Multimodal similarity analysis is a powerful AI tool that compares content across formats like text, images, audio, and video. While businesses use it for tasks such as digital content protection and content moderation, it raises ethical concerns. Key risks include:
- Privacy Issues: Data from social platforms is often analyzed without user consent, leading to potential breaches.
- Bias and Errors: False positives (e.g., legitimate content flagged as infringing) and biased enforcement can harm users and reduce system reliability.
- Lack of Transparency: Automated decisions often lack clear explanations, making it hard for users to appeal or verify enforcement actions.
To address these, businesses can focus on data minimization, human oversight, and transparent decision-making. Tools like cryptographic checksums and blockchain-based systems help balance effective enforcement with ethical standards.
The Dark Side of AI | Challenges, Risks, & Ethical Considerations
sbb-itb-738ac1e
Ethical Risks of Multimodal Similarity Analysis
The rapid pace and advanced capabilities of multimodal similarity analysis come with significant ethical concerns. These include privacy breaches, biased results, and gaps in accountability. Let’s break down these risks and their implications for privacy, fairness, and responsibility.
Privacy and Consent Risks
One major issue is how these systems often collect and analyze personal data from social platforms and user-generated content sites. This data – ranging from photos and usernames to location metadata – is frequently accessed without the user’s explicit consent. Such practices raise serious questions about ethical content protection and the limitations of automated rights enforcement.
Platforms like Instagram and TikTok strip metadata from content, making it harder to verify consent or establish ownership of digital media. This forces companies to rely on complex forensic techniques while also navigating platform-specific rules, robots.txt files, and emerging licensing frameworks. All of this must be done at scale, adding to the complexity.
Efforts like the C2PA (Coalition for Content Provenance and Authenticity) aim to address these issues by giving creators more control over their content’s ownership data. Without such systems, however, similarity analysis tools risk turning into broad surveillance mechanisms rather than tools for fair and targeted enforcement.
Bias and Misclassification Problems
In addition to privacy concerns, the accuracy of these systems often poses ethical challenges.
False positives – where legitimate content is flagged as infringing – and false negatives, which miss actual violations, are common. These errors are especially prevalent with low-quality, heavily edited, or culturally nuanced content [1]. Bias can creep in when models unintentionally incorporate sensitive characteristics like race, religion, or gender identity, leading to unfair enforcement and wrongful content removal. This is particularly damaging to marginalized groups.
High false positive rates, which can exceed 15%, create another problem: reviewer fatigue. Human moderators overwhelmed by irrelevant alerts may start overlooking real violations [1]. As a result, poorly calibrated models don’t just harm individual users – they undermine the credibility of the entire enforcement system.
"Classification choices have ethical consequences." – Nikhil John, InCyan [1]
Gaps in Transparency and Accountability
The lack of transparency in how these systems operate is perhaps the most pervasive issue. Many similarity analysis tools make enforcement decisions – such as content takedowns or account flags – without explaining why a match was identified or how the decision was reached [1].
"The challenge for leaders is simple, very few of those signals arrive in a form that legal, trust and safety, and business stakeholders can act on with confidence." – Nikhil John, InCyan [1]
When content is removed based on a similarity score, users should be informed about what triggered the action. Without detailed explanations – like "overlapping image region" or "matching audio segment" – appeals become almost impossible, and internal audits lose their effectiveness. This lack of a clear chain of custody also creates legal risks, as companies must document how and when content was analyzed during enforcement [1]. Closing these transparency gaps is essential for ensuring that multimodal similarity analysis is used responsibly in content protection.
Examples of Ethical Risks in Practice
Ethical risks in content management are not just theoretical – they play out in real situations with real consequences, affecting both businesses and the individuals whose content is involved.
Case Study: False Attribution of Content Ownership
Automated systems often rely on numerical similarity scores to identify potential content matches. High scores suggest that content is nearly identical [3]. But these scores lack context. They can’t differentiate between a licensed copy, an independently created piece, or an AI-generated version trained on the original [5].
This limitation can lead to serious legal issues. For instance, when companies use these scores to justify automated DMCA takedowns without deeper investigation, legitimate creators can see their work wrongfully removed [2][5]. Such actions can severely damage a brand’s reputation, particularly in communities where trust is already fragile.
Additionally, businesses that depend on centralized records for ownership verification face their own risks. If a third-party service managing these records shuts down or is acquired, the digital proof of ownership might vanish. This leaves companies vulnerable in ownership disputes, with no evidence to back their claims [5].
"The internet has no built-in concept of ‘I made this first.’ AI scrapes everything. Imitation is faster than ever. Big brands steal from small creators and face no consequences." – Stelais [5]
Example: Privacy Breaches in User-Generated Content Analysis
Another pressing ethical concern is the risk of privacy breaches. These occur when businesses collect and store sensitive user data from platforms to perform similarity analyses [4]. By retaining raw assets like photos, videos, or audio clips, companies create tempting targets for hackers [4].
Some solutions, like InCyan’s ScoreDetect, address this issue by storing only cryptographically secured checksums on the blockchain. This approach ensures content verification without exposing raw data [4][6]. However, when businesses skip these safeguards and store raw user-generated content, any security breach doesn’t just compromise company data – it also exposes users’ personal content. Rebuilding trust after such incidents is incredibly challenging.
Poor data practices in similarity analysis not only open companies to legal risks but also undermine user confidence. These examples highlight the critical need for strong safeguards in handling multimodal similarity analysis.
How to Reduce Ethical Risks
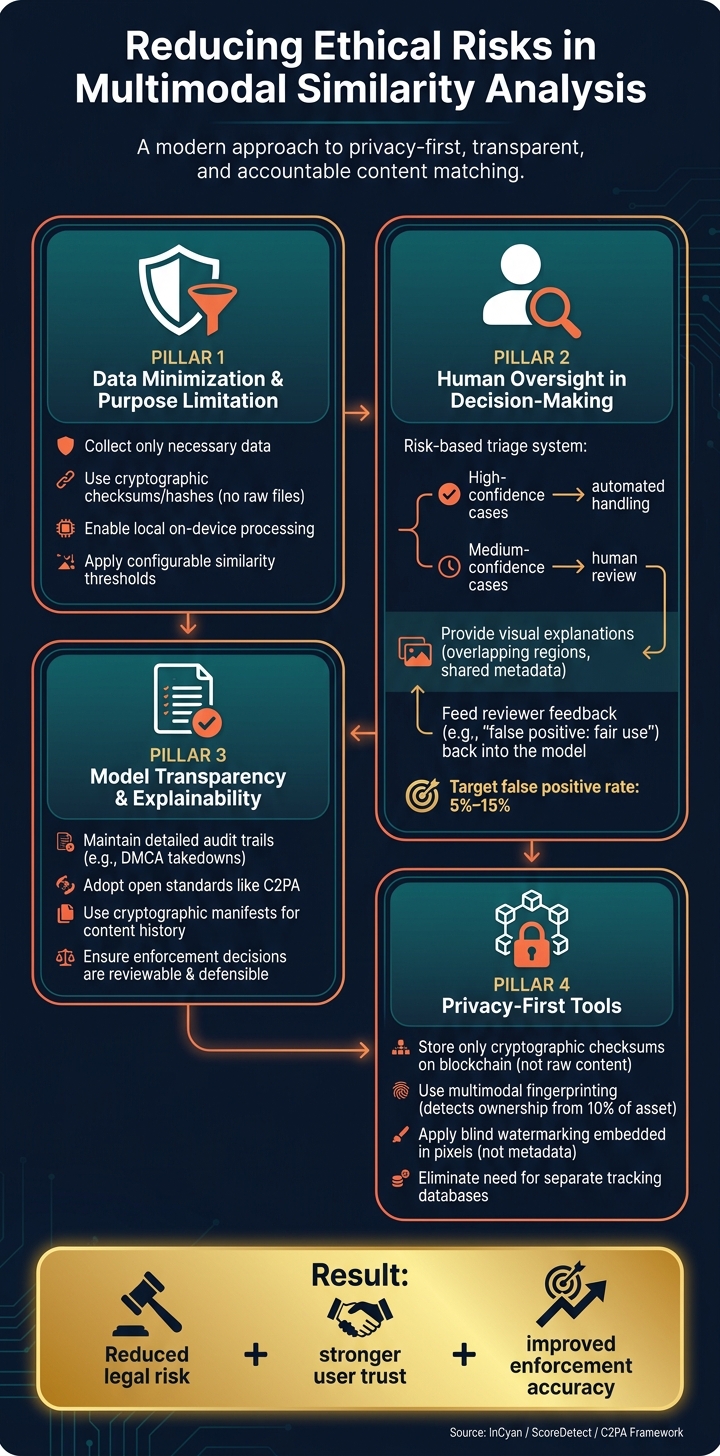
How to Reduce Ethical Risks in Multimodal Similarity Analysis
To tackle ethical challenges like privacy breaches, bias, and lack of transparency, businesses need focused strategies. These include limiting data collection, incorporating human oversight, and improving system transparency.
Data Minimization and Purpose Limitation
Start by collecting only the data absolutely necessary for the intended purpose. For example, instead of storing raw files like photos, videos, or audio, companies can use cryptographic checksums or hashes. These verify authenticity without retaining the original content [4].
Local processing is another key approach – data is analyzed directly on the user’s device, and only verification details are transmitted [5]. Configurable similarity thresholds can further ensure that data is processed solely for its specific purpose [3].
Additionally, involving human reviewers in the process enhances decision-making reliability.
Adding Human Oversight to Decision-Making
Adopt a risk-based triage system where high-confidence cases are handled automatically, while medium-confidence cases are flagged for human review [1].
To assist reviewers, systems should provide clear explanations, such as highlighting overlapping image regions or shared metadata. This enables analysts to make informed decisions rather than blindly approving automated results. As Nikhil John from InCyan notes:
"AI powered discovery works best when human reviewers play an active role in calibration." – Nikhil John, InCyan [1]
Feedback from reviewers, such as tagging a case as a "false positive due to fair use", can be fed back into the system to improve its accuracy over time [1].
Model Transparency and Explainability
Transparency in decision-making is essential for accountability. Businesses should maintain detailed audit trails that document every enforcement decision, such as DMCA takedowns. These records ensure a traceable path from detection to outcome [1][5].
Open standards like C2PA (Coalition for Content Provenance and Authenticity) provide a framework for recording a piece of content’s history. By using cryptographic manifests, C2PA documents everything from the content’s creation to the tools used and any subsequent changes. This makes ownership claims easier to verify and defend. Audit trails further guarantee that enforcement decisions are reviewable and defensible [1].
Tools That Support Ethical Content Protection
Choose tools designed with privacy in mind, such as those that store only cryptographic checksums instead of raw content. For instance, ScoreDetect follows this principle by recording checksums on a blockchain:
"ScoreDetect does not store any digital assets or content. It only stores the checksum of the content on the blockchain." – ScoreDetect [4]
For more comprehensive protection, InCyan’s Idem platform uses multimodal fingerprinting to identify content ownership, even when as little as 10% of the original asset is detectable. Additionally, Tectus, InCyan’s blind watermarking solution, embeds ownership signatures directly into the pixels rather than metadata, eliminating the need for separate tracking databases [7][5]. These tools help enforce content rights effectively while maintaining ethical standards and protecting user privacy.
Conclusion: Balancing Progress with Ethics
Multimodal similarity analysis offers powerful tools for large-scale content protection and rights enforcement. But with great power comes significant responsibility. Risks such as privacy violations, biased outcomes, false claims, and unclear decision-making often arise when these systems are implemented without the right safeguards.
Thankfully, there are effective ways to address these challenges. Strategies like data minimization, incorporating human oversight, and maintaining transparent audit trails not only protect ethical standards but also improve enforcement accuracy. As Nikhil John from InCyan aptly says:
"Discovery should illuminate where value is created or leaked so they can refine distribution, pricing, and partner strategy." – Nikhil John, InCyan [1]
Ignoring ethical considerations doesn’t just harm trust – it also increases legal risks, especially with stricter regulations like the EU AI Act. High-performing systems, aiming for false positive rates of 5%–15% [1], demand thoughtful design and solid frameworks to ensure credible enforcement.
In the long run, responsible practices deliver substantial benefits. By building discovery programs on solid evidence, privacy-conscious data use, and clear, explainable outputs, organizations can bolster legal defensibility, foster user trust, and improve operational efficiency. Ethics isn’t just a side note in content protection – it’s the foundation for keeping these systems effective and sustainable.
FAQs
When does multimodal similarity analysis become surveillance?
Multimodal similarity analysis crosses the line into surveillance when it moves from targeted efforts to protect intellectual property to indiscriminate tracking of user activity without a well-defined, evidence-backed purpose. Tools like Idem are built for specific copyright enforcement tasks, but their ethical application depends on structuring discovery around clear evidence. This approach ensures that monitoring respects both user privacy and platform guidelines, transforming raw data into actionable insights rather than enabling broad, unjustified oversight of individuals.
How can we reduce false positives without missing real infringements?
To reduce false positives and maintain accurate detection, implement multimodal matching to analyze images, videos, audio, and text at the same time. This approach generates unique digital signatures, making it possible to identify content even after major changes. Automating confidence scoring is another key step: high-confidence matches can be handled automatically, while medium-confidence results are flagged for further review. Tools such as InCyan’s Idem and Tectus improve precision by offering evidence-grade matching and invisible watermarking, providing reliable proof of ownership.
What proof and audit trail are needed for defensible takedowns?
For effective takedowns, it’s crucial to have tamper-proof evidence that directly ties the infringing content to your original work. ScoreDetect simplifies this process by creating a verification certificate. This certificate includes a blockchain record, a cryptographic checksum, and timestamp integrity to ensure the evidence remains secure and trustworthy.
In cases involving multiple types of content, the tool also documents AI-generated confidence scores and organizes related matches into a single incident. This approach helps minimize false positives while maintaining a clear and reliable audit trail.

