Energy-efficient audio watermarking focuses on embedding and extracting data in audio files while minimizing power usage and processing time. This often involves psychoacoustic audio watermarking to ensure data is hidden effectively without compromising sound quality. This is critical for devices with limited resources and real-time applications. The challenge lies in balancing imperceptibility, data capacity, resilience to attacks, and now energy efficiency.
Key insights:
- Time-domain methods: Simple, energy-efficient, and suitable for low-power devices but vulnerable to compression and attacks.
- Frequency-domain methods: More resilient and precise, leveraging transforms like DWT and DCT, but require higher computational power.
- Blind extraction: Used in 90% of new algorithms, allowing watermark recovery without the original audio, reducing storage and processing needs.
- ScoreDetect Enterprise: A system combining time- and frequency-domain techniques for scalable, efficient, and high-resilience watermarking, ideal for large-scale operations.
Quick Comparison:
| Feature | Time-Domain | Frequency-Domain | ScoreDetect Enterprise |
|---|---|---|---|
| Energy Usage | Low | Moderate | Optimized |
| Attack Resistance | Low | High | Very High |
| Data Capacity | High but fragile | Moderate to High | High with quality retention |
| Integration | Simple | Complex | Easy with automation |
Energy-efficient watermarking is evolving rapidly, with wavelet-domain methods leading the way. These approaches strike a balance between quality, efficiency, and protection, meeting the needs of modern audio systems.
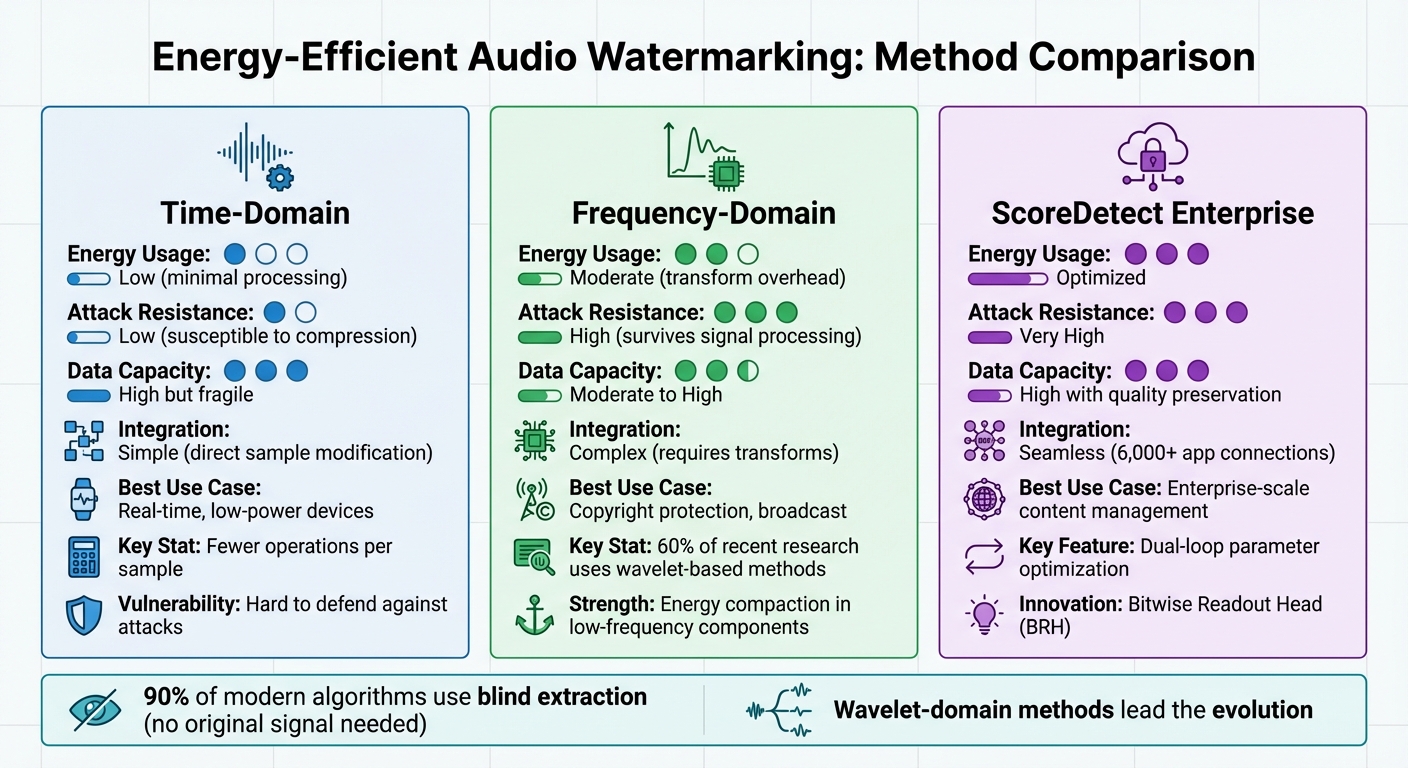
Audio Watermarking Methods Comparison: Time-Domain vs Frequency-Domain vs ScoreDetect Enterprise
1. Time-Domain Watermarking
Energy Efficiency
Time-domain watermarking stands out for its low power usage. By directly altering audio samples – adjusting amplitude, adding subtle echoes, or modifying the least significant bits – it avoids the need for complex mathematical operations. As researchers have pointed out:
Time-domain techniques… embed watermarks by directly modifying the temporal characteristics of the audio signal [1].
This approach results in fewer operations per sample, making it well-suited for real-time applications or devices with limited resources [2]. A good example is Quantization Index Modulation (QIM). According to an MDPI review, "QIM is one of the most robust methods introduced in audio watermarking. It is simple and requires little computing time" [2].
But while it’s efficient, it does have its drawbacks.
Robustness
The main challenge with time-domain watermarking lies in its vulnerability to attacks. Yuzhu Wang, an Associate Professor at China Agricultural University, highlights this issue:
Time-domain techniques… have low computational costs and are easy to implement. However, they are hard to defend against various attacks [3].
To counteract these vulnerabilities, buffer compensation mechanisms are often employed to maintain alignment between the watermarked and original signals. In tests, adaptive buffer compensation helped keep bit error rates below 12.31%, even during attacks like time-scale modification (TSM) and pitch-scale modification (PSM) [1].
Embedding Capacity
Time-domain watermarking also struggles with a capacity-imperceptibility trade-off. Techniques like Least Significant Bit (LSB) can embed large amounts of data but are fragile and easily disrupted by basic signal processing. On the other hand, more robust methods, such as Audio-Lossless Robust Watermarking (ALRW), typically offer limited embedding capacity [1]. This balance between capacity and imperceptibility requires careful tuning when implementing these methods, as it directly impacts their effectiveness within larger systems.
Ease of Integration
The simplicity of time-domain methods makes them easy to implement in existing systems. They don’t require extensive computational resources or specialized libraries, which is why they remain popular in applications where energy efficiency is more critical than achieving maximum robustness. However, developers must carefully adjust embedding strength to maintain audio quality [1].
sbb-itb-738ac1e
UOC’s Audio Watermarking System, High-fidelity recovery under extreme conditions
2. Frequency-Domain Watermarking
Frequency-domain watermarking steps in as an alternative to time-domain methods, addressing their limitations by optimizing energy use and improving resistance to various signal distortions.
Energy Efficiency
This method relies on transforming audio signals using techniques like the Discrete Cosine Transform (DCT) or Discrete Wavelet Transform (DWT). While these transformations require more initial computation compared to time-domain approaches, they often prove to be more efficient overall.
The reason lies in a concept known as "energy compaction." As Weinan Zhu and colleagues at Shanghai University explain:
Owing to the energy compaction property of the DCT, most signal energy is concentrated in the low-frequency components [1].
This allows the algorithm to focus on adjusting specific mid-frequency bands – typically between 3,000 Hz and 4,000 Hz – rather than processing the entire signal. Adaptive frequency-domain algorithms take it a step further by dynamically adjusting embedding strength for each frame, skipping low-energy segments to save processing power [3].
In practical scenarios, this efficiency pays off. While time-domain methods might seem simpler, they often require extra processing for error correction or repeated attempts when watermarks are damaged. Frequency-domain methods, with their built-in robustness, avoid this extra energy drain by performing reliably from the start. This makes them a more efficient choice for applications where energy and accuracy matter.
Robustness
When it comes to surviving signal attacks, frequency-domain watermarking outperforms its time-domain counterpart. The DWT has become the go-to technique, with around 60% of recent research in audio watermarking employing wavelet-based methods [2]. Wavelets strike a balance between being resistant to attacks and remaining undetectable to listeners.
Quantization Index Modulation (QIM) is another standout method. Carlos Jair Santin-Cruz from Mexico’s National Institute of Astrophysics, Optics and Electronics highlights its advantages:
QIM is one of the most robust methods introduced in audio watermarking. It is simple and requires little computing time [2].
In August 2025, researchers Weinan Zhu and Hanzhou Wu demonstrated the strength of frequency-domain techniques. Their patchwork-based DCT watermarking algorithm targeted the 3,000–4,000 Hz range and used buffer compensation mechanisms. Even under severe conditions like time-scale and pitch-scale modifications, the algorithm maintained a Bit Error Rate below 12.31% [1].
This focus on mid-frequency bands is critical. High frequencies often get lost during MP3 compression, while low frequencies are too sensitive to human hearing. The mid-range offers the best protection against common attacks while staying imperceptible to listeners.
Embedding Capacity
Frequency-domain watermarking, like all watermarking techniques, faces the "Magic Triangle" trade-off: balancing capacity, robustness, and imperceptibility. As Santin-Cruz puts it:
Improving one performance criterion harms the other two [2].
Traditional methods could embed only limited data, but recent advancements in neural networks have significantly expanded these limits. For example, in 2025, researchers from Tsinghua University and Tencent AI Lab introduced WAKE (Watermarking Audio with Key Enrichment). WAKE achieved an embedding capacity of 32 bits per second while maintaining excellent audio quality, scoring 4.396 on the PESQ scale and achieving a Signal-to-Noise Ratio (SNR) of 41.237 dB. This outperformed the WavMark baseline, which had an SNR of 38.594 dB and a PESQ score of 4.256 [4].
The breakthrough came from using Invertible Neural Networks (INN), which allow multiple watermarks to be embedded without overwriting previous data. This multi-layer strategy not only increases capacity but also retains the redundancy needed to maintain high-quality audio.
Ease of Integration
For modern applications, balancing energy efficiency with ease of implementation is crucial. Frequency-domain watermarking does require more specialized tools, such as libraries for DCT or DWT transformations, and it comes with higher computational demands. However, 90% of modern audio watermarking algorithms are "blind", meaning they don’t need the original signal for extraction [2]. This makes them practical for real-world uses like copyright monitoring or second-screen services.
For devices with limited resources, such as mobile phones or IoT sensors, QIM offers an excellent compromise. It delivers strong robustness with minimal processing requirements, making it ideal for real-time applications. More complex methods, like two-level wavelet decompositions, improve resistance to attacks but also increase computational demands. Developers must weigh these factors carefully based on their energy and performance needs [2].
3. ScoreDetect Enterprise
ScoreDetect Enterprise brings scalable, integrated protection to enterprise-level audio content management by leveraging both time- and frequency-domain innovations. While these watermarking techniques form the backbone of audio protection, handling the demands of large-scale operations requires tackling challenges like energy efficiency, durability, and seamless integration. This platform rises to the occasion with InCyan‘s advanced watermarking technology, tailored for managing extensive audio libraries.
Energy Efficiency
One of the standout features of ScoreDetect Enterprise is its ability to conserve computational resources through frame-wise parameter optimization. It uses a dual-loop process – comprising an Outer Loop and an Inner-Outer Loop – to automatically fine-tune embedding strength parameters. This automation eliminates the need for manual adjustments, which traditionally consume a lot of time and processing power.
By dynamically adjusting its computational load based on the specific characteristics of the audio content, the system ensures energy is used where it matters most. This approach is especially beneficial for devices with limited resources or applications requiring real-time processing, as it minimizes battery drain and enhances overall system performance. The result? A platform that performs reliably even under demanding conditions.
Robustness
ScoreDetect Enterprise employs adversarial optimization in the time-frequency domain, using a level-proportional perceptual budget to maintain high audio quality. One of its key innovations is the Bitwise Readout Head (BRH), which processes temporal data without depending on sequence order. This allows the platform to decode watermarks accurately, even when the audio has been desynchronized or altered – scenarios often encountered in podcast editing, radio broadcasts, or user-generated content.
Ease of Integration
Integration is a breeze with ScoreDetect Enterprise. The platform connects seamlessly to over 6,000 web apps via Zapier, enabling automated workflows without requiring custom development. This means organizations can link the watermarking system directly to their existing digital asset management tools, content distribution networks, and monitoring systems.
Additionally, the system uses specific keys to control watermark embedding and decoding, ensuring only authorized users with the correct key can access the embedded information. For large-scale operations, it automates the management of extensive content libraries, embedding confidential data to replace manual tracking methods. This process is a core component of forensic audio watermarking, which provides a permanent record of ownership. This automation makes it possible to handle thousands of assets efficiently while reinforcing protection without adding unnecessary workload or complexity.
Advantages and Disadvantages
Time-domain methods stand out for their simplicity and energy efficiency but falter when faced with signal processing attacks. These methods are perfect for low-power devices like Bluetooth headsets, where conserving battery life is a priority. However, they are vulnerable to common issues like MP3 compression and background noise. As researchers Yizhu Wen and colleagues pointed out, "Time-domain watermarking approaches often lack robustness, while frequency-domain approaches typically offer greater robustness but are more complex to implement." [6]
On the other hand, frequency-domain techniques embed watermarks into the audio spectrum, often using transforms like the Discrete Wavelet Transform (DWT). This approach makes the watermark more resistant to resampling, filtering, and compression, offering a much higher level of reliability. These wavelet-domain methods strike a balance between robustness and imperceptibility, making them a go-to choice for applications like copyright protection and broadcasting [2]. The downside? They demand more computational resources, which can be a challenge for mobile or embedded systems where energy efficiency is critical.
The capacity for embedding data also differs significantly. Time-domain methods, such as Least Significant Bit (LSB), can embed a large amount of data but are easily manipulated. Frequency-domain techniques, particularly those combining DWT with Singular Value Decomposition (SVD), achieve a better balance. They maintain perceptual transparency while embedding a substantial amount of data. As Carlos Jair Santin-Cruz noted, "The use of DWT and SVD provided with the perceptually transparent embedding of a large amount of data and good robustness, respectively." [2]
Here’s a comparison of these methods across key performance metrics:
| Feature | Time-Domain | Frequency-Domain | ScoreDetect Enterprise |
|---|---|---|---|
| Energy Efficiency | High (minimal processing) | Moderate (transform overhead) | High |
| Robustness | Low (susceptible to compression) | High (survives signal processing) | Very High |
| Embedding Capacity | High but susceptible | Moderate to High | High with quality preservation |
| Integration Ease | Simple (direct sample modification) | Complex (requires transforms) | Seamless (6,000+ app connections) |
| Best Use Case | Real-time, low-power devices | Copyright protection, broadcast | Enterprise-scale content management |
ScoreDetect Enterprise takes these concepts further by combining advanced optimization techniques to enhance both energy efficiency and robustness. Its ability to deliver reliable performance makes it a strong fit for practical applications, from podcast editing to radio broadcasting, where audio often undergoes multiple transformations.
Conclusion
Energy-efficient audio watermarking hinges on balancing three essential factors: robustness, imperceptibility, and computational efficiency. While time-domain methods are ideal for low-power applications, they often falter when faced with compression or signal processing attacks. On the other hand, frequency-domain techniques – especially wavelet-based methods, which feature prominently in about 60% of current research – offer stronger resistance without compromising audio quality [2]. The growing adoption of blind extraction, now present in 90% of new algorithms, highlights a clear trend toward more efficient and practical watermarking solutions [2].
Advancements in technology are tackling long-standing challenges. For instance, in May 2025, Sony AI researchers introduced the Robust Audio Watermarking Benchmark (RAW-Bench), a tool designed to test deep learning models like AudioSeal and SilentCipher. These models demonstrated impressive generalization across music and speech datasets but struggled to withstand attacks like the Descript Audio Codec (DAC), a growing concern as neural compression becomes the norm in audio workflows [5]. Meanwhile, adaptive modulation techniques have shown extraordinary resilience under extreme attack scenarios, signaling promising developments for the future [1].
One standout example of innovation in this space is ScoreDetect Enterprise, which combines energy efficiency with robust protection, catering to large-scale content management needs. Its invisible watermarking technology integrates seamlessly with over 6,000 apps, ensuring reliability across diverse use cases, from podcast distribution to broadcast media, even as audio undergoes multiple transformations.
Based on the comparative insights discussed, organizations should prioritize technologies that merge the resilience of frequency-domain methods with the efficiency of blind extraction. Wavelet-domain techniques, paired with blind extraction, offer a robust solution to meet both current demands and evolving security challenges. As Carlos Jair Santin-Cruz from the National Institute of Astrophysics, Optics and Electronics aptly stated, "The choice between [conventional and deep learning] depends on various factors, including specific applications, available resources, and the desired trade-offs between performance metrics" [2]. The path forward is clear: adopt solutions that address today’s operational requirements while preparing for tomorrow’s challenges, especially as neural codecs and AI-generated content continue to reshape the digital landscape.
FAQs
How do I choose between time-domain and frequency-domain watermarking?
When deciding between time-domain and frequency-domain audio watermarking, your choice should align with the specific needs of your application – factors like how undetectable the watermark needs to be, its ability to withstand distortions, and processing requirements all come into play.
Time-domain methods are straightforward and require fewer resources, making them a good choice for simpler applications. However, they tend to be less effective when facing challenges like compression or filtering. On the other hand, frequency-domain techniques demand more computational power but provide stronger protection against such distortions. Balancing the need for efficiency with the level of security required will help you determine the most suitable approach.
What makes a watermark “blind,” and why does it save energy?
A "blind" watermark is a type of audio watermark that can be identified and extracted without requiring access to the original, unwatermarked version of the audio. It works by embedding faint, undetectable signals into the audio. These signals are designed to use very little processing power for detection, all while preserving the audio’s overall quality.
How can watermarks survive AI codecs and heavy audio editing?
Watermarks can withstand AI codecs and extensive audio editing thanks to sophisticated embedding techniques designed to increase their durability against distortions. For instance, adversarial resistance strengthens watermarks in the time–frequency domain, making them tough to disrupt through desynchronization, cuts, or edits. Another approach, frequency-layered embedding, spreads watermarks across various spectral layers. This ensures that even if the audio undergoes noise, pitch changes, or filtering, the watermark can still be partially recovered – all while preserving the audio’s quality and detectability.

