AI-powered multimodal matching transforms how diverse data types – text, images, audio, and video – are processed and connected. Unlike traditional methods that fail when content is altered, these systems use deep learning to identify patterns, enabling accurate detection even after changes like cropping, reformatting, or compression.
Key Points:
- Multimodal Matching: Unifies data processing across formats, creating digital "fingerprints" for cross-format comparisons.
- Accuracy: Identifies content with up to 99% precision, even if only 10% of the original remains.
- Core Technologies: Embedding models tailored for each data type and vector databases for fast, scalable searches.
- Blockchain Integration: Tools like ScoreDetect verify ownership via blockchain timestamps for secure copyright protection.
- Applications: Protects digital assets through identification, enforcement, and monitoring, using tools like InCyan’s Idem and Indago.
This approach is reshaping large-scale content protection, enabling efficient workflows and stronger control over digital assets.
Core Technologies Behind Multimodal Matching
Embedding Methods for Multimodal Data
To make sense of multimodal data, these systems transform assets into compact numerical vectors – essentially AI-generated fingerprints. These vectors capture key characteristics of the data while remaining resilient to changes like format transformations or noise. Each type of data, or modality, gets its own tailored model. For example, models might focus on temporal alignment for video, pitch analysis for audio, or semantic similarity for text. This specialized approach ensures high levels of accuracy in identifying and matching data [1].
These embeddings lay the groundwork for building scalable and efficient search systems.
Scalable Architectures for Multimodal Matching
When working with databases containing billions of assets, speed and precision become non-negotiable [5]. Vector databases, designed for similarity searches, rely on approximate nearest neighbor (ANN) algorithms to quickly locate the closest matches. High-confidence matches are sent directly to automated processes, while medium-confidence results are flagged for human review [2]. This setup strikes a balance between automation and oversight, ensuring smooth operations even at massive scales.
Efficient search systems are the backbone of managing large volumes of multimodal data effectively.
Optimization Methods for High-Volume Workflows
Optimizing workflows means finding the right balance between speed and accuracy. For instance, confidence-based triage allows high-confidence matches to be handled automatically, while edge cases are flagged for manual review. Another key strategy is data minimization – storing hashes or redacted views instead of full raw files. This reduces storage needs and processing time. Blockchain-based timestamps add an extra layer of protection; tools like ScoreDetect, for instance, store cryptographic checksums on the blockchain rather than the assets themselves. With an average transaction time of 2.754 seconds on the SKALE network, this method reinforces ownership verification without risking exposure of the original content [3]. Deduplication rules also play a vital role, ensuring that minor changes, like URL variations or layout tweaks from recrawls, don’t result in redundant processing [2].
"Working with InCyan has completely transformed how we handle our media operations. The ability to centralize, secure and protect our content has turned a previously chaotic workflow into a streamlined process." – Director, BPI Limited [1]
sbb-itb-738ac1e
What is Multimodal AI? How LLMs Process Text, Images, and More
Multimodal Matching in Content Protection
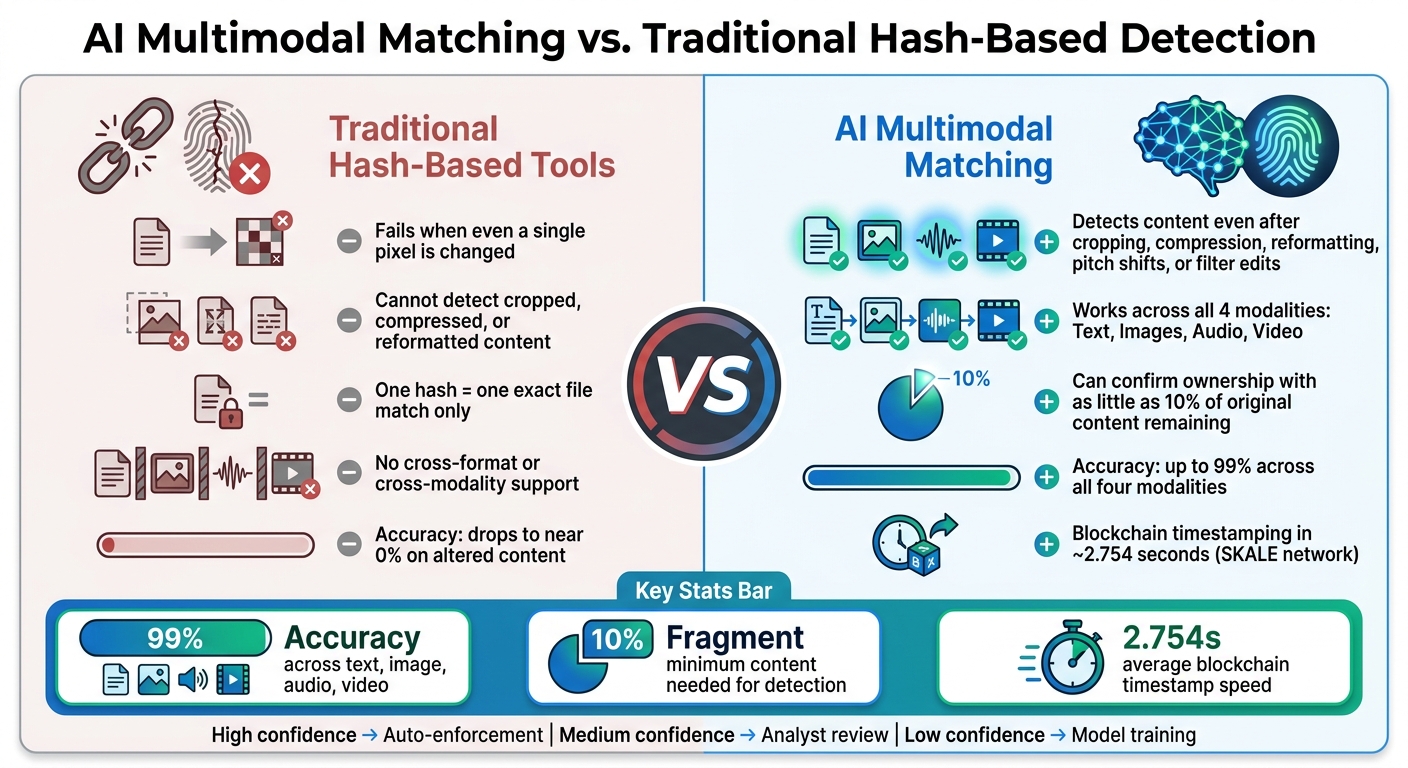
AI Multimodal Matching vs Traditional Hash-Based Content Protection
Detecting Ownership in Altered or Partial Content
Traditional hash-based tools fall apart when a file is altered – even a minor change, like tweaking a single pixel, results in a completely different hash, making detection nearly impossible. AI-powered multimodal matching, however, takes a completely different route by relying on digital fingerprints rather than exact file signatures.
Take InCyan’s Idem engine as an example. It generates unique digital fingerprints for images, videos, audio, and text, then matches them against a multimodal database – even when the content has been drastically modified. As mentioned earlier, Idem can confirm ownership even if just a small fragment of the original content remains [1][4].
This approach shines across different content types. For videos, Idem aligns temporal segments and combines frame sampling with audio analysis to catch partial copies. For audio, it identifies short clips or riffs even after pitch shifts or tempo changes. For images, it recognizes logos and visual elements, even if filters or low resolution have altered them [2]. The result? A 99% accuracy rate across all four modalities [1].
Pairing Multimodal Matching with Blockchain Timestamping
Once content is identified, proving ownership becomes the next critical step. Spotting infringing content is only part of the solution – you also need irrefutable evidence that you own the original. Blockchain vs traditional timestamping methods differ, but blockchain provides the irrefutable evidence needed.
ScoreDetect, another tool from InCyan, records ownership on the SKALE blockchain by creating a cryptographic checksum (hash) of the content instead of storing the actual file [3]. This ensures your files remain private while a permanent, time-stamped record of their existence is created. With an average transaction speed of just 2.754 seconds [3], it’s fast enough to integrate seamlessly into automated publishing workflows. When multimodal matching flags a potential infringement, the system can cross-check the asset’s checksum against its blockchain record, establishing a clear, verifiable chain of evidence.
"ScoreDetect allows you to easily create verification certificates for your digital content. These certificates provide proof of authenticity and enhance your copyright protection." – ScoreDetect [3]
This proof of ownership fits perfectly into InCyan’s broader strategy for protecting digital content, as described below.
End-to-End Content Protection with InCyan Tools
Identifying and verifying content is crucial, but true protection requires a comprehensive, full-lifecycle approach. InCyan achieves this through its integrated suite of tools.
- Tectus: Uses invisible watermarking for images, videos, and audio, embedding ownership signals that remain intact through compression and editing without affecting user experience [1].
- Indago: Targets infringing content at its source, employing rapid forensic searches to de-index unauthorized links within 60 minutes [1][4].
- TorrentWatch: Monitors the BitTorrent ecosystem in real time, generating evidence-backed enforcement reports [1].
"Gaining visibility into how content is utilized across the internet has truly been invaluable. We now have the automated intelligence needed to make smarter decisions, increase revenue through improved monetization and enforcement, and maintain strict control over our assets." – Director, Shutterstock [1]
Together, these tools form a robust defense system. Tectus embeds ownership signals to prevent misuse, Idem identifies unauthorized use when it happens, ScoreDetect provides blockchain-backed proof of ownership, Indago removes infringing content from search engines, and TorrentWatch tracks it across peer-to-peer platforms. Each layer supports the others, creating a system that’s far harder to bypass than any single tool could be on its own.
Challenges and Solutions in Large-Scale Multimodal Systems
Fixing Bottlenecks in Data Processing Pipelines
Handling multimodal matching at scale comes with its share of challenges. High-volume discovery feeds generate millions of signals, making it nearly impossible to audit without structured models [2]. Adding to the complexity, review teams are often overwhelmed by duplicate alerts for the same content across multiple platforms.
A practical solution is incident clustering, which consolidates related detections into a single case rather than treating every URL as an individual issue. This allows teams to focus on campaigns as a whole instead of chasing isolated links. Pair this with event-driven ingestion and official API integrations, and you can significantly reduce discovery delays. For enforcement, tools like InCyan’s Indago enable faster action by severing links between search engines and infringing content, outperforming traditional host-level takedowns [1][4].
| Bottleneck | Mitigation Strategy | Outcome |
|---|---|---|
| Ingestion delays | Event-driven architectures and API integrations [2] | Real-time discovery, reduced lag |
| Reviewer overload | Clustering near-duplicates into incidents [2] | Consolidated case history, less fatigue |
| Slow enforcement | Enforcement via Indago [4] | Links severed quickly |
| Storage limits | Storing hashes/checksums only [2][3] | Lower infrastructure costs, better privacy |
These improvements help balance speed and precision, especially in high-volume scenarios.
Balancing Accuracy and Latency
Beyond pipeline efficiency, maintaining a balance between speed and accuracy is essential. Faster results often risk false positives, while prioritizing accuracy can slow down enforcement. The solution? Tiered confidence thresholding.
"High confidence detections can move directly into enforcement queues or bulk actions, subject to policy. Medium confidence detections may route to analyst review." – Nikhil John, InCyan [2]
In this approach, high-confidence matches go straight to automated enforcement, medium-confidence detections are reviewed by analysts, and low-confidence signals are redirected to model training. This system minimizes clutter in review queues while ensuring critical matches are addressed promptly. Explicit service-level targets further refine this process. For instance, critical live content may have a 30-minute review window, while lower-priority items can be addressed by the next business day [2]. Programs calibrated this way typically maintain false positive rates between 5% and 15% [2], providing legal teams with reliable evidence.
"Risk scores should combine confidence with business context. A moderately confident match involving a pre-release asset in a key launch market may deserve higher priority than a very confident match on a legacy asset." – Nikhil John, InCyan [2]
Building Multimodal Matching Systems That Last
Effective multimodal systems don’t just address immediate challenges – they’re designed to endure. Long-term reliability hinges on modular design. By structuring systems around standardized data entities like Assets, Usages, Incidents, and Capture Artifacts, you can integrate new data types and AI models without overhauling the entire system [2]. Each entity follows a defined schema and quality standards, ensuring evidence remains reproducible and legally defensible.
"Working with InCyan has completely transformed how we handle our media operations. The ability to centralize, secure and protect our content has turned a previously chaotic workflow into a streamlined process." – Director, BPI Limited [1]
To keep systems lean and privacy-compliant, cryptographic hashes replace raw file storage. Meanwhile, a blockchain-anchored audit trail logs every access, modification, and transfer of digital evidence, ensuring tamper-proof records [4][2]. This chain of custody not only supports operational workflows but also makes detections admissible in court, adding a layer of legal credibility to the system.
Conclusion and Key Takeaways
Key Benefits of Multimodal Matching
AI-driven multimodal matching is reshaping how high-volume content protection is handled. The statistics behind its performance highlight a leap forward, far surpassing traditional hash-based tools, which falter when files are re-encoded or cropped.
A standout feature of multimodal matching is its ability to manage large-scale operations. By clustering similar signals into incidents, the system optimizes scalability, enabling review teams to concentrate on addressing root causes rather than getting bogged down by scattered alerts [2]. With modality-aware models that simultaneously handle images, video, audio, and text, organizations can now safeguard their entire content libraries under one unified framework.
These advanced capabilities lay the groundwork for a cohesive ecosystem, which will be explored further in the upcoming section on InCyan’s comprehensive solution.
The Role of InCyan and ScoreDetect
InCyan builds on these advancements, offering a practical, all-encompassing content protection system.
InCyan integrates these tools into a seamless ecosystem. Its suite includes Idem for precise identification, Indago for swift enforcement, Tectus for invisible watermarking, which utilizes advanced techniques to resist removal attacks, and TorrentWatch for extensive monitoring. For example, Indago can delist infringing content from search engines within just 60 minutes [1].
ScoreDetect, on the other hand, secures proof of ownership by anchoring it to the blockchain in approximately 2.754 seconds – completely gas fee-free [3]. This process creates a cryptographic timestamp that serves as legal evidence, without ever storing the actual asset on-chain. As one satisfied ScoreDetect user, Imri, a Startup SaaS CEO, shared:
"ScoreDetect is exactly what you need to protect your intellectual property in this age of hyper-digitization. Truly an innovative product, I highly recommend it!" [3]
FAQs
How does multimodal matching still recognize content after heavy edits?
Multimodal matching works by identifying content even after substantial edits. Instead of using delicate bit-by-bit comparisons, it generates compact, modality-specific neural fingerprints. These fingerprints focus on stable features like visual motifs or semantic patterns that remain intact despite changes like cropping or compression. For example, InCyan’s Idem platform can recognize content even if only 10% of the original is left. Meanwhile, Tectus provides ownership proof through invisible watermarking, which holds up even after extensive editing.
What do vector databases do in billion-asset matching systems?
Vector databases are the backbone of large-scale similarity searches in systems managing billions of assets. They store compact, AI-generated fingerprints of data, allowing for efficient comparisons. By leveraging Approximate Nearest Neighbor (ANN) search and advanced structures like Hierarchical Navigable Small World (HNSW) graphs, these databases achieve search speeds with sublinear complexity – ideal for handling massive datasets.
To efficiently manage and process high-dimensional data, they use Product Quantization (PQ), a compression technique that reduces data size without sacrificing accuracy. This approach powers technologies like InCyan’s Idem, which excels at identifying assets in real time, even after they’ve undergone significant transformations. As a result, these systems are highly effective for large-scale content identification and rights management.
How does blockchain timestamping prove I owned a file at a certain time?
Blockchain timestamping works by creating a unique cryptographic hash – essentially a digital fingerprint – of your file and recording it on a permanent, tamper-resistant blockchain ledger. This process offers undeniable proof that your content existed in its exact form at the time the transaction was made.
ScoreDetect, a product developed by InCyan, takes this a step further. It generates a verifiable ownership certificate that includes the hash and blockchain details. The best part? Your original file isn’t stored, ensuring your intellectual property stays both secure and private.

