AI audio watermarking is a method of embedding hidden data into speech recordings to verify their origin, protect intellectual property, and detect tampering. This technology is crucial as voice cloning and deepfake audio scams grow more sophisticated, with cases like a $243,000 theft through a CEO voice impersonation illustrating the risks. Modern watermarking systems can embed identifiers with extreme precision – down to 1/16,000 of a second – making it possible to detect even minor edits in audio files.
Key Points:
- Purpose: Protects speech content by embedding identifiers directly into audio.
- Core Features: Inaudible to humans, resistant to distortions, and capable of pinpointing tampered sections.
- Technology: Uses AI-driven techniques like adversarial optimization and frameworks like WMCodec, achieving 99% accuracy even under compression or noise.
- Applications: Safeguards intellectual property, prevents fraud, and ensures compliance with regulations like the EU AI Act.
- Challenges: Vulnerabilities to advanced attacks and balancing watermark strength with audio quality.
- Future Directions: Innovations like parameter-level watermarking and faster detection systems aim to address these challenges.
AI watermarking is an evolving tool for securing digital audio, offering a proactive defense against fraud and misuse while supporting legal and regulatory needs.
How to Spot AI Content: Watermarking Explained
How AI Audio Watermarking Works
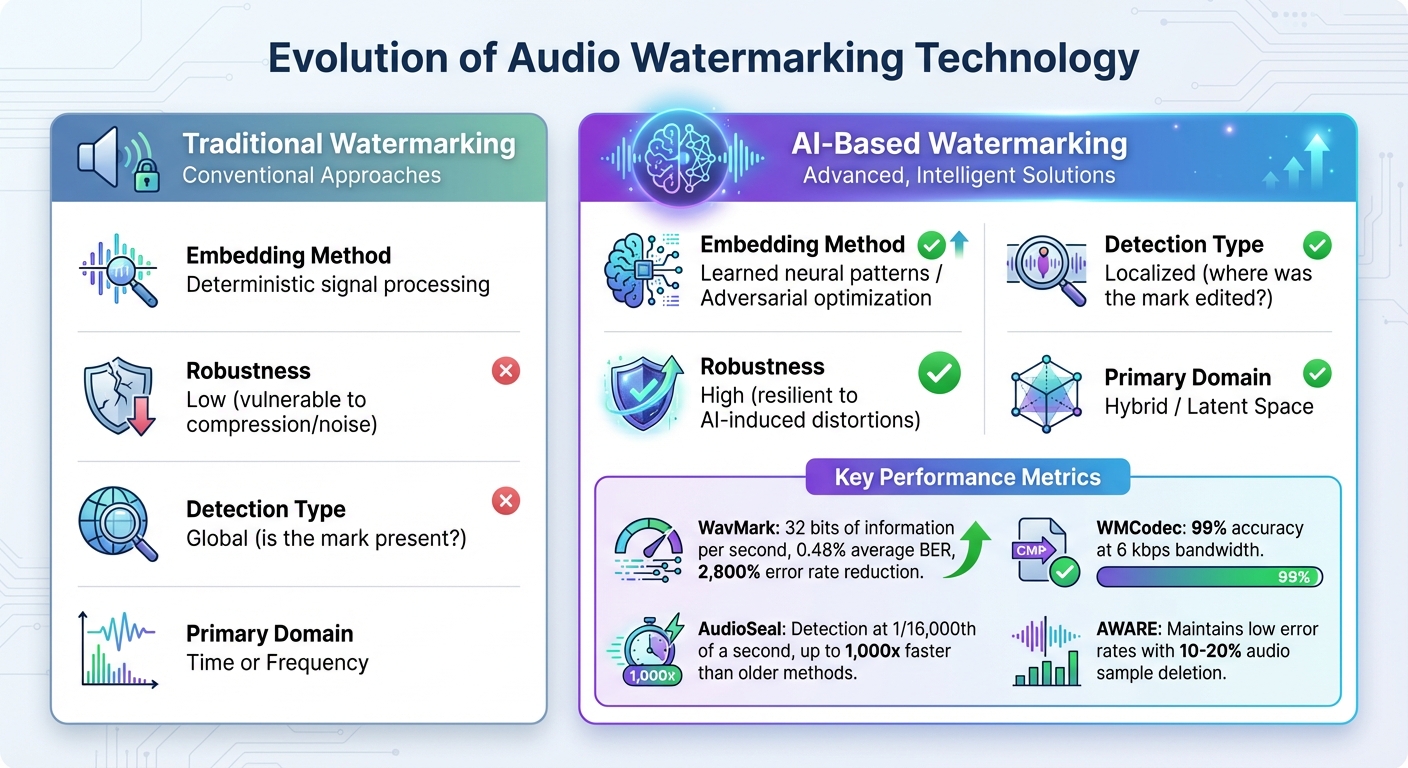
Traditional vs AI-Based Audio Watermarking: Key Differences
Basic Principles of Watermarking in Speech Systems
Audio watermarking in speech systems hinges on three key factors: imperceptibility, robustness, and recoverability.
- Imperceptibility ensures the watermark remains inaudible to human listeners while maintaining the original audio quality.
- Robustness measures the watermark’s ability to withstand distortions like compression, noise, or AI-induced changes.
- Recoverability refers to how accurately the embedded data can be retrieved, typically evaluated using the Bit Error Rate (BER) [3][8].
These principles work together to verify content authenticity. If audio has been altered or generated by unauthorized AI, the watermark’s absence or degradation signals that the content is unauthentic [5]. AI-based methods enhance this process by learning patterns that adapt to the unique characteristics of the audio [3].
AI Algorithms for Audio Watermarking
AI algorithms embed watermarks using adversarial optimization, which treats the watermarking process as a controlled signal adjustment. The system makes larger adjustments in louder audio segments and smaller ones in quieter sections, aligning with how humans perceive sound [8].
Advanced architectures like the Attention Imprint Unit (AIU) integrate watermark data deeply into speech features using cross-modal attention, making it resistant to issues like compression-induced quantization noise [5]. Another system, WMCodec, combines compression and watermarking during training to reduce cumulative errors. For example, in tests using the LibriTTS dataset, WMCodec achieved 99% accuracy even at a low bandwidth of 6 kbps [5].
The WavMark framework showcases the potential of these systems by embedding 32 bits of information into a single second of audio while maintaining a low average BER of 0.48%, even after enduring ten common audio distortions. This represents a massive improvement – reducing error rates by over 2,800% compared to earlier methods [1].
| Feature | Traditional Watermarking | AI-Based Watermarking |
|---|---|---|
| Embedding Method | Deterministic signal processing | Learned neural patterns / Adversarial optimization |
| Robustness | Low (vulnerable to compression/noise) | High (resilient to AI-induced distortions) |
| Detection Type | Global (is the mark present?) | Localized (where was the mark edited?) |
| Primary Domain | Time or Frequency | Hybrid / Latent Space |
These advanced embedding techniques enable precise and rapid detection, even in segments that have been tampered with.
Watermark Detection and Verification
After embedding, detection systems verify the watermark’s integrity with localized analysis, pinpointing tampered regions in real time. For instance, AudioSeal‘s detector can identify watermark presence at every time step – down to 1/16,000th of a second – making it up to 1,000x faster than older methods [7].
The Bitwise Readout Head (BRH) method processes audio frames independently using 1×1 convolutions, combining temporal data into a single score for each watermark bit. This "time-order-agnostic" approach ensures accurate detection even when audio has been cut, rearranged, or spliced [8]. In October 2025, the AWARE system demonstrated its ability to maintain low error rates even when 10% to 20% of audio samples were deleted [8].
"The detector directly predicts for each time step (1/16k of a second) if the watermark is present or not, which makes it ultra fast and suitable for real-time applications." – AudioSeal Project Summary [7]
Detection systems often utilize pretrained models like ResNet or CLAP (Contrastive Language-Audio Pretraining) to analyze Mel-spectrograms. These models ensure watermarks remain detectable even after neural vocoder resynthesis or voice cloning attempts [8][5][9]. By accounting for compression artifacts, this approach allows for accurate recovery of embedded data during live speech transmission [5].
Benefits of AI Audio Watermarking in Speech Systems
Protecting Intellectual Property
AI audio watermarking offers a proactive solution to safeguard intellectual property by embedding identifiable markers directly into speech content during its creation. Unlike methods that passively detect synthetic audio, watermarking ensures content is traceable even after it undergoes transformations like compression or resampling. This makes it an essential tool for tracking provenance and attribution [1][8].
Advanced frameworks like WavMark can encode up to 32 bits of information into just one second of audio, enabling the embedding of details such as user IDs, timestamps, model versions, and licensing data. These markers remain intact through common audio manipulations, ensuring reliable IP tracing. Additionally, watermarked audio used in training generative models can pass these markers on to derivative content, creating an ongoing chain of attribution [3].
The need for such technology became evident in 2023, when AI-generated songs mimicking artists like Drake and The Weeknd sparked copyright debates across the music industry. Tools like AudioSeal address this challenge by enabling detection at a granular level – down to 1/16,000th of a second – helping identify unauthorized or synthetic segments within long audio streams.
"Watermarking has re-emerged as a practical mechanism to label both synthetic and authentic content to support provenance, traceability, and downstream moderation." – Kosta Pavlović, Lead Author, AWARE [8]
This robust attribution system not only protects intellectual property but also strengthens security in speech applications.
Improving Security in Speech Applications
The rise of voice cloning and deepfake audio presents significant security challenges, especially in sectors like finance and enterprise communications. AI watermarking combats these risks by enabling real-time verification, distinguishing between genuine human speech and AI-generated audio.
Modern detection systems operate much faster than earlier methods – up to 1,000 times quicker – making them practical for real-time monitoring in enterprise environments [7]. For instance, in January 2024, Meta integrated watermarking into its generative AI demos, including Audiobox and Seamless, serving approximately 100,000 users daily. This ensured traceability for AI-generated speech outputs [7]. Multi-bit watermarking further enhances security by linking specific audio outputs to individual users or model versions, increasing accountability in speech synthesis systems [5][7].
Technologies like AWARE maintain watermark integrity even under adversarial conditions like splicing, temporal cuts, or desynchronization. Similarly, WMCodec achieves over 99% accuracy in watermark extraction, even when audio is subjected to noise, resampling, or low-bandwidth conditions such as 6 kbps [5]. These capabilities are critical for protecting speech systems from tampering and reinforcing compliance in regulated industries.
Legal and Compliance Advantages
AI watermarking plays a crucial role in legal and regulatory contexts by providing verifiable ownership and traceable content attribution. As policies like the European Union’s AI Act increasingly emphasize AI transparency and content provenance, watermarking is becoming a recognized tool for meeting these standards [8].
By embedding attribution data that withstands extensive audio processing, watermarking supports audit trails and establishes ownership records that can be used in disputes over licensing or copyright. This is particularly important in sectors like finance, healthcare, and government, where using content authenticity verification tools to verify content integrity is essential for compliance with strict data security regulations.
Watermarking also aids in legal proceedings by creating a defensible chain of custody. Codec-integrated verification ensures that recovered audio has been transmitted and encoded faithfully, providing technical proof of ownership and content creation. This combination of traceability and security helps organizations meet regulatory requirements while safeguarding their intellectual property.
Implementing AI Audio Watermarking for Speech Systems
Preprocessing and Feature Extraction
To embed watermarks effectively, audio signals are first transformed into frequency representations like Short-Time Fourier Transform (STFT) or Mel-spectrograms. This allows watermarks to be embedded into specific frequency coefficients, making them more resistant to compression and filtering attacks [3][5].
Advanced systems like WMCodec take this a step further by extracting latent representations using speech encoders. The Attention Imprint Unit (AIU) plays a crucial role here, utilizing cross-attention mechanisms to combine watermark bits with speech features. This approach reduces the impact of quantization noise, ensuring accurate extraction even in low-bandwidth scenarios [5].
To prepare the system for real-world challenges, training data is augmented with simulated attacks such as resampling, echo addition, and low-pass filtering. This ensures that feature extraction can handle adversarial conditions [5][7]. For real-time applications, detectors operate at the sample level – down to 1/16,000 of a second – allowing precise localization of watermarks within continuous audio streams [4][7].
This meticulous feature extraction process lays the groundwork for embedding watermarks with precision.
Watermark Embedding Process
Once features are extracted, the watermark embedding process integrates the watermark seamlessly into the audio signal.
To ensure accuracy, the codec and embedding processes are optimized jointly. Separating these steps can lead to quantization errors, which degrade the watermark’s extractability. Systems like WMCodec address this by incorporating the codec directly into the training process, achieving over 99% extraction accuracy at just 6 kbps while embedding 16 bits of watermark data per second [5].
"The separation optimization of the watermarking from the codec’s quantization leads to error accumulation, which hinders the extractability and imperceptibility of the watermark." – Junzuo Zhou et al., Chinese Academy of Sciences [5]
To maintain audio quality, perceptual loss functions are employed, ensuring the watermark remains inaudible. For instance, WavMark can encode up to 32 bits of information per second, embedding details like user IDs, timestamps, and licensing data. These watermarks are designed to survive common audio manipulations, enabling multi-bit attribution that links audio outputs to specific users or model versions. This increases accountability in speech synthesis systems [1][5][7].
Real-Time Detection and Monitoring
Once embedded, the watermark’s integrity is continuously monitored to detect any tampering in real time.
Real-time monitoring relies on single-pass detector architectures, which analyze audio as it streams rather than processing entire files. In January 2024, Meta introduced AudioSeal in public demos for Audiobox and Seamless, serving around 100,000 users daily [7].
"AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed – achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications." – Robin San Roman et al., Meta AI [4]
Detection systems assign a probability score to each audio sample, applying thresholds to confirm watermark presence. This sample-wise approach allows precise identification of watermarked segments, even when mixed with non-watermarked or edited audio [7]. Time-domain watermarking schemes like AudioSeal deliver detection speeds up to 1,000 times faster than traditional frequency-based methods, ensuring the ultra-low latency required for enterprise environments that depend on immediate verification of speech authenticity.
sbb-itb-738ac1e
ScoreDetect Enterprise and Its Role in AI Audio Watermarking
Invisible and Non-Invasive Watermarking
ScoreDetect Enterprise offers a way to protect speech content with invisible watermarking that doesn’t compromise audio quality. Using perceptual loss functions and auditory masking, the system ensures the watermarks remain undetectable to the human ear but are still identifiable when needed [4][7]. This method integrates watermarks directly into the speech signal through advanced AI techniques, minimizing the impact of quantization noise and maintaining clarity even at lower bitrates [5]. For businesses relying on voice-driven platforms – like voice assistants or podcasts – this means safeguarding content without sacrificing the listening experience.
The technology also supports pinpoint localization of watermarks within continuous audio streams. This level of precision is especially important for industries such as media, healthcare, and government, where verifying the authenticity and origin of speech content is critical. This detailed embedding process also lays the foundation for additional verification measures, which are explored further below.
Blockchain Timestamping for Verification
Beyond embedding watermarks, ScoreDetect uses blockchain technology to create an unalterable record of ownership. Unlike traditional metadata, which can be easily removed, blockchain timestamping securely links audio to its source [3][5]. The system also embeds verification marks directly into the audio waveform, ensuring the content remains intact even after encoding or transmission [5][7]. By combining invisible watermarking with blockchain verification, this dual-layer system offers robust protection against tampering.
For industries like legal, finance, and research, this verification provides a reliable way to resolve copyright disputes while maintaining confidentiality. These measures work seamlessly alongside automated monitoring tools, which are discussed in the next section.
Automated Takedown and Monitoring
ScoreDetect’s automated monitoring system excels at identifying unauthorized use of speech content online, achieving a 95% success rate even against advanced countermeasures. Its real-time detection capabilities are built on fast, single-pass architectures commonly used in enterprise audio watermarking [4][7]. Once unauthorized use is detected, the system can automatically issue delisting notices, with a success rate exceeding 96%.
What sets this system apart is its precision – sample-level detection can identify unauthorized content down to 1/16,000 of a second [4][7]. With integration into over 6,000 web apps through Zapier, ScoreDetect enables businesses to automate workflows for monitoring, verifying, and protecting speech content at scale, eliminating the need for manual oversight.
Future of AI Audio Watermarking in Speech Systems
Current Challenges
AI audio watermarking faces some tough hurdles, particularly when it comes to robustness. A March 2025 study by the University of Hawaii and Michigan State revealed that 8 new black-box attacks could successfully strip watermarks from all 9 cutting-edge schemes tested across 22 watermarking systems and 109 configurations [3].
"None of the surveyed watermarking schemes is robust enough to withstand all tested distortions in practice." [3]
AI-driven distortions, like those from voice conversion or text-to-speech models that regenerate audio, make watermark removal even easier. Physical re-recording is another method that bypasses current watermarking techniques entirely. Compounding the problem is the so-called "unpatchable" issue: once a watermarked model is made public, any discovered vulnerabilities remain permanent, threatening its long-term usefulness [3].
Another challenge is the fidelity trade-off – stronger watermarks often reduce audio quality, which can be noticeable to listeners. Moreover, these systems sometimes show performance inconsistencies, with varying results across different language groups and biological sexes [6]. Beyond removal attacks, there’s also the risk of forgery, where unwatermarked audio is falsely labeled as AI-generated. This could harm the credibility of genuine human creators [6].
These weaknesses highlight the urgent need for more resilient watermarking solutions.
Upcoming Developments
Despite these challenges, new approaches are paving the way for stronger watermarking. One promising innovation is parameter-level watermarking. Unlike traditional methods that embed marks in the audio output, techniques like P2Mark embed watermarks directly into the model’s weights, making them nearly impossible to remove [2].
Another breakthrough comes from end-to-end joint optimization. Systems like WMCodec integrate compression and watermark embedding into a single process, reducing the noise that typically lowers watermark accuracy. This method achieves over 99% extraction accuracy at 6 kbps bandwidth, even under common attacks [5]. Meanwhile, the WM-LoRA adapter allows developers to update watermark information without needing to retrain the entire model – an essential feature for managing intellectual property and version control [2].
Detection speed is also improving at an incredible pace. AudioSeal, for instance, uses a single-pass architecture that processes audio up to 1,000 times faster than older tools like WavMark. It can detect watermarked segments at an incredibly granular level – down to 1/16,000th of a second – within longer audio streams, making real-time monitoring at scale a reality [4][7].
Applications Beyond Speech Systems
These advancements in watermarking aren’t just limited to speech systems – they’re finding use in other areas like music and fraud prevention.
In 2023, the music industry was shaken when AI-generated songs mimicking artists like Drake and The Weeknd went viral on social media. This highlighted the urgent need for tools to detect and protect intellectual property in music [3]. Today, technologies initially designed for speech watermarking are being adapted to safeguard music and environmental sounds, ensuring authenticity across all types of digital audio [7].
Cybersecurity and fraud prevention are also key areas where watermarking is making an impact. Voice cloning scams have already caused significant losses. For example, attackers used AI-generated voice deepfakes to impersonate a CEO and steal $243,000 in one incident [3]. Watermarking can act as a defense mechanism, helping to prevent these kinds of impersonation attacks in both corporate and financial settings.
From research labs to real-world applications, watermarking technology is now being deployed across industries like media, entertainment, healthcare, and government. As the need to verify audio authenticity grows, these tools are becoming essential in protecting digital content and combating fraud.
Conclusion
AI audio watermarking has become a crucial tool for safeguarding speech systems against threats like voice cloning, deepfakes, and unauthorized distribution. By embedding invisible identifiers directly into audio signals, it provides a proactive layer of defense far superior to traditional detection methods. Modern frameworks ensure watermark verification is both highly accurate and fast – essential qualities as organizations face increasingly sophisticated audio tampering threats.
The applications of this technology go far beyond basic detection. Industries such as healthcare, finance, government, and media rely on watermarking to confirm audio authenticity, protect intellectual property, and comply with new regulatory demands. Even under intense audio manipulation, error rates remain impressively low, ensuring the reliability of these watermarks.
ScoreDetect Enterprise builds on these advancements by offering a comprehensive solution for audio protection. Its platform combines invisible watermarking, blockchain-based timestamping, and automated takedown capabilities. The blockchain integration provides verifiable proof of ownership, addressing legal and compliance challenges head-on. Meanwhile, its intelligent web scraping feature – boasting a 95% success rate – enables organizations to identify and safeguard their audio content at scale, all without sacrificing audio quality.
The risks are very real: voice cloning scams have already caused significant financial damage, and AI-generated audio continues to blur the distinction between genuine and synthetic speech. While no watermarking system can claim to be completely impervious – a 2025 study confirms that no approach is 100% resistant to all types of attacks – a multi-layered strategy combining watermarking, monitoring, and enforcement offers the strongest protection currently available [3]. These innovations not only secure audio content but also help rebuild digital trust in an era of widespread synthetic media.
Whether you’re securing speech recognition systems, protecting voice-driven applications, or managing digital audio assets, AI audio watermarking has transitioned from a "nice-to-have" to an essential component for business continuity and legal compliance.
FAQs
How does AI audio watermarking protect against deepfake audio threats?
AI audio watermarking works by embedding hidden, durable signatures into speech content, offering a way to verify the authenticity and source of audio. These watermarks are crafted to withstand heavy editing or manipulation, ensuring they stay intact even after significant processing.
This technology provides an added layer of protection, enabling content creators and platforms to track and identify synthetic speech. By embedding markers that can’t be easily removed and don’t affect audio quality, AI audio watermarking helps combat threats like voice impersonation and misinformation. It ensures synthetic audio can be reliably differentiated from real human speech.
What makes it challenging to preserve audio quality when embedding watermarks?
Preserving audio quality while embedding watermarks is tricky because the process can introduce slight distortions or noise, potentially impacting the listening experience. The challenge lies in ensuring the watermark is undetectable to listeners while being strong enough to withstand typical audio changes like compression, filtering, or added noise.
Balancing durability and sound quality is no easy task. Techniques designed to resist tampering often risk making the watermark audible, while those prioritizing sound clarity may not hold up against modifications. Advanced approaches, such as AI-powered or neural network-based watermarking, aim to address both issues. However, achieving this requires highly sophisticated algorithms and precise adjustments.
How does blockchain work with AI audio watermarking to ensure content authenticity?
Blockchain technology works hand-in-hand with AI audio watermarking by adding a secure verification layer to safeguard intellectual property. When an audio watermark is embedded into a piece of content, a checksum or digital signature of the watermarked file can be logged onto a blockchain. This creates a permanent, tamper-resistant record that confirms the content’s authenticity and origin.
Because these records are stored on a decentralized ledger, it becomes nearly impossible for anyone to alter the watermark or forge the content without being detected. This combination is particularly useful in areas like voice authentication, digital rights management, and fighting content piracy. It ensures both traceability and the integrity of AI-generated audio, making it a powerful tool for protecting sensitive applications.