Multimodal content matching is a process that links digital media – like images, videos, audio, and text – to their original versions. It embeds durable, invisible signals into content, making it identifiable even after edits like cropping, compression, or re-encoding. This technology ensures media ownership is verifiable and helps detect misuse or unauthorized alterations.
Key Points:
- How It Works: Uses techniques like perceptual hashing, invisible watermarking, and AI-driven analysis to create "fingerprints" for media. These fingerprints remain intact despite transformations.
- Applications:
- Protects digital assets by detecting altered or copied media.
- Verifies ownership without requiring unmarked originals.
- Enhances media retrieval and targeting for industries like eCommerce and entertainment.
- Challenges: High data volumes, integrating diverse formats, and computational demands can complicate implementation.
- Future Potential: Expected market growth to $4.5 billion by 2028 highlights increasing demand for these solutions.
This method is essential for safeguarding content in a digital world where media is constantly shared and modified.
How Multimodal Content Matching Works
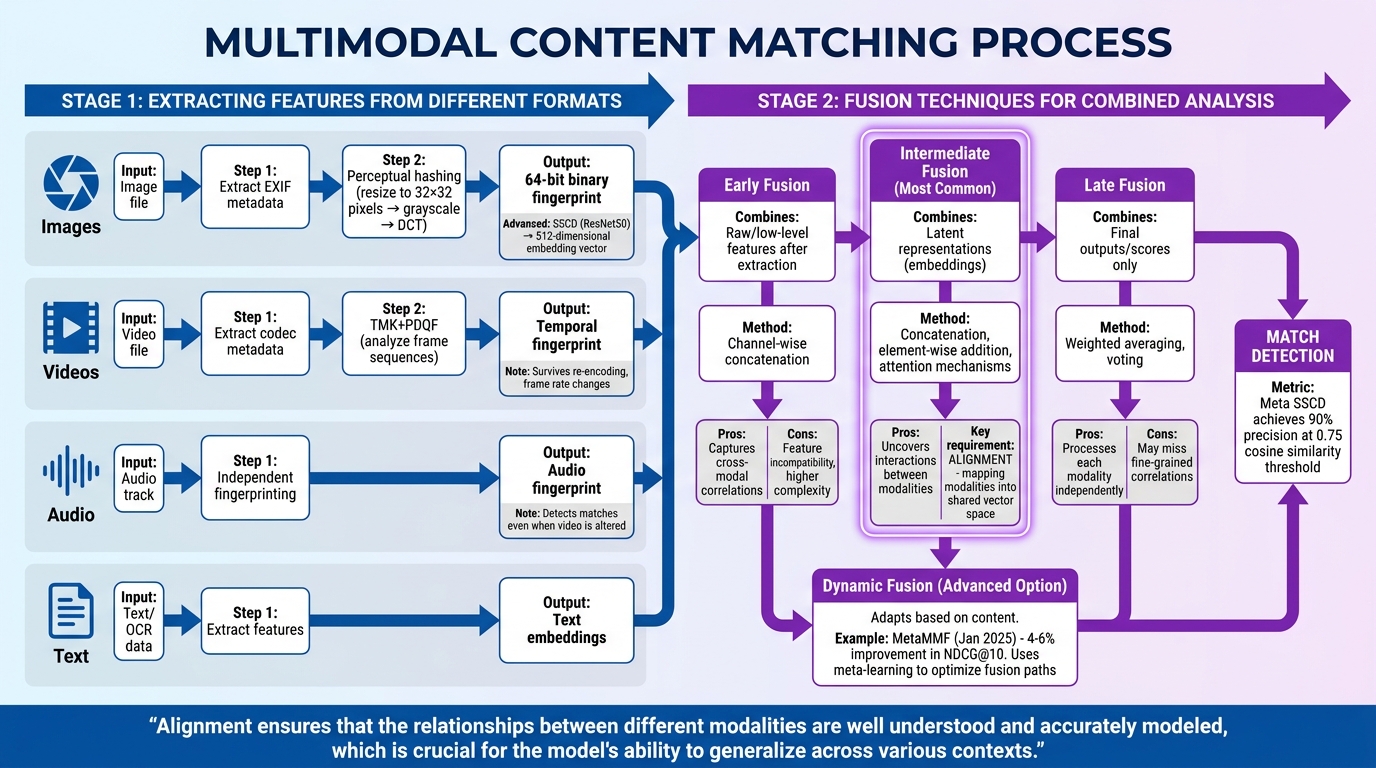
How Multimodal Content Matching Works: From Feature Extraction to Fusion
This process is the backbone of effective digital asset protection, tying into AI watermarking for images and videos and other authentication methods.
Extracting Features from Different Formats
Multimodal matching starts by pulling key features from various media formats. Platforms analyze metadata – like EXIF data for images or codec details for videos – to generate initial authenticity signals [2][3].
Perceptual hashing then steps in, creating a compact "fingerprint" for the content. For instance, an image is resized to 32×32 pixels, converted to grayscale, and processed using a Discrete Cosine Transform (DCT). The result is a 64-bit binary fingerprint that can be compared using Hamming distance [3].
For more advanced analysis, deep learning models such as Meta‘s SSCD use a ResNet50 backbone to generate 512-dimensional embedding vectors. These embeddings capture the semantic essence of an image, focusing on its visual identity rather than pixel-level details.
"SSCD is built on a ResNet50 backbone… It takes an image resized to 224×224 pixels as input and produces a 512-dimensional L2-normalized embedding vector as output." – MetaGhost [2]
Video analysis takes this further with tools like TMK+PDQF (Temporal Match Kernel + PDQ Features). These systems analyze frame sequences, ensuring matches hold up even after re-encoding, frame rate changes, or partial editing [3]. Similarly, audio tracks are fingerprinted independently, allowing systems like YouTube Content ID to detect matches even when the accompanying video has been heavily altered [2][3]. Platforms often layer these detection methods, using metadata and perceptual hashing as quick pre-filters before relying on resource-intensive AI models for final, detailed comparisons [3].
After extracting features, the next step is combining these modalities through sophisticated fusion techniques.
Fusion Techniques for Combined Analysis
Once features are extracted, they need to be merged effectively. Intermediate fusion is a common approach, where each modality – be it text, image, audio, or video – is processed into a latent representation (embedding). These embeddings are then fused using methods like concatenation, element-wise addition, or attention mechanisms [6], enabling the system to uncover interactions between modalities.
Early fusion combines raw or low-level features right after extraction, often through channel-wise concatenation. While it captures cross-modal correlations well, it can face challenges like feature incompatibility and higher model complexity [4][6]. On the other hand, late fusion processes each modality independently, merging only the final outputs or scores using strategies like weighted averaging or voting [4][6].
Dynamic fusion offers a more adaptive solution. Unlike static methods, dynamic fusion modifies its approach based on the content. For example, researchers introduced MetaMMF in January 2025, a dynamic multimodal fusion model designed for micro-video recommendations. By leveraging meta-learning to optimize fusion paths for each sample, MetaMMF outperformed static fusion models by 4–6% in NDCG@10 metrics [4].
The success of these fusion methods hinges on proper alignment – mapping different modalities into a shared vector space before combining them. Alignment ensures that relationships between diverse data types are accurately captured. For instance, Meta’s SSCD model achieves 90% precision on the DISC2021 benchmark when using a cosine similarity threshold of 0.75 [2][3].
"Alignment ensures that the relationships between different modalities are well understood and accurately modeled, which is crucial for the model’s ability to generalize across various contexts." – arXiv Survey [5]
sbb-itb-738ac1e
Applications of Multimodal Content Matching
The techniques behind multimodal content matching are the backbone of systems that safeguard digital assets, verify ownership, and improve content discovery across industries.
Content Protection and Anti-Piracy
Platforms handling massive daily uploads use layered detection systems to identify pirated material before it spreads. For instance, Instagram processes over 100 million uploads daily through a detection pipeline combining metadata, perceptual hashing, and AI-driven deep learning [2]. Similarly, YouTube’s Content ID relies on a database of over 100 million files supplied by rights holders. It uses multimodal video matching to fingerprint both audio and video tracks, ensuring content matches even when one medium is altered [3].
Another powerful tool is invisible digital watermarking, which acts as an embedded serial number within media. These watermarks endure transformations like cropping, compression, and re-encoding [1]. InCyan‘s Tectus, for example, offers blind watermarking, allowing rights holders to verify ownership without needing the original file. For large-scale operations, InCyan‘s Idem platform uses AI-powered multimodal matching to identify ownership even when only 10% of the original asset remains, despite edits like memes or compression [1][3].
"Properly designed invisible watermarks can survive those transformations and act as a latent serial number for the work itself." – Nikhil John, InCyan [1]
Meta’s TMK+PDQF video system generates about 20,000 false positives daily [3]. Meanwhile, ScoreDetect combines watermarking with web scraping to achieve a 95% success rate in detecting infringements and over 96% effectiveness in takedown actions.
Content Authentication and Ownership Verification
Beyond detection, verifying content ownership is essential for legal protection and trust. Blind detection methods, which verify ownership without needing the original unmarked file, are critical for industries like media, education, and law [1]. YouTube’s Content ID, for example, has processed over 600 years’ worth of content duration, managing copyright for approximately 500 hours of video uploaded every minute [8].
Systems also detect copyright violations by spotting cross-modal inconsistencies. For instance, a legitimate image might be paired with an unauthorized or misleading caption [7][10]. The MultiCheck framework improved performance on the Factify-2 benchmark by 47% in macro-F1 by analyzing text, images, and OCR data together [10]. In healthcare, where 40% of clinical notes are handwritten, multimodal AI combines visual/OCR data with text for content verification [9].
Ownership verification also benefits from blockchain-based timestamping, which creates a traceable record without storing the actual content. ScoreDetect’s blockchain system captures a content checksum, providing verifiable proof of ownership. For WordPress users, a plugin automatically timestamps published or updated articles, improving SEO while establishing a chain of custody. InCyan’s enterprise solutions – Discovery, Identification, Prevention, and Insights – offer comprehensive protection from content creation to enforcement, all powered by AI-driven technology.
Dynamic Media Retrieval and Targeting
Thanks to advancements in multimodal matching, media retrieval and targeting have become smarter and more dynamic. Visual search now allows users to find items through natural language descriptions, like "white shoes with red stripes", rather than relying on exact keywords [12]. This shift to semantic search is transforming eCommerce by integrating product visuals with transaction data, streamlining inventory management and personalized promotions [11]. By 2030, the global multimodal AI market is expected to reach $10.89 billion [11].
In media and entertainment, intelligent search within vast video libraries makes it possible to locate specific moments – like "John jumping off a cliff" – without needing manual tagging [12]. Advertising platforms also benefit, using contextual targeting to analyze video signals (visuals, audio, and text) for placing ads in the most relevant environments, boosting ad performance [12][13]. Meta’s SSCD model achieves 90% precision in detecting content copies, using 512-dimensional embedding vectors to capture semantic identity at a cosine similarity threshold of 0.75 [2].
"In an era dominated by structured data and textual documents, the question arises: how to harness the rich potential of visual content? Pixels now yield actionable insights." – Sergey Astretsov, Coactive [12]
InCyan’s Certamen platform offers image rights holders a centralized view of their media’s prominence across digital news outlets, replacing guesswork with automated intelligence for smarter licensing decisions. For rapid enforcement, InCyan’s Indago system combines high-speed search with forensic precision, de-indexing unauthorized links in under 60 minutes.
Benefits and Challenges of Multimodal Content Matching
Benefits of Multimodal Content Matching
Multimodal content matching offers a robust layer of security and persistence that goes beyond what single-mode systems can achieve. Unlike metadata, which can be easily stripped during re-exporting, technologies like invisible watermarks and perceptual hashes remain intact even after common modifications like cropping, compression, or color tweaks [1][2]. Advances in deep learning, such as Meta’s SSCD model, take this a step further by analyzing "visual meaning" – focusing on shapes, textures, and semantic structures rather than just pixel patterns. This makes the system resilient to surface-level changes like applying filters or mirroring [2].
Another advantage is multi-layered verification. By combining visual and audio fingerprinting, these systems ensure that even if one component is altered, the other can still confirm ownership [2]. This is particularly important in an era where generative AI makes content manipulation easier than ever. Multimodal matching acts as a safety net, linking altered or synthetic media back to its original source and licensing state [1]. For example, InCyan’s Idem platform can detect ownership even when as little as 10% of the original content remains.
Modern systems also support blind detection on a large scale. This means ownership can be verified without needing access to the original unmarked master file, which eliminates the need to store unmarked originals. This capability is critical when scanning billions of assets across third-party platforms, reducing storage demands while maintaining accuracy [1].
Challenges in Implementation
Despite its benefits, implementing multimodal content matching comes with its share of challenges. One of the biggest hurdles is integrating data from different formats, such as text tokens, pixel matrices, and waveforms, each with varying scales and dimensions [15][17]. The sheer volume of data can be staggering; for instance, a smart car can generate 100 GB of data per second [15].
Another issue arises with missing modalities. If a data source – like the audio track in a video file – is incomplete, the system’s performance can take a hit [14]. There’s also the risk of retrieval drift, where semantic coherence deteriorates because different modalities are stored in separate vector spaces. This can lead to mismatched results. In fact, enterprise-level multimodal Retrieval-Augmented Generation (RAG) systems fail in 73% of deployments due to single-modality retrieval issues that don’t align with cross-modal requirements [16].
High computational and storage demands add another layer of complexity, especially when dealing with high-resolution media like videos or medical images [15]. Balancing factors like imperceptibility, robustness, and data capacity is also a challenge [1]. Tiered storage solutions – using hot, warm, and cold storage tiers – can help manage these demands effectively [15]. Platforms like InCyan’s Blueprint address these challenges by combining AI-driven content protection with digital asset management, providing a centralized and secure way to manage visual libraries while maintaining strong content protection.
Overcoming these challenges requires thoughtful fusion strategies, as explored in the next section.
Comparison of Fusion Techniques
Different fusion approaches come with their own tradeoffs in terms of accuracy, flexibility, and computational cost. Here’s a breakdown of the primary techniques:
| Fusion Technique | Precision/Accuracy | Flexibility | Computational Cost |
|---|---|---|---|
| Early Fusion | Lower for complex interactions | Low; assumes direct compatibility | Low; treats input as unimodal |
| Intermediate Fusion | High; captures correlations across modalities | High; supports varied architectures per modality | Moderate; uses multiple feature extractors |
| Late Fusion | High for heterogeneous data; may miss fine-grained correlations | High; handles missing modalities well | Moderate to High; trains multiple models |
- Early Fusion: Combines raw data or features from all modalities before modeling. While efficient, it can struggle with high-resolution data due to "attention bottlenecks" [18].
- Intermediate Fusion: Processes each modality separately before combining their representations. This approach excels in capturing semantic correlations and works well in zero-shot scenarios [18].
- Late Fusion: Aggregates predictions from individual models for each modality. It’s highly flexible, especially when dealing with incomplete data, but may overlook finer inter-modal relationships [19].
To implement multimodal content matching effectively, organizations should build modular pipelines. This allows for independent scaling of ingestion, preprocessing, and fusion for each modality [15]. Using content-hash caching for encoder outputs can also save time and resources by avoiding the need to re-encode large datasets [16]. Platforms like InCyan’s Idem and Blueprint exemplify how these strategies can be integrated to deliver scalable and accurate solutions for content protection and detection.
Conclusion
Multimodal content matching has become a crucial tool for protecting digital assets in an era where platforms handle over 100 million uploads daily, and generative AI enables advanced content manipulation [2]. By embedding protection directly into the media signal, techniques like invisible watermarking and fingerprinting ensure assets remain traceable to their original source – even when metadata is stripped during upload.
With these technological advancements, organizations must align their strategies to leverage these tools effectively. The technology captures deep visual semantics, maintaining accuracy even after alterations like inpainting, style transfer, or frame interpolation – methods that often bypass content matching algorithms. Cross-modal validation, such as using audio fingerprinting to confirm ownership of heavily modified video content, adds a critical layer of defense for enforcing rights in today’s fast-evolving media landscape.
Companies adopting multimodal content matching can integrate core components like Discovery, Identification, Prevention, and Insights into their workflows. Platforms like InCyan’s Idem can identify ownership even when only 10% of the original asset remains intact, while solutions like Blueprint combine asset management with AI-driven protection for large-scale operations. Modular pipelines further enhance efficiency by processing metadata checks, perceptual hashing, and deep learning analysis simultaneously – delivering results within seconds of a content upload.
The market for multimodal AI is expected to grow to $4.5 billion by 2028, with a 35% CAGR from 2023 to 2028, highlighting the growing need for solutions that go beyond single-modality approaches [20]. This shift points to a future where automated, efficient workflows are vital for managing the complexities of digital content.
For organizations managing extensive and varied digital assets, these advancements bring significant operational benefits. Automated workflows reduce the need for manual oversight, tiered storage strategies help control costs, and blind detection capabilities verify content without access to original master files – essential for large-scale platform scanning [1]. Multimodal content matching has firmly established itself as a cornerstone of digital asset protection in today’s rapidly evolving media environment.
FAQs
How is multimodal content matching different from metadata checks?
Multimodal content matching takes things a step further than traditional metadata checks. Instead of just relying on file details or tags, it uses AI to directly analyze and combine various types of content – like images, videos, audio, and text. This method focuses on uncovering patterns and connections within the content itself, leading to much more precise results.
Can it still match my media after heavy edits or AI changes?
Yes, it absolutely can. Multimodal content matching is designed to recognize and identify your media even after it has undergone significant edits or AI-driven modifications. Advanced models analyze and interpret content by leveraging multiple data points, ensuring its integrity remains traceable. When combined with powerful AI tools like ScoreDetect, the process becomes even more effective, offering enhanced protection and verification for your content.
What data and compute are required to run this at scale?
To successfully run multimodal content matching on a large scale, you need access to extensive datasets that cover various formats like images, videos, audio, and text. These datasets play a critical role in training AI models to recognize and link complex patterns across different types of media.
Equally important is the use of high-performance hardware, such as GPUs or TPUs, which can handle the intensive computational demands. Scalable storage solutions are also a must, as they help manage the massive datasets involved. A well-designed infrastructure ensures smooth and accurate operations, especially when combined with advanced enterprise tools like InCyan’s solutions for content protection and management.