If you want to match the same asset across image, video, audio, and text, the hard part is not finding duplicates. It is proving the files came from the same source after edits.
When I read this piece, the takeaway was simple: five problems decide whether multimodal matching works or fails. Those problems are:
- Different data types that do not start in the same format
- Cross-modal alignment that can break after cropping, dubbing, or speed changes
- Score fusion that can drift when one signal is weak
- Media transformations like compression, resizing, and screen recording
- Scale and latency when one file must be checked against millions of assets
In plain terms, standard hashing catches exact copies only. Perceptual matching goes further, but it usually stays inside one media type. Multimodal matching has to connect signals across formats, even when part of the asset is missing or changed.
Lecture 4 – Multimodal Alignment (MIT How to AI Almost Anything, Spring 2025)
sbb-itb-738ac1e
Quick Comparison
| Area | Main problem | What usually breaks |
|---|---|---|
| Modality heterogeneity | Each media type has its own feature format | Shared identity gets split before comparison |
| Alignment | Signals must line up across time and structure | Timing shifts, crops, subtitles, dubbing |
| Fusion and scoring | Multiple signals must produce one usable result | One weak modality can skew the result |
| Transformations | Edits change each modality in different ways | Compression, recapture, resizing, re-encoding |
| Scale and performance | Large libraries add cost and delay | Screening and live checks become harder |
A few facts stand out. The article points to 30-frame video windows and 10-second audio windows for stream matching, and it notes that transformer matchers can be more accurate in hard cases but are often too expensive for first-pass screening because their cost grows fast.
My short read on it: multimodal matching algorithms work only if identity comes from structure, not file-level sameness or fragile tags. That is the thread connecting all five challenges.
Why Multimodal Matching Is Harder Than Standard Duplicate Detection
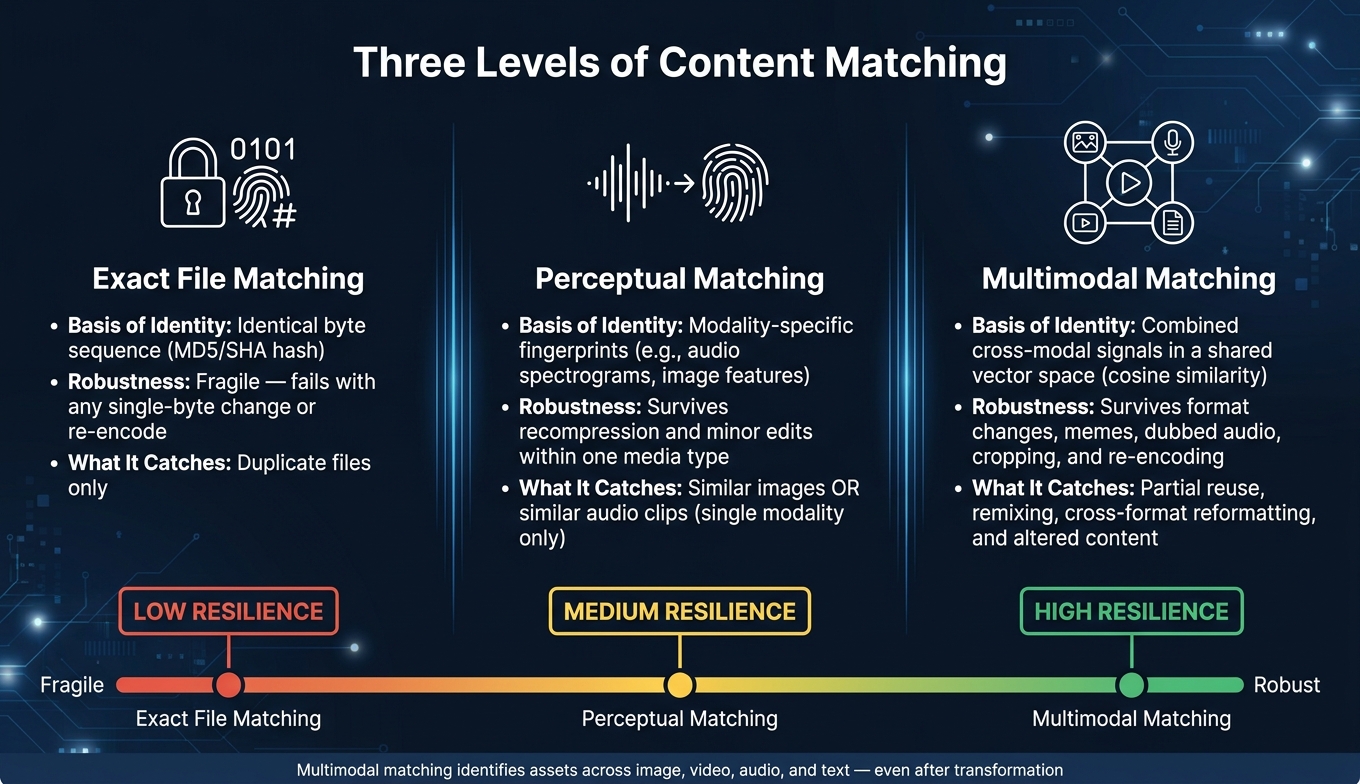
Multimodal vs Perceptual vs Exact File Matching: A Visual Comparison
Exact file matching uses hashes like MD5 or SHA to test whether two files are identical. It’s fast and dependable, but only if the file stays untouched. Change even one byte, and the match fails. That’s why systems move to perceptual matching.
Perceptual matching looks at digital fingerprints instead of raw bytes. It identifies media by pulling out fingerprints tied to that format, like audio spectrograms or image features. That lets the same item stay recognizable after compression or small edits. But there’s a catch: it still works only inside a single media type. Multimodal matching has to cross that line.
Multimodal matching is harder because it has to spot the same underlying asset even when it shows up as a screenshot, a short clip, a meme, or a dubbed track. That matters because compression, cropping, reformatting, and dubbing don’t affect every modality the same way. A video frame may change one way, audio another, and text overlays in a third. So the system has to pull signals from visual, audio, text, and structural cues, then merge them into one identity [1]. Some systems take those signals and place them in a shared vector space, where they can be compared with cosine similarity [1].
The table below shows how these approaches differ in practice.
| Matching Type | Basis of Identity | Robustness | What It Can Catch |
|---|---|---|---|
| Exact File Matching | Identical byte sequence | Fragile; fails with any edit or re-encode | Duplicate files only |
| Perceptual Matching | Modality-specific fingerprints | Survives recompression and minor edits within one media type | Similar images or similar audio clips |
| Multimodal Matching | Combined cross-modal signals [1] | Survives format changes, memes, and dubbed audio [1] | Partial reuse, remixing, and altered content [1] |
These problems stack on top of each other. Different modalities shape how data gets normalized. That, in turn, affects fusion and scoring. And those steps decide how well the system holds up under real-world changes. First: modality heterogeneity.
1. Modality Heterogeneity
Each modality comes with its own signal structure. Images, audio, text, and video all turn into different feature formats, and each one needs its own preprocessing pipeline before any comparison can happen. If every modality shows up in a different format, the system can miss that two items point to the same asset before matching even begins.
That gap in representation is the first big obstacle in multimodal matching. Once those separate pipelines split things apart, you get the alignment problem discussed next.
2. Alignment Across Modalities
Once each modality has its own feature representation, the next hurdle is alignment. In plain English, alignment means getting signals from different modalities to line up so the system can verify that they all refer to the same underlying asset. That sounds simple. It isn’t.
The problem gets tougher because each modality is normalized in its own way. So even if the inputs start from the same source, the outputs can end up on different scales, with different timing cues, or with different reference points.
Signal Diversity
Each modality needs its own normalization pipeline before signals can be compared. The hard part here isn’t normalization by itself. It’s what comes after: making those separate outputs comparable when each pipeline has processed its input differently.
Think of it like translating the same story into three formats: audio, text, and video. Each version still tells the same story, but the structure changes enough that matching them line for line takes work.
Alignment Complexity
Alignment depends on audio, text, and video anchors pointing to the same source. For video, that happens at two levels:
- Frame-level
- Clip-level
That split matters. Speed changes can throw off timing cues, and if one level gets disturbed while the other stays intact, the system has to sort out two signals that no longer agree. Even strong signals can fail if their anchors don’t line up.
Similarity Reliability
When anchors disagree, the issue is failed alignment, not failed matching. That’s an important distinction.
If the anchors don’t agree, the system flags the asset as unverified or spoofed. That result comes straight from misalignment. It isn’t caused by some separate scoring layer making an unrelated decision.
Transformation Resilience
Common edits can break alignment before matching even starts. Compression artifacts, cropping, speed changes, and subtitles can all shift anchors across modalities. Once that happens, it gets much harder for the system to confirm a shared source.
The deeper effects of these transformations are covered in the robustness section that follows.
3. Fusion and Similarity Scoring
Once the modalities are lined up, the next job is turning them into one score you can trust. That sounds simple. It isn’t.
Fusion gets tricky because the final score is only useful if the signals still mean the same thing after editing. If one signal shifts more than the others, the result can get thrown off fast.
Signal Diversity
Different modalities don’t speak the same language. One may output values tied to visual patterns, while another leans on audio or structure.
To make those outputs comparable, map each modality into the same feature space. That way, their scores can be compared directly instead of clashing with each other. It also helps stop one noisy modality from taking over the final score.
Alignment Complexity
Fusion only works when the visual, audio, and structural anchors agree. If they don’t, the score becomes unreliable.
Put plainly: when anchors conflict, the composite score is harder to trust. That’s why score fusion is useful only when the inputs stay coherent.
Transformation Resilience
Identity should come from the shared feature space, not from a fragile tag.
That’s a big deal because transformations like compression or recapture can skew fusion scores, especially when resisting removal attacks. And the problem gets worse under compression, cropping, and recapture, where distortions can stack up and push the score away from the underlying identity.
4. Robustness to Media Transformations
Compression, cropping, re-encoding, and screen capture don’t damage media in the same way. Each one changes the signal a bit differently. Sometimes enough detail survives for a match. Other times, the edit strips out too much. That’s usually the point where similarity scoring starts to break down.
How Transformations Alter Signals
Compression and re-encoding add display, compression, and pixel-grid artifacts that can blur or hide the original structural signals. Screen capture does something similar, but with extra display, compression, and lens artifacts layered on top. The result is a noisier version of the asset, where the original structure gets harder to read.
Cropping and resizing create a different kind of problem. They can throw off alignment when one modality changes more than another. Once that happens, the system may lose shared anchor points, and the asset becomes hard to verify.
How Distortions Reduce Match Confidence
When distortions stack up, match confidence drops. Push it far enough, and the score falls below the confidence threshold. Structured features hold up better than raw pixels, but repeated compression, recapture, and cropping still wear them down over time.
The systems that hold up best lean on structural signals instead of metadata. Gradients, edges, and frame-to-frame motion patterns survive compression and re-encoding better than raw pixels. Idem applies this approach to survive cropping and compression.
Of course, durability alone isn’t enough. The matching also has to work at scale and in real time.
5. Scalability and Real-Time Performance
Transformation resilience only goes so far if the system falls apart once the library gets big. Matching one asset against millions is a different game than matching one against ten. As the library grows, speed and cost start pushing back hard. At enterprise scale, this stops being only a recognition task and becomes a throughput problem too.
Signal Diversity
At this size, each modality needs to be normalized into a shared compact vector before candidate screening starts. That common format matters. It lets one similarity engine handle comparisons across the board instead of forcing teams to run separate matching stacks for each modality.
Alignment Complexity
Live-stream matching adds even more pressure. The system can’t wait for a full clip to finish before it makes a decision. Sliding-window processing solves that by checking the stream in near real time. For example, 30-frame windows for video or 10-second windows for audio can produce window-level fingerprints on a continuous basis without waiting for the full clip [1].
Similarity Reliability
Raw pixels and full waveforms are simply too slow when the library is large. Compact vectors make the first screening pass fast, while heavier matchers fit better in a second review stage.
Transformer-based dense matchers like LoFTR can deliver better accuracy in hard cases, but there’s a catch. Their global self-attention comes with quadratic computational cost, which makes them a better fit for verification than for screening [2]. That’s the trade-off behind the fusion strategy used next.
Transformation Resilience
At scale, resilience means keeping per-asset cost low while still preserving enough structure to trace a modified file back to its source. So instead of running a full deep learning pipeline on every candidate, the system checks whether an asset’s compact feature vector has traceable lineage to a registered parent asset ID [1].
That approach keeps per-asset cost low and still helps catch heavily modified content at enterprise volume. In practice, the pattern is pretty clear:
- Handcrafted features are the fastest
- Learned descriptors hold up better under modification
- Transformer matchers fit second-pass verification
Fusion Approaches Compared
After normalization and scoring, the next step is deciding how to combine modality outputs. This choice shapes what the system leans toward: matching accuracy, resilience when inputs get messy, or the ability to recover from partial evidence. Put simply, it affects whether the system can still find a match when the content is degraded, cropped, compressed, or incomplete.
| Approach | How It Combines Signals | Matching Accuracy | Error Propagation | Ability to Work with Partial Evidence |
|---|---|---|---|---|
| Early Fusion | Merges raw data or low-level features at the input stage | High for clean, tightly aligned data | High – noise in one modality can corrupt the entire joint representation | Low – often requires all modalities to be available |
| Intermediate Fusion | Normalizes modalities into shared feature representations for shared feature extraction | High – captures structural variation across modalities in a shared vector space | Controlled – normalization paths isolate errors before feature extraction | Moderate – can operate if the shared stage receives any valid input |
| Late Fusion | Processes each modality independently, then combines decision-level outputs | Moderate – relies on coherence between independent modality outputs | Low – a failure in one pipeline doesn’t break the others | High – can still match on a single modality’s output |
Here’s the practical tradeoff.
Early fusion can work very well when the inputs are clean and line up closely. But it’s also the easiest to throw off. If one modality is compressed, cropped, or missing, that problem can spill into the whole shared representation.
Late fusion takes the opposite path. Each modality is handled on its own first, and the system combines outputs only at the end. That means one weak pipeline doesn’t automatically sink the rest. When you’re dealing with degraded or partial content, that’s a big plus.
Intermediate fusion sits in the middle. It maps each modality into a shared format before comparison, rather than merging raw inputs or waiting until the final decision stage. That gives it a middle-ground profile: strong matching performance, with more control over how errors move through the system.
What These Challenges Mean for Content Protection and Ownership Verification
Each of these problems chips away at your ability to prove infringement once content starts moving across formats and platforms. And that’s the part that matters most in practice: if the chain of origin breaks, a rights holder may not be able to prove lineage at all.
Modality heterogeneity makes matching harder when the same work shows up as image, video, audio, or text. Alignment failures get in the way of source tracing, especially when someone reuses only part of the original or changes the format. Weak fusion scoring makes it tougher to turn match signals into evidence you can stand behind. Poor robustness to transformations is the biggest problem of the bunch. If identity depends on a fragile tag, basic edits can snap the link back to the source. And scalability bottlenecks drag out investigations when provenance has to be traced fast.
InCyan‘s Idem is built to deal with these failure points. Its multimodal matching holds up through major transformations, including mobile edits, memes, cropping, and compression.
Matching can show likely reuse. Timestamping is what locks in the ownership record. ScoreDetect works alongside matching by timestamping a SHA-256 checksum on the blockchain, which creates verifiable proof of prior ownership without storing the file. Put simply, it links detection to proof.
Conclusion
These five problems all point to the same issue: can a system still verify provenance after content changes form? Multimodal matching is tough because each step adds another place where things can break.
The hard part isn’t spotting duplicates. It’s proving ownership after content gets remixed, re-encoded, or captured again. In day-to-day use, content identity depends on structural lineage, not an embedded tag or attached manifest. Structural lineage can survive transformation. Embedded markers usually can’t.
When you’re looking at tools, check whether the system can deal with screenshot recapture, partial reuse, and cross-format reformatting. InCyan’s Idem is built to identify ownership even when content has been heavily modified. Matching finds likely reuse. Timestamping keeps the proof in place. ScoreDetect adds blockchain timestamping, turning a match into verifiable proof of prior ownership. [1][2]
FAQs
How does multimodal matching differ from perceptual hashing?
Perceptual hashing turns media into short binary signatures based on structural cues, like brightness patterns or frequency components. It does a solid job with small edits such as resizing or compression.
But there’s a catch. Once the file changes too much, the method starts to fall apart. Extreme cropping, big rotations, or shifts in meaning can throw it off.
Multimodal matching takes a different path. It uses AI-driven embeddings to map meaning across images, audio, and text. So instead of looking at surface-level patterns, it looks at what the content is about.
That makes it more resilient when files have been heavily modified.
Why do cropping, dubbing, and speed changes break matches?
These edits break matches because many detection systems depend on fixed signals like file data, pixel patterns, or simple hashes. Cropping, dubbing, and speed changes distort those signals, so the source content becomes harder to spot and false negatives become more likely.
Systems that lack temporal consistency or multimodal matching also tend to miss non-linear edits, like tempo changes or heavy cropping that strips away large parts of the visual frame.
How can matching still work at enterprise scale?
Matching at enterprise scale stops being a simple file-to-file check. Instead, it shifts to AI-driven semantic fingerprinting.
Here’s the idea: assets get turned into compact 512-dimensional vector embeddings. That makes it possible to match by similarity, not just exact hashes.
Why does that matter? Because exact hash matching falls apart the moment a file gets edited, cropped, re-encoded, or partly reused. Semantic matching has more give, so it can still spot related content after those changes.
Speed is the next hurdle. Huge databases can make search drag if the system checks every item one by one. To avoid that, these systems use Approximate Nearest Neighbor search, often with HNSW graphs. That setup keeps search latency at sub-second levels even as the dataset grows.
InCyan’s Idem uses this method to identify content even after heavy modification, or when only 10% of the original remains.

