D cuboids and 2D boxes align properly, strengthening dataset integrity across all modalities [5][1]. Quality assurance processes are evolving to span multiple modalities rather than focusing on isolated checks [1].
Organizations are already leveraging these advancements. Tools like InCyan’s Idem, designed for evasion-proof identification, and Tectus, which offers invisible watermarking, are helping to protect both data and annotations. With the growing adoption of native multimodal processing in advanced models like GPT-5.4 and Gemini 3.1, maintaining robust security and verification across all modalities is becoming a cornerstone for enterprise-scale dataset management.
FAQs
How can I check if my sensors are time-synced for labeling?
To keep your sensors time-synced for labeling, make sure data from various sources – like images, videos, and audio – are properly aligned in time. Verify that sensor timestamps match up within a margin that works for your specific application. You can use techniques such as cross-referencing known events or applying synchronization signals to confirm timing accuracy. Getting this right is key to maintaining consistent multimodal annotations, which directly impacts the quality of your dataset and the reliability of AI training and evaluation.
When should I use explicit vs. implicit cross-modal alignment?
When tasks demand a precise, element-by-element match – like spotting mismatched phrases in captions or subtle inconsistencies between text and images – explicit cross-modal alignment is the way to go. It ensures detailed correspondence, making it perfect for these nuanced scenarios.
On the other hand, implicit alignment works better for broader tasks. For instance, it’s ideal for assessing overall semantic similarity or filtering datasets, especially when dealing with noisy or large-scale data. Instead of focusing on fine details, it prioritizes general coherence, which can significantly enhance the quality of multimodal training data.
How can I secure multimodal datasets and their annotations from tampering?
To keep multimodal datasets and annotations secure, it’s essential to use modern content protection tools that safeguard the integrity of diverse data types, including images, audio, and text. Solutions like invisible watermarking and blockchain verification are particularly effective – they offer tamper-proof ownership tracking and timestamping, ensuring data remains authentic. Additionally, automated tools for monitoring and issuing takedown notices can quickly identify and address any unauthorized changes, helping protect dataset integrity and uphold intellectual property rights at every stage of their lifecycle.

