If your DAM has to do more than store files, a layered setup wins. In this comparison, I’d sum it up like this: metadata-only DAM is exact but brittle, monomodal AI helps with tagging but stays stuck in one format, multimodal matching links text, image, video, and audio, rights workflows add use control, and blockchain provenance adds proof.
Here’s the short version:
- Metadata-driven DAM works best for small, stable libraries and exact lookup.
- Monomodal AI cuts tagging time, but it still can’t natively link media types.
- InCyan Idem handles cross-modal search and can still match files after cropping, compression, and partial reuse.
- InCyan Blueprint adds rights, royalties, and compliance checks inside the DAM workflow.
- ScoreDetect adds timestamped proof of authorship with a blockchain record tied to a SHA-256 checksum.
A few numbers stand out right away:
- Libraries often start to strain past 10,000 assets
- Multimodal embeddings reached 96.7% recall
- Top-two precision reached 73.3%
- Automated systems can cut asset search time by up to 40%
- Rights review work can drop by 60% to 80%
- Proposed federal penalties tied to digital replica misuse can reach $50,000 per copy
If I were choosing by need, I’d use these four checks:
- Cross-modal matching: Can I search video, image, audio, and text together?
- Edit resistance: Does the match still hold after file changes?
- Workflow fit: Does it help at ingest, review, and release?
- Rights protection: Can it support rights checks and proof later?

Multimodal AI vs Traditional DAM: Key Metrics & Capabilities Compared
eMAM and Twelve Labs: Powerful Multimodal AI for Media Asset Management

sbb-itb-738ac1e
Quick Comparison
| Approach | Cross-Modal Matching | Edit Resistance | Workflow Fit | Rights Protection |
|---|---|---|---|---|
| Metadata-driven DAM | No | Low | Manual ingest and tagging | Exact fields, but people must keep them current |
| Monomodal AI DAM | Limited to one format | Low to medium | Faster tagging at ingest | Flags risk, but people still decide |
| InCyan Idem | Yes | High for cropped, compressed, or partial reuse files | Search and ingest work together | Flags rights gaps and likeness/voice issues |
| InCyan Blueprint | Not the main focus | Depends on DAM inputs | Rights, royalties, and compliance inside workflow | Stronger governance and review routing |
| ScoreDetect | No | File-proof layer, not search | Runs in the background via apps and plugins | Immutable timestamped ownership record |
In other words: Idem helps you find the right asset, Blueprint helps you decide if you can use it, and ScoreDetect helps you prove it later. That’s the core idea behind the full article.
1. Traditional Metadata-Driven DAM
Traditional DAM systems run on manual metadata. People tag files, then the system pulls them back with text filters and folder paths. That sounds fine on paper. In practice, it gets messy fast.
AWS points out that manual tagging takes a lot of time and becomes inconsistent when creative teams work at scale [3]. And once a library gets to around 10,000 assets, the process often starts to crack [5]. That’s when dark assets pile up – files with missing, mismatched, or uneven tags [6].
Cross-Modal Matching
Search is still text-only. So if someone writes a description, the system can’t use that to find a visual moment inside a video or a short audio clip unless a person has already transcribed it and added time stamps by hand [2][4].
Robustness to Transformations
These systems index labels, not the content itself. So when a file gets cropped, compressed, or renamed, it can end up looking like a different record in the DAM—even if it uses watermarks that resist removal attacks. When that happens, it can also lose the rights context tied to the original file [2][6].
Workflow Integration
Ingest is where things slow down. New assets usually stay unsearchable until someone finishes the metadata. Teams under pressure often rush that step, and rushed tagging creates even more dark assets. That gap between upload and search is the exact problem monomodal AI is trying to fix.
Rights Protection
Rights fields can be exact, but only if people keep them up to date [1]. One missed license change can bring an asset with expired rights back into search results, which can turn into legal risk [1].
| Dimension | Traditional Metadata-Driven DAM |
|---|---|
| Search method | Exact keyword match; deterministic filters |
| Tagging | Manual entry; inconsistent at scale |
| Scalability | Breaks down past ~10,000 assets [5] |
| Cross-modal retrieval | Not supported |
| Transformation handling | Fragile; renamed or cropped files become dark assets |
| Rights reliability | Precise but entirely dependent on human accuracy [1] |
That’s the ceiling traditional metadata-driven DAM runs into. Monomodal AI-enhanced DAM aims to push past it, but it still handles one modality at a time.
2. Monomodal AI-Enhanced DAM
Monomodal AI speeds up ingest tagging, but it works inside one modality at a time. So instead of waiting on manual tagging, the system reviews assets as they’re uploaded and generates tags, color profiles, and descriptions in seconds [6][5]. That makes ingest much faster. But it still doesn’t fix cross-modal search.
Cross-Modal Matching
This is where monomodal systems hit a wall. They can’t connect text, image, and audio inside one shared semantic layer. If someone wants to search video with text, the system still needs transcription and time-coding before it can make that connection [3][4].
That separation also hurts performance when content gets cropped, compressed, or reused in pieces. In plain terms, the system knows the asset in its original form, but it has a harder time following that asset once it changes.
Robustness to Transformations
Monomodal AI tags what it sees at ingest. If that asset is later cropped, compressed, or partly reused, search still depends on the original ingest tags rather than the changed version [3].
That gap shows up in testing. In comparison testing, multimodal models achieved a 96.7% recall success rate against keyword-based systems, which struggled with less predictable search needs [3].
Workflow Integration
Monomodal AI can make ingest faster and help flag brand issues, but people still need to review edge cases. AI-powered solutions can reduce asset search time by up to 40% [6].
That helps day-to-day operations. It does not replace rights verification, though. Teams still need human checks when the call isn’t clear-cut.
Rights Protection
Monomodal AI can surface possible risk, but it can’t make the final rights call. Human verification is still needed for copyright and compliance-sensitive assets [1][2].
The bigger change happens when matching, ingest, and rights checks run together in one workflow.
| Dimension | Monomodal AI-Enhanced DAM |
|---|---|
| Search method | Semantic search within one modality |
| Tagging | Automated; seconds per asset [6] |
| Scalability | Handles large libraries consistently [6] |
| Cross-modal retrieval | Not native; requires transcription [3] |
| Transformation handling | Fragile; relies on original ingest tags [3] |
| Rights reliability | Probabilistic; human review still required [1][2] |
3. Multimodal Matching with InCyan Idem
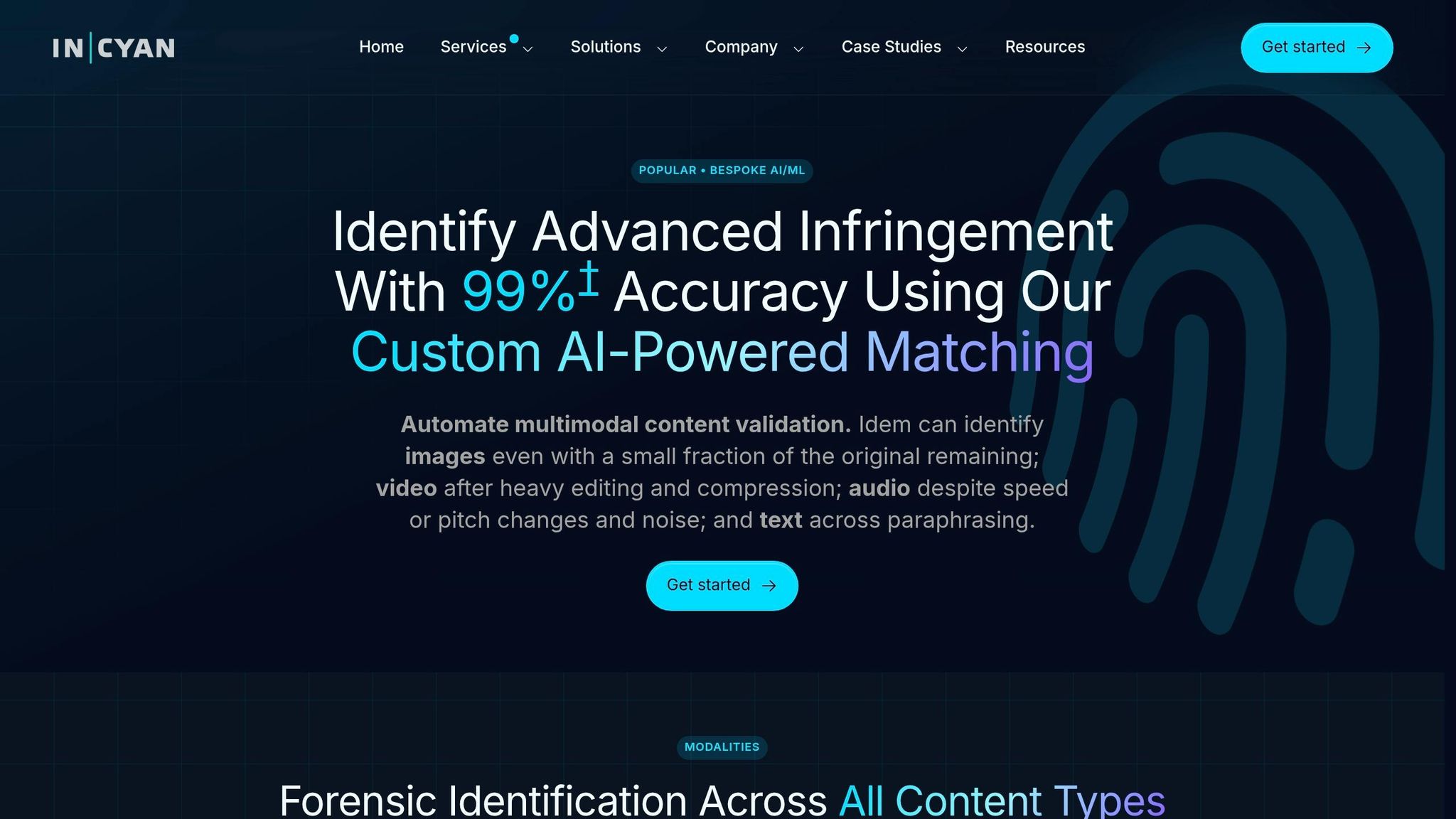
InCyan Idem takes a different path from metadata-first or single-format systems. It creates shared embeddings for text, images, video, and audio, then places them in one shared embedding space. That means a text query like "racing car" can point straight to matching images and video clips [3]. In plain English, search no longer stops at whatever tags happened to be added at ingest. It connects ingest and search in the same system, which is where monomodal setups often fall short.
Cross-Modal Matching
Teams can search video with natural language, find content with an uploaded image, and search across formats in one workflow [3][4]. So instead of jumping between tools, they can move from text to image to video without changing how they search.
In a real-world test of 170 gaming creative assets, multimodal embeddings reached a 96.7% recall success rate. High-precision recall hit 73.3% for the top two results [3]. For video-heavy workflows, segmented embeddings split long videos into meaningful chunks. That makes it much easier to pull a specific clip instead of scrubbing through an entire file [3].
Robustness to Transformations
Idem continues matching even after cropping, compression, memes, and mobile edits. So if an asset gets reused in part, the system can still trace it back to the source asset.
Workflow Integration
Retrieval is only part of the story. Idem also fits into enterprise ingest and review workflows. It automates ingest, improves metadata consistency, and helps legal teams flag unlicensed or synthetic assets before release [1][4][8].
Rights Protection
Idem also supports likeness and voice recognition, which matters for DAM governance and compliance. Unauthorized publication of a digital replica of an individual’s intellectual property can result in damages of $50,000 per copy under proposed federal law [8]. That’s not a small risk.
By flagging assets where rights are not documented, Idem gives legal teams a chance to catch exposure before it turns into litigation [8]. That rights signal becomes more useful when paired with formal ownership records, which the next section covers.
| Dimension | InCyan Idem |
|---|---|
| Search method | Native cross-modal search [3] |
| Tagging | Automated ingest metadata [4] |
| Cross-modal retrieval | Text, image, video, and audio in one space [3] |
| Transformation handling | Robust to cropping, compression, and partial reuse |
| Rights reliability | Automated flagging; supports compliance enforcement [8] |
4. Unified DAM and Rights Management with InCyan Blueprint
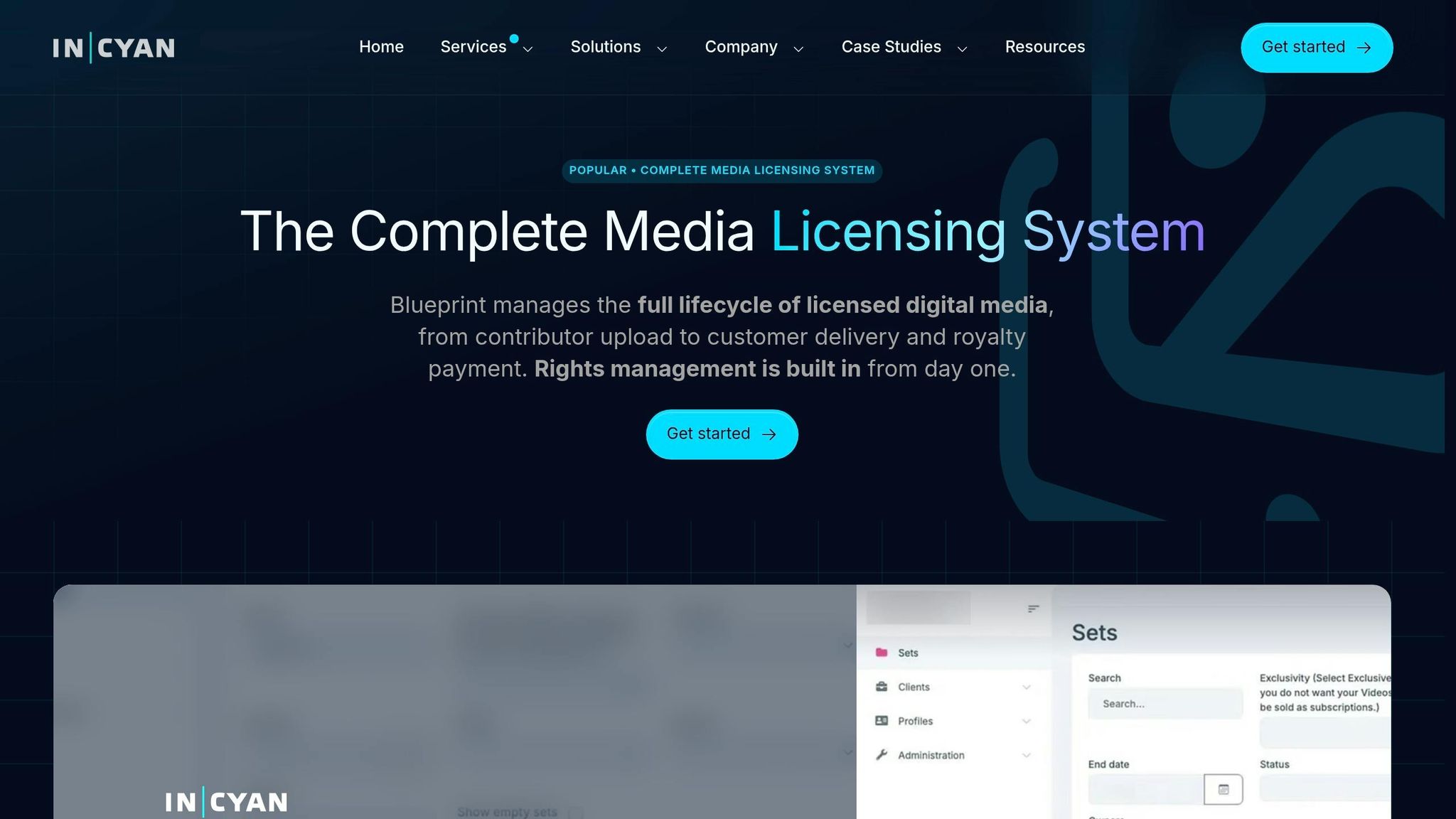
After assets are matched, the next enterprise issue is simple: can those assets be used, by whom, and under what terms?
InCyan Blueprint moves DAM beyond a basic repository and into a system of record [7]. That means establishing ownership, royalties, and compliance are built right into asset governance. In plain English, matching an asset is only part of the job. Blueprint also helps govern whether that asset is allowed to move forward.
Workflow Integration
Blueprint weaves governance into storage, access, and activation [7]. It can spot expired licenses, flag brand issues like logo distortion or the wrong fonts, and send edge cases to legal for review. That matters because manual checks eat up time fast. With automated compliance checks in place, teams can cut manual review by 60% to 80% [5].
Rights Protection
Blueprint can also flag faces, voices, and bodies when training or licensing limits apply [8]. That’s a big deal for teams working with talent rights, likeness use, or AI training controls.
"AI does not replace human review entirely; instead, it serves as an assistant tool to enhance visibility and management efficiency for asset compliance risks." – Senior DAM Consultant, DragonBravo [2]
The practical setup is straightforward: use AI to flag risk and sort what needs attention first, then require human verification for final legal decisions [2][5].
| Dimension | InCyan Blueprint |
|---|---|
| Core function | Unified DAM with embedded rights, royalties, and compliance management |
| Governance model | Built into storage, access, and activation [7] |
| Compliance automation | Expired licenses, brand violations, face/voice/body flagging [8][5] |
| Manual review reduction | 60%–80% reduction in manual compliance work [5] |
| Human oversight | AI flags risks; human verification required for final decisions [2] |
When proof of ownership needs to go beyond workflow control, the next layer is immutable provenance.
5. Blockchain Provenance with ScoreDetect
Once Blueprint handles usage rules, InCyan’s ScoreDetect adds proof of authorship that you can point to later. It doesn’t put the file itself on-chain. Instead, it writes a SHA-256 checksum to a public blockchain. That creates a timestamped record showing that a specific version of a file existed at a specific moment.
In plain English: this is the proof layer under multimodal matching and rights governance.
Workflow Integration
ScoreDetect plugs into 6,000+ web apps through Zapier. Its WordPress plugin can also timestamp every post automatically when you publish or update it. After that, the process runs quietly in the background.
Rights Protection
When ownership gets questioned, provenance often matters more than tags. Metadata can be changed, stripped out, or lost during migration. Blockchain provenance stays in place, which helps preserve proof of ownership even when those records don’t.
ScoreDetect also issues a Verification Certificate with:
- the SHA-256 hash
- the public blockchain URL
- the registration date
- the copyright owner name
That paperwork helps support disputes with a verifiable audit trail.
| Feature | Metadata-Only Records | Blockchain Provenance (ScoreDetect) |
|---|---|---|
| Integrity | Editable | Immutable and cryptographically secure |
| Evidence value | Editable | Verifiable audit trail for statutory damages [6][8] |
| Permanence | Difficult to maintain over long timeframes [8] | Permanent record of rights transfers [8] |
That provenance layer leads into the bigger shift: how multimodal AI changes ingest, tagging, licensing, and compliance outcomes. It also reshapes how DAM handles discovery, ingest, licensing, and compliance at scale.
How Multimodal AI Changes DAM Outcomes
Multimodal AI changes what a DAM system can find, keep track of, and verify. The big change isn’t just better search. It’s how the system handles ingest, spots reused content, and supports rights management. In practice, that changes four things: discovery, resilience after edits, workflow speed, and rights control.
Cross-modal matching versus keyword and image-only search
When metadata is missing, messy, or uneven, assets tend to vanish from search. Multimodal AI tackles that problem by putting text, images, video, and audio into one shared space. So a query like "product launch event" can pull up relevant video clips, still images, and audio segments even when those assets don’t contain the exact same keywords. That cuts down on dark assets and makes retrieval across formats much faster.
In a June 2026 case, multimodal embeddings reached 96.7% recall and 73.3% top-two precision [3]. InCyan’s Idem uses this same model, matching assets across images, video, and audio without relying on exact keyword matches.
Once search goes past keywords, the next issue is simple: can the system still identify an asset after someone edits it?
How each approach handles cropping, compression, and partial reuse
Metadata-only systems tend to fail when assets are cropped, compressed, or reused in a different form. The problem gets worse when those changes happen after ingest. And that matters, because assets are constantly republished, resized, clipped, and remixed across channels.
Multimodal AI helps keep assets discoverable after edits, reuse, or format shifts. InCyan’s Idem is built to detect content ownership even after cropping, compression, and partial reuse.
| Approach | Handles Cropping/Compression | Detects Partial Reuse |
|---|---|---|
| Traditional Metadata DAM | No | No |
| Multimodal AI (InCyan Idem) | Yes | Yes |
Effect on ingest, tagging, licensing, and compliance workflows
Multimodal AI can cut a lot of manual work at ingest. Organizations using automated metadata systems report reducing asset search time by up to 40% [2][6]. That doesn’t remove human judgment. It shifts where that judgment shows up.
A practical standard is to set auto-tagging confidence thresholds between 0.82 and 0.88. Assets that fall below that range go to a manual review queue instead of being tagged with weak labels [5]. That’s a much better setup than forcing teams to clean up bad tags later.
This also changes licensing and compliance. Instead of relying on manual review alone, teams can move toward workflow-level enforcement, where matching supports governance in a direct way.
How provenance and enforcement fit into the stack
After discovery and governance, the last layer is proof of origin. ScoreDetect adds blockchain timestamping after matching and governance. It stores a checksum on-chain, which creates proof that a specific file version existed at a specific time without storing the file itself.
That proof layer matters when metadata gets stripped, edited, or lost during migration. In those cases, proof is easier to carry forward when rights disputes move outside the DAM.
Pros and Cons of Each Enterprise Approach
No single approach handles every DAM need. Each one fits a different setup, team, and risk level. The tradeoffs here follow the same four criteria used across this article: matching, edit resistance, workflow integration, and rights protection.
Where metadata-driven DAM still works
Metadata-driven DAM is still the best fit when teams need deterministic search. That matters a lot in legal, financial, and long-term archival settings, where precision matters more than flexibility.
The downside is simple: manual tagging gets hard to maintain at scale. Once libraries grow past 10,000 assets, the process starts to strain. So while this approach is reliable, it also gets brittle when assets change or the library keeps growing.
Where monomodal AI helps and where it falls short
Monomodal AI helps teams move faster by automating tagging for one content type. If you’re managing a large library of just one format, it can do the job well.
The problem shows up when teams work across formats. A system like this can’t link a still frame to a related video or audio file, which leads to fractured search across media types. That’s where shared matching across formats starts to matter.
Where multimodal matching and unified rights workflows add value
InCyan’s Idem closes that cross-modal gap by placing text, images, video, and audio into one shared vector space. In plain English, that means one search can pull up the right video clip, still image, and audio segment from the same campaign moment – even after cropping, compression, or format conversion [3][4]. Idem keeps matches useful even after major edits and file changes.
InCyan’s Blueprint adds rights controls right inside that same workflow. It flags rights issues during review, before release, which can cut manual compliance review work by 60–80% [5].
That said, there’s still a catch. AI-driven rights interpretation can misread complex licensing terms, so people should still handle final approvals [1][7].
"Blueprint flags rights issues during review, before release."
Where blockchain provenance helps and where it does not
Provenance works at a lower layer than discovery and governance. It acts as proof.
ScoreDetect records a timestamped checksum on-chain to prove a file version. It doesn’t help teams find assets, and it isn’t meant to. Its main use comes up when a company needs to prove ownership during a dispute or keep a clean audit trail for high-value IP.
| Approach | Advantages | Limitations | Best Fit |
|---|---|---|---|
| Metadata-Driven DAM | Deterministic, precise, strong archival control | Labor-intensive; brittle on transformed assets [3][4] | Legal, financial, and regulated archives |
| Monomodal AI | Automates tagging for a single format at scale | Fragmented search across media types [4] | High-volume, single-format libraries |
| Multimodal Matching (Idem) | Resilient to cropping, compression, and format changes [3] | Higher compute costs; requires taxonomy fine-tuning | Creative discovery across multi-format campaign assets |
| Unified Rights (Blueprint) | Embeds compliance into workflow; 60–80% less manual review [5] | Risk of AI misreading complex license terms [1][7] | Global brand management with complex licensing needs |
| Blockchain Provenance (ScoreDetect) | Immutable proof of ownership; verifiable audit trail | No discovery function | Copyright dispute support and audit trails |
Conclusion
Multimodal AI matters most when enterprises need matching they can trust, cross-format discovery, and rights control at scale. Across matching, resistance to edits, workflow connection, and rights protection, multimodal systems bring the most value to enterprise DAM. The key question is not how many features a tool has. It’s where each layer belongs in the workflow.
Choosing the right model by enterprise need
Use metadata-driven DAM for small, stable libraries. Use monomodal AI for tagging in a single format. Use a layered multimodal stack when content volume grows, file types multiply, and licensing gets more complex. Blockchain provenance adds a verifiable record that backs ownership claims and audit trails.
Final takeaway
Once you separate discovery, rights control, and provenance, deployment gets much simpler. For high-value, regulated, or large libraries, combine InCyan’s Idem for multimodal matching, Blueprint for rights management, and ScoreDetect for blockchain provenance. Together, they turn a repository into a governed system of record.
FAQs
When should a team switch to multimodal DAM?
A team should move to a multimodal DAM when its asset library gets larger, messier, and more mixed in format. At that point, manual tagging, sorting, and retrieval start to slow people down.
This shift matters even more when older single-format tools can’t handle cross-media search or fail to recognize content after edits like cropping or compression. It also becomes important when the company needs one source of truth for governance, compliance, and asset reuse across global departments.
How does multimodal search work across media types?
Multimodal search turns text, images, video, and audio into high-dimensional vector embeddings inside a shared semantic space. Put simply, the system looks at what an asset means instead of leaning only on tags or file names.
When someone types a natural language query, the system maps that query into the same space and looks for the closest semantic matches across different media types. That makes cross-media search possible, like finding images or videos from a text description.
Why add blockchain proof to a DAM workflow?
Adding blockchain proof to a DAM workflow creates an unchangeable record of ownership. That helps build trust and gives teams a stronger way to protect content.
The key idea is simple: instead of putting the file itself on the blockchain, organizations record a content checksum. That creates a secure, transparent audit trail they can use to verify original assets.
InCyan uses this method to support compliance and copyright enforcement, including through ScoreDetect.

