AI-powered multimodal similarity is transforming how media libraries manage, protect, and monetize digital content. By analyzing and linking content across formats – like images, videos, audio, and text – AI can identify assets even after heavy modifications, such as cropping, re-encoding, or paraphrasing. This technology helps organizations save time, enhance rights enforcement, and recover lost revenue.
Key Takeaways:
- What it does: Tracks and identifies content across formats, even when altered.
- How it works: Converts media into digital fingerprints for easy comparison and detection.
- Applications: Improves search, organizes assets, prevents piracy using content matching algorithms, and boosts monetization.
- Tools in action: Systems like InCyan’s Idem achieve 99% accuracy in detecting modified content.
AI-driven solutions are becoming indispensable for media libraries, ensuring better control and profitability in a rapidly evolving digital landscape.
AI Multimodal Similarity: How It Protects & Monetizes Media Assets
What Is Multimodal Similarity in AI?
Defining Multimodal Similarity
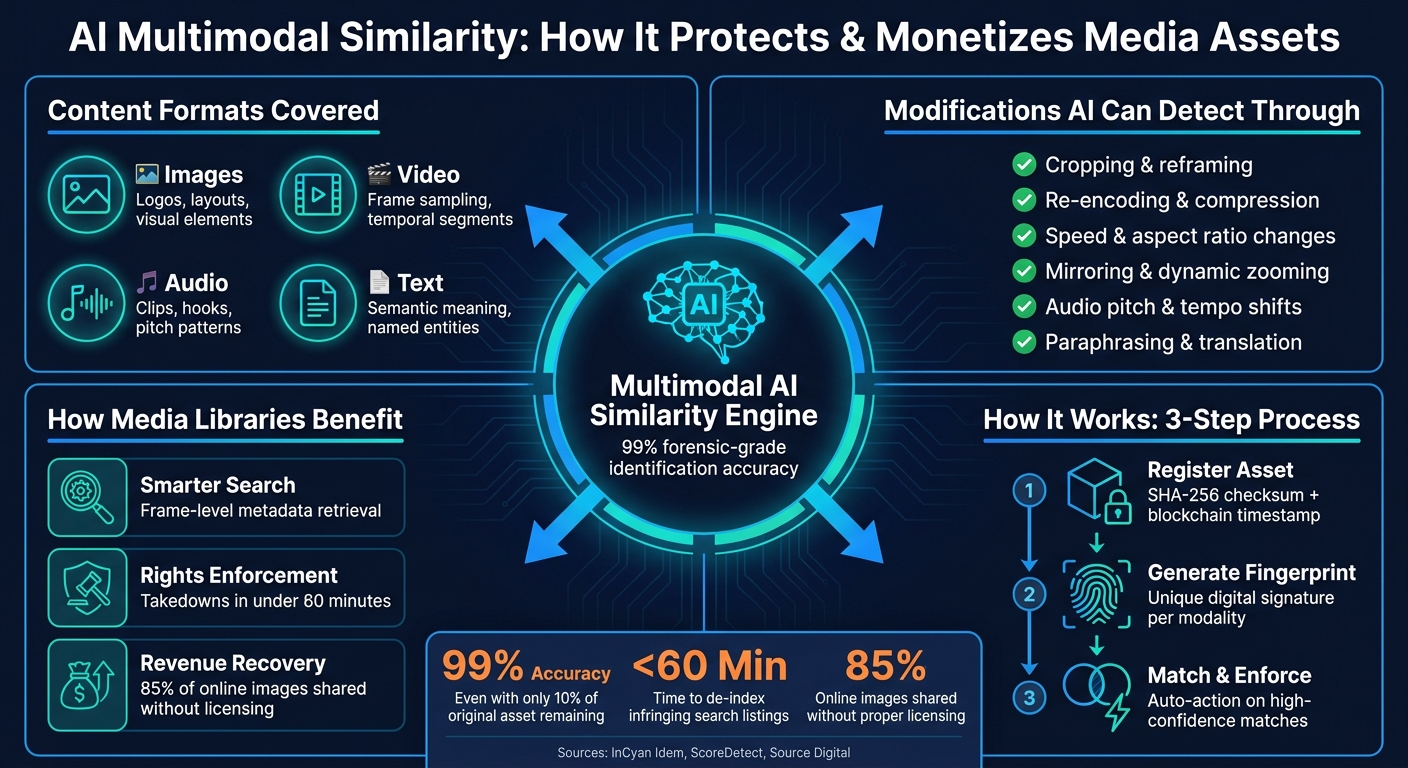
Multimodal similarity in AI refers to the ability to recognize the same content across different formats. For instance, a photograph, a video clip, an audio recording, and a text transcript can all represent the same piece of information. Multimodal AI achieves this by converting these varied formats into a shared embedding space – a kind of universal language that allows the system to compare them directly, no matter the file type [4].
This process involves assigning a unique digital signature to each asset. These signatures capture essential features of the content, making it possible to identify the asset even after significant changes, such as heavy edits or format shifts [2]. This approach overcomes many of the challenges faced by tools that focus on just one type of content.
How It Differs from Single-Modality Analysis
Single-modality systems are limited to analyzing one type of content at a time. For example, an audio fingerprinting tool works only with sound, while a hash-based image tool can only process visual content. The moment content transitions between formats – like when a book excerpt is read aloud in a podcast or a video is broken into screenshots – these systems lose their ability to track it [4][6].
This is where multimodal analysis shines. It connects different formats, linking, for example, a scanned PDF page, a social media quote, and a compressed audio recording back to the same original asset. The table below highlights how AI processes and adapts to various formats:
| Modality | What AI Analyzes | What It Survives |
|---|---|---|
| Images | Logos, visual elements, layout patterns | Cropping, filters, low-resolution reposts |
| Video | Temporal segments, frame sampling, embedded audio | Speed adjustments, aspect ratio changes, re-encoding |
| Audio | Short clips, hooks, riffs | Pitch shifts, tempo changes, background noise |
| Text | Semantic meaning, named entities | Paraphrasing, translation, formatting changes |
Use Cases in Media Libraries
The technical capabilities of multimodal similarity have a huge impact on managing media libraries. By clustering related assets – like a video clip, its thumbnail, and its audio track – into a single "incident", multimodal AI reduces the overwhelming volume of signals that reviewers need to process [4]. This not only cuts down on manual workload but also provides a clearer view of how content is being shared and repurposed across the internet, social media, and peer-to-peer platforms.
In addition to improving organization, multimodal similarity enhances search functionality, content recommendations, and rights enforcement. A clear example is InCyan’s Idem, a tool specifically built for robust multimodal matching. It helps media libraries protect and monetize their assets effectively [2]. For organizations managing millions of digital files, this level of precision and adaptability is essential to maintaining control over their content.
sbb-itb-738ac1e
Key Technologies Behind Multimodal Similarity
Cross-Modal Embedding Models
At the heart of multimodal similarity lies the embedding model – a system designed to translate various formats into a shared numerical space. This process assigns each asset a distinct digital signature, enabling recognition even after significant alterations. For instance, InCyan’s Idem can pinpoint matches even when only a small fragment of the original asset is present – something most conventional tools struggle to achieve [2][3]. Once assets are mapped into this vector space, the focus shifts to extracting precise features across different formats.
Feature Extraction Across Formats
Different content types require unique methods for feature extraction. The elements that make an image identifiable are vastly different from those that define an audio file. Instead of revisiting earlier format-specific breakdowns, the key takeaway here is the role of extraction algorithms in producing actionable results. Each analysis generates a confidence score and a risk score, which help determine whether immediate action is necessary or if further review is required [4].
With these features in hand, the next hurdle is searching through massive databases of assets efficiently.
Scalable Similarity Search
Using the digital signatures created earlier, scalable search techniques enable rapid matching across vast asset libraries. Modern systems achieve this through advanced indexing, which allows for quick and precise matching of asset fingerprints without the need to compare every file individually [2].
To ensure these fingerprints remain secure and verifiable, InCyan employs blockchain-based copyright enforcement storage. Instead of storing entire media files on-chain, the system records a cryptographic checksum of each asset’s fingerprint. This approach provides tamper-proof proof of ownership while keeping storage costs low [5]. Automated processes handle high-confidence matches, sending them directly to enforcement actions, while medium-confidence results are flagged for human review. This balance ensures accuracy and reliability, even when operating at an enterprise scale [4].
How AI Benefits Media Libraries
Efficiency in Day-to-Day Operations
Managing a massive media library by hand can be overwhelming and time-consuming. AI steps in to streamline this process by automating repetitive tasks. For example, when a new asset is added, AI standardizes it into a unified schema, applies modality-aware tagging (like detecting logos or layouts in images, aligning frames in videos, or identifying pitch and tempo shifts in audio), and consolidates near-duplicates into single entries. This reduces the workload for reviewers and boosts operational efficiency, paving the way for smarter search capabilities and tailored recommendations [4].
Better Discovery and Content Recommendations
In large media collections, finding the right content quickly is essential. AI improves search accuracy by normalizing metadata across different formats, making it possible to retrieve content with precision – even down to individual video frames [4][8].
"Contextual metadata stands as the foundation of next-generation video intelligence." – Source Digital [8]
This kind of metadata-driven approach ensures users can discover the exact content they need, whether for creative projects or business purposes.
Rights Management and Anti-Piracy
AI doesn’t just make operations smoother – it also plays a critical role in protecting media assets. For instance, InCyan’s Idem technology can identify content even if only 10% of the original remains, handling alterations like cropping, speed changes, color tweaks, and added noise [2][3]. Once a match is found, AI generates detailed reports complete with timestamped screenshots, cryptographic hashes, and a secure chain of custody – meeting legal standards for enforcement [3][4].
Additionally, Tectus embeds invisible watermarks that survive re-encoding and compression, anchoring ownership claims with blockchain-based timestamps. This system can identify infringing content and have it de-indexed from search engines in under an hour [2].
These tools not only safeguard assets but also create opportunities for better monetization strategies.
Monetization Through Archival Content
AI also helps media libraries unlock hidden revenue from their archives. Many organizations have valuable content sitting unused in storage. With multimodal similarity analysis, AI can identify assets with high reuse potential, match them to current licensing opportunities, and flag formats that drive high engagement. It can even pinpoint older assets that are being used online without authorization.
InCyan’s Certamen platform provides a clear view of how images and videos are performing across the digital news landscape. This data eliminates guesswork, showing exactly which assets are generating engagement. Armed with this insight, rights holders can make informed licensing decisions and recover revenue from content that might otherwise go unnoticed [2].
Scalability and Implementation Challenges
Processing Large Volumes of Assets
When scaling multimodal similarity analysis from thousands to hundreds of millions of assets, both technical and financial hurdles can escalate quickly. At the billion-asset level, even minor inefficiencies in indexing or storage can snowball, making content identification extremely expensive without a well-optimized system architecture [7].
One major issue is the sheer volume of data, with millions of detection signals generated every day. The solution? Clustering. By grouping near-duplicates and related appearances of the same asset into a single "incident", analysts can review one consolidated case instead of sifting through thousands of separate sightings. This approach reduces the workload while still preserving the critical evidence needed to address misuse [4]. The next challenge is ensuring these systems remain accurate, even when content undergoes significant alterations.
Maintaining Accuracy Against Content Modifications
Once content leaves a media library, it rarely stays untouched. It might be cropped, re-encoded, compressed, mirrored, sped up, or embedded into other media. Traditional hash-based tools struggle with even minor changes. However, AI-driven fingerprinting tackles this differently by extracting unique features from the content itself, creating a signature that holds up under heavy transformations [2].
Here’s how modern AI handles common content modifications:
| Modification Type | AI Capability |
|---|---|
| Cropping & reframing | Matches partial fragments to the original asset |
| Re-encoding & compression | Retains effectiveness despite heavy quality loss [2][6] |
| Speed & aspect ratio changes | Aligns temporal segments to detect partial copies [4] |
| Mirroring & dynamic zooming | Maintains accuracy despite visual distortions [6] |
| Audio pitch & tempo shifts | Handles pitch shifts, tempo changes, and background noise [4] |
These advanced systems can achieve forensic-grade identification accuracy of up to 99% [2]. However, this level of precision depends on using separate, modality-specific models tailored for images, videos, audio, and text.
Governance and Proof of Ownership
Detection and matching are just the beginning – ensuring the integrity of evidence is just as critical. For compliance, every detection must include verifiable proof, such as screenshots, HTML snapshots, cryptographic hashes, and timestamps. This creates a clear chain of custody, making enforcement actions credible in court or during takedown requests [4].
Proving original ownership is especially important in a world where AI-generated content and deepfakes make authenticity harder to verify. ScoreDetect addresses this challenge with blockchain-based timestamping. When an asset is registered, ScoreDetect generates a SHA-256 checksum and records it on the blockchain – without storing the actual file. This creates an immutable, time-stamped proof of ownership [1].
"ScoreDetect allows you to easily create verification certificates for your digital content. These certificates provide proof of authenticity and enhance your copyright protection." – ScoreDetect [1]
These certificates include the blockchain transaction URL, the public ledger record, and the file hash. This setup allows any third party to independently verify authenticity without needing access to the original file. For media organizations navigating regulations like the EU’s Digital Services Act or Article 17 of the Copyright Directive, this cryptographic certainty is becoming a practical necessity [6].
Multimodal AI Explained: Text, Images, Audio, and Video Together
Conclusion: What AI Multimodal Similarity Means for Media Libraries
AI-driven multimodal similarity has become a game-changer for media libraries managing large-scale assets. The capability to match images, videos, audio, and text – even after significant transformations – plays a critical role in how organizations protect, manage, and monetize their content. With 85% of online images being shared without proper licensing [9], the financial implications are immense. This underscores the need for a unified approach that ties together protection and monetization strategies.
InCyan’s ecosystem offers an all-in-one solution, simplifying discovery, identification, prevention, and enforcement. Its tools work seamlessly to address every stage of content protection. For instance, Idem achieves 99% forensic-grade identification accuracy, even when only 10% of the original asset remains [2]. Indago can remove infringing search listings in under 60 minutes [2], while Tectus embeds invisible watermarks that resist removal attacks like compression, cropping, and re-encoding. Together, these tools ensure end-to-end content protection without the inefficiencies of fragmented workflows.
Accurate fingerprinting, blockchain timestamping, and continuous monitoring also create new opportunities for monetization. Rights holders can not only identify unauthorized usage but also recover lost revenue. ScoreDetect, for example, uses blockchain to record a SHA-256 checksum on the SKALE network with zero gas fees. This process creates an unchangeable ownership record, strengthening legal claims while enhancing SEO through improved Google E-E-A-T signals [1].
"In a world rampant with AI and deepfakes, ScoreDetect helps you stand out as an authority with authenticity." – ScoreDetect [1]
To fully leverage these advancements, the strategy is straightforward: register assets at creation, use modality-specific AI models for accurate matching, and secure provenance with blockchain from the outset. These steps directly address the challenges of rights enforcement, streamlined workflows, and revenue recovery highlighted throughout this article.
FAQs
How does multimodal similarity match content across image, video, audio, and text?
Multimodal similarity leverages advanced AI to generate compact 512-dimensional vector fingerprints for digital assets. These fingerprints are crafted using modality-specific models that analyze distinct characteristics: visual patterns in images, temporal segments in videos, audio frequencies, and the semantics of text. This approach allows for the recognition of assets even after transformations such as cropping, re-encoding, or other alterations.
The fingerprints are then organized using Approximate Nearest Neighbor search, enabling efficient clustering of similar assets. InCyan’s Idem engine takes this a step further by offering enterprise-level protection, linking derivative versions of assets into unified incidents for comprehensive tracking and management.
What modifications can AI fingerprinting still detect in content?
AI fingerprinting, driven by Idem from InCyan, is designed to track and identify content even when heavily altered. It can recognize images that have been cropped, filtered, or resized; videos that have undergone speed adjustments, re-encoding, or compression; and audio modified with pitch changes or added background noise. For text, it uses semantic analysis and entity recognition to detect content, even if it’s been paraphrased or translated. This technology ensures reliable identification across multiple media types.
How does blockchain timestamping prove ownership without storing the file?
Blockchain timestamping works by creating a unique digital fingerprint, known as a checksum, of your file and recording it on an unchangeable ledger. This process offers cryptographic proof that your asset existed at a specific moment in time – without the need to store the original file. By providing a tamper-proof and time-stamped record, platforms like ScoreDetect allow you to confirm ownership and establish priority over your intellectual property, all while keeping your master files safe and private.

