Cloud-native frameworks simplify managing diverse data types – like text, images, video, and audio – by unifying them under a single system. This eliminates the need for separate tools and enables efficient analysis across formats. With unstructured data growing rapidly (accounting for 80–90% of enterprise data), these frameworks help businesses handle massive data volumes while reducing costs and improving processing speeds.
Key Takeaways:
- Unified Systems: Manage text, images, videos, and audio through one API.
- Scalability: Separate compute and storage layers for efficient resource use.
- Real-Time Processing: Streamline CPU and GPU tasks for faster results.
- Security: Protect data with watermarking, blockchain timestamping, and zero-trust access.
These frameworks are transforming data management for enterprises, enabling advanced AI applications and better insights from multimodal data.
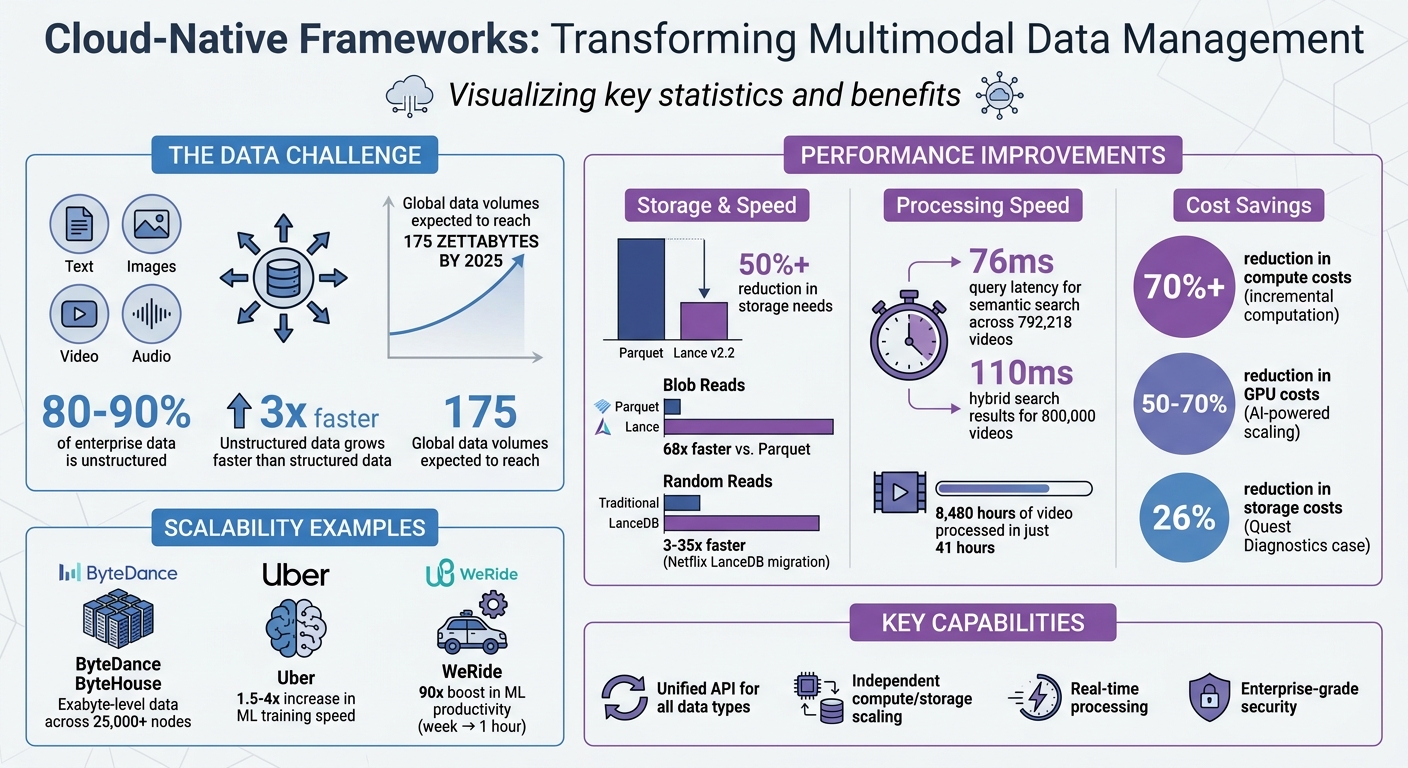
Cloud-Native Multimodal Data Framework Benefits and Performance Statistics
Benefits of Cloud-Native Frameworks for Multimodal Data
Managing Multiple Data Types in One System
Bringing together text, images, video, and audio into a single platform simplifies operations. It eliminates the hassle of juggling separate storage systems. When all data is stored under a unified namespace – like Amazon S3 or Azure Blob Storage – tasks like backups, access control, and encryption become much easier to manage. Plus, unified management ensures operational consistency, even with the differences in how various data types are compressed.
Cloud-native frameworks enable AI systems to analyze relationships across multiple data types. For instance, instead of viewing a customer service call as just audio or a product review as only text, these frameworks integrate visual, audio, and textual data to provide a more complete understanding of the situation [4].
Some modern multimodal formats, like Lance v2.2, highlight the advantages of this approach. They can reduce storage needs by over 50% and offer up to 68× faster blob reads compared to older formats like Parquet [12]. For teams managing massive datasets, this translates to reduced cloud storage costs and quicker data access. This unified system naturally supports scalable designs while keeping operations cost-efficient.
Scalability and Cost Control
Building on unified storage, cloud-native frameworks take scalability and cost management to the next level. By separating compute and storage layers, these architectures allow each to scale independently based on demand. A great example is ByteDance’s ByteHouse system, which handles exabyte-level data across more than 25,000 nodes while supporting over 400 external services, all with millisecond-level retrieval times [9]. This separation ensures that organizations can scale processing as needed without wasting resources on idle storage or unused compute power.
Declarative platforms like Pixeltable also help cut costs by updating only the data that has changed, reducing compute costs by over 70% [10].
AI-driven scaling makes things even more efficient. ScaleOps, for example, implemented an AI-powered infrastructure on Kubernetes, cutting GPU costs for enterprise-level large language models by 50–70% through automated optimizations across hybrid cloud setups [11]. Uber also saw a 1.5× to 4× boost in training speeds and better GPU utilization after migrating its machine learning platform to Kubernetes.
Gerald Venzl, VP of Dev & AI Initiatives at Oracle, shared, "Traditional cloud native setups rely on rule-based autoscaling, but AI models can predict demand spikes using historical data, optimizing resource usage in real-time" [11].
Real-Time Data Processing and Analysis
Cloud-native frameworks shine when it comes to real-time processing. By breaking down compute silos, they streamline CPU-heavy tasks and GPU-driven model inference into a single, efficient pipeline [3]. This integration reduces latency and ensures hardware is used to its fullest potential by cutting out I/O bottlenecks.
Adrian Li-Bell, Member of Technical Staff at Anyscale, stated, "With Anyscale, our researchers can just write code without worrying about the underlying infrastructure" [3].
Event-driven ingestion, powered by Change Data Capture (CDC) tools like Amazon S3 and AWS Lambda, allows systems to kick off feature extraction and indexing as soon as new multimodal files arrive [8]. Large-scale tests have shown impressive results: semantic k-NN search across 792,218 videos achieved query latencies of about 76 ms, while hybrid searches combining vector similarity with keyword matching delivered results in under 110 ms for nearly 800,000 videos [2]. Additionally, one cloud-native pipeline managed to process 8,480 hours of video in just 41 hours [2]. These capabilities open the door for applications like live translation, autonomous vehicles, and interactive customer support systems.
sbb-itb-738ac1e
Technologies That Power Cloud-Native Frameworks
Kubernetes and Containerization
Kubernetes has become a cornerstone for modern multimodal data systems, acting as the orchestration layer for the PARK stack (PyTorch, AI frontier models, Ray, and Kubernetes). It handles cluster-level resource management, enabling the parallel processing of diverse data types like video, images, audio, and text [14].
Containerization plays a key role by isolating GPU-intensive tasks from CPU-heavy processes [3]. This separation allows Kubernetes to manage workloads more effectively. For instance, CPUs can handle metadata transformations, while GPUs focus on tasks like embedding computation and video decoding [14].
Tools like Kubeflow simplify the lifecycle management of multimodal models. They handle everything from experiment tracking to versioning data fusion strategies [13]. With global data volumes expected to hit 175 zettabytes by 2025 – much of it in multimodal formats like sensor data and video – automation at this level isn’t just helpful; it’s essential [6].
Building on this, service meshes add another layer of efficiency by improving microservices communication.
Service Meshes for Microservices Communication
Service meshes such as Istio and Linkerd are crucial for managing secure communication between microservices. They provide inter-service encryption, secure channels using mTLS, and advanced traffic routing [15][16].
In the context of multimodal systems, service meshes enforce encryption for sensitive datasets and support routing methods like A/B testing or canary releases when deploying new AI models [16]. This is especially important given that 45% of organizations cite misconfigurations as a major cause of cloud-native security issues. By automating policy enforcement, service meshes significantly reduce these risks [17].
"Observability stacks (Prometheus, OpenTelemetry) and service meshes (Istio, Linkerd) provide the visibility, security and control needed to run AI applications in production." – Cloud Native Now [16]
These tools pave the way for distributed processing engines, which are essential for handling massive datasets.
Distributed Processing with Ray and Spark
When it comes to processing large multimodal datasets, Ray and Apache Spark are indispensable. Each has its strengths: Ray excels in unified CPU and GPU processing within a single pipeline, while Spark is ideal for large-scale batch processing and structured metadata management.
Traditional setups often separate CPU-bound tasks (handled by Spark) from GPU-bound inference (handled by containerized Python), creating "compute silos" that add latency and drive up costs [3]. Ray eliminates these silos by streaming data continuously through pipeline stages, maintaining high CPU and GPU utilization [3].
A real-world example? In August 2025, Netflix deployed a Media Data Lake using LanceDB and Ray. This system unified petabytes of media assets for machine learning pipelines, enabling large-scale multimodal search and feature engineering [18].
Meanwhile, Spark remains a go-to for batch processing. Its compatibility with tools like ai_query() allows for automatic scaling across clusters [7]. Ray also offers built-in preemption recovery, making it possible to run workloads reliably on discounted spot instances, cutting costs without compromising performance [3].
Scaling Multimodal Data Curation with Ray and LanceDB | Ray Summit 2025
Protecting Multimodal Data in Cloud-Native Environments
When managing diverse datasets in cloud-native systems, security is paramount. These strategies help maintain the integrity of multimodal data while leveraging unified data management.
Invisible Watermarking and Blockchain Timestamping
Cloud-native multimodal systems face the threat of data poisoning, where attackers subtly manipulate data to compromise AI models. To counteract this, organizations can use cryptographic validation techniques like signatures, MACs, and SHA-256 checksums to verify the integrity of training data[1].
Blockchain timestamping adds another layer of protection by providing immutable proof of ownership without requiring the storage of actual digital assets. By capturing cryptographic checksums, organizations can establish verifiable creation dates and ownership records. This method is particularly useful for multimodal datasets, as handling large files – like an hour of 4K video at 60fps, which can exceed a terabyte – can overwhelm traditional storage and backup systems[1].
Tools like InCyan’s Tectus offer invisible watermarking for images, videos, and audio. These watermarks remain intact even after compression, cropping, or other alterations, ensuring ownership proof is preserved. Meanwhile, ScoreDetect allows users, both technical and non-technical, to timestamp their content on the blockchain, creating verifiable certificates of ownership.
Another critical component is content-addressable storage, which uses cryptographic hashes to identify objects. This enables routine checksum verification to detect any corruption or tampering[1]. To future-proof data security, organizations should also implement post-quantum cryptography (PQC). This protects against "harvest now, decrypt later" attacks, where encrypted data is stolen today for decryption using future quantum computing capabilities[19]. These measures integrate seamlessly with cloud-native workflows, ensuring end-to-end data integrity.
Content Monitoring and Automated Takedown Systems
With 70% of organizations accelerating their cloud migration in 2025 (up from 63% in 2024), the attack surface for unauthorized content use has grown significantly[19]. A zero-trust approach is now critical, requiring verification of every access request, regardless of the network’s location[19][20].
Beyond watermarking, advanced content monitoring tools play a crucial role in safeguarding data across different modalities. InCyan’s Idem delivers evasion-proof identification at scale, matching digital assets across multimodal databases – even when only 10% of the original content is present. This AI-driven platform can identify assets that have undergone transformations such as mobile edits or meme creation, which often defeat traditional detection methods. For combating search-based piracy, Indago de-indexes unauthorized content in under 60 minutes, cutting off access to illegal listings.
To further enhance security, organizations should adopt Data Security Posture Management (DSPM). This approach enables continuous discovery and classification of sensitive multimodal data, preventing "shadow data" – assets that escape security oversight[20][21]. Modality-specific access controls can ensure that raw audio and video files are limited to authorized personnel, while processed datasets remain accessible to machine learning engineers[1].
For high-value datasets, maintaining time-locked, immutable backups in air-gapped (offline) storage is essential. This protects against ransomware and supply chain attacks. It’s also vital to test recovery procedures for each data modality – successfully restoring text files doesn’t guarantee that video metadata or playback integrity will be preserved after recovery[1]. Regular testing, ideally on a quarterly basis, ensures readiness across all data types.
How to Implement Cloud-Native Frameworks for Multimodal Data
Building upon the strategies for unified data management and protection, implementing cloud-native frameworks involves focusing on architecture, optimizing data retrieval, and integrating security measures. This ensures both high performance and robust asset protection.
Building Multimodal Data Lakes
To manage diverse data types like text, images, audio, and sensor streams, unify them under a single object storage layer. Services like Amazon S3, Azure Blob Storage, or Google Cloud Storage make this possible, eliminating the complexity of managing separate silos for each data type[4][8].
However, traditional formats like Parquet often fall short when handling modern AI workloads. Netflix’s migration of its Media Data Lake to LanceDB in August 2025 is a great example. This shift addressed I/O bottlenecks, enabling random reads that were 3× to 35× faster[14].
"Multimodal AI has broken the assumptions of the traditional data lake: rows are huge, access is random, and GPUs can’t afford to wait on batch-era storage." – Ben Lorica, Gradient Flow[14]
Frameworks like Ray and Apache Spark can distribute compute-heavy tasks across clusters of CPUs and GPUs. Tools like lakeFS further enhance this setup by enabling version control, ensuring compliance with regulations like GDPR or HIPAA.
Once the data lake is established, the next focus is optimizing real-time data retrieval with vector databases and event-driven pipelines.
Using Vector Databases and Event-Driven Pipelines
Vector databases, such as Qdrant, Pinecone, and Milvus, act as the "hot" layer for real-time similarity searches, while object storage like S3 remains the primary source for embeddings and features[6][5]. This tiered architecture balances cost and performance, delivering sub-10ms latency for active queries while handling batch analytics with slightly higher latency (50–200ms)[6].
This approach is essential because unstructured data – like video, audio, and images – accounts for 80–90% of enterprise data and grows three times faster than structured data[6]. With cloud memory costs around $0.10/GB/month, storing all vectors in hot storage isn’t practical[6].
Event-driven pipelines make it possible to break down complex data into manageable features. For example, a 30-second video can yield multiple queryable elements: visual frames (via YOLO/SigLIP), face embeddings (via ArcFace), audio fingerprints (via CLAP), and transcripts (via Whisper)[6]. These features can then be queried and linked to other data, like matching video frames to a brand safety database using vector similarity[6].
Real-world applications demonstrate these advantages. WeRide, an autonomous driving company, saw a 90× boost in machine learning productivity after adopting LanceDB, reducing data mining time from a week to just an hour[12]. Similarly, CodeRabbit streamlined its infrastructure by consolidating vector storage and metadata management into a single LanceDB instance, enabling hybrid searches over code snippets[14][12].
For cost efficiency, reducing embedding dimensions (e.g., from 3072 to 1024) can cut storage costs by three times with minimal accuracy loss[2]. Additionally, resizing images to a maximum of 1,568 pixels when using models like Claude 3.7 Sonnet can further optimize performance and costs[7].
With a smooth pipeline in place, the next step is securing your data assets.
Using InCyan Tools for Content Protection
Once your multimodal data lake is operational, integrating InCyan’s tools can help safeguard your assets. InCyan’s Tectus enables invisible watermarking for images, videos, and audio, ensuring proof of ownership even after compression, cropping, or format changes.
For large-scale media management, InCyan’s Blueprint offers a centralized digital asset management platform that integrates seamlessly with their AI-driven content protection tools. This provides enterprise-level centralization, granular rights management, and eliminates the need for multiple separate solutions.
InCyan’s Idem ensures evasion-proof identification across multimodal databases. It can match assets even if only 10% of the original content remains, making it effective against modifications like mobile edits or cropping. For textual content, Txtmatch automates plagiarism detection with forensic precision, comparing content against a proprietary database.
Finally, ScoreDetect enhances copyright protection by offering blockchain-based digital watermarking and timestamping. It captures cryptographic checksums without storing the actual digital assets, producing verifiable certificates of ownership. This tool integrates with over 6,000 web apps via Zapier and includes a WordPress plugin for automatic timestamping, which not only protects content but also improves SEO by offering verifiable proof of authorship.
Conclusion
Cloud-native frameworks have reshaped how organizations manage multimodal data – spanning text, images, video, audio, and sensor streams – by offering a unified platform that simplifies operations and replaces fragmented tools. These frameworks allow enterprises to scale resources independently, process data in real time, and reduce compute costs by over 70% using incremental computation[10]. For modern businesses, these capabilities are game-changers.
Examples from real-world use cases highlight their impact. In January 2026, Uber reported a 1.5- to 4-times increase in training speed by transitioning its machine learning platform to Kubernetes[11]. ByteDance leveraged ByteHouse to manage exabyte-scale data across more than 25,000 nodes[9]. Similarly, Quest Diagnostics consolidated its infrastructure on a multimodal platform, cutting storage costs by 26%[22].
Performance and cost efficiency aside, securing multimodal assets is equally important. InCyan offers a comprehensive suite of tools for this purpose. Solutions like Tectus (invisible watermarking), Idem (evasion-proof matching), and Blueprint (centralized asset management) provide enterprise-grade security for all data types. ScoreDetect adds another layer with blockchain-based timestamping, enabling verifiable proof of ownership without storing the actual content. Plus, its integration with over 6,000 web apps via Zapier ensures seamless compatibility.
FAQs
What’s the best way to model multimodal data in an object-storage data lake?
To effectively manage multimodal data in an object-storage data lake, a well-structured and scalable strategy is essential. Start by breaking down complex objects into searchable features. These features can then be distributed across tiered storage systems, ensuring both efficiency and accessibility.
For retrieval, rely on multi-stage pipelines that streamline the process. Organize your data by modality and apply specialized feature extractors tailored to each type of data. For instance, use face detection algorithms for images or speech recognition tools for audio files.
This approach not only optimizes storage but also enables semantic searches and simplifies the management of diverse datasets. It’s an ideal setup for supporting AI-driven projects and enterprise-level applications.
When should I use a vector database versus keeping embeddings in object storage?
A vector database is ideal for performing similarity searches and retrieving high-dimensional embeddings in real-time. This makes it a great fit for handling large multimodal datasets, such as images or videos. It’s especially useful for tasks like semantic search and content matching, where speed and accuracy are crucial.
On the other hand, object storage is better suited for situations where retrieval speed isn’t a top priority. It provides a cost-effective and durable solution for storing raw or processed data. This type of storage is commonly used for tasks like archiving or batch processing, where immediate search capabilities aren’t necessary.
How can I prove ownership and detect tampering of multimodal datasets?
ScoreDetect offers a powerful way to establish ownership and spot tampering in multimodal datasets. The platform uses invisible watermarking and blockchain-based checksum timestamping to create verifiable proof of ownership and identify any alterations. Beyond that, it simplifies the process of uncovering unauthorized use, analyzing those findings, and even generating takedown notices. This makes ScoreDetect a complete solution for protecting and managing multimodal data, especially in cloud-native environments.

