How AI improves audio watermarking accuracy involves embedding digital signals into audio to protect intellectual property and verify authenticity. While earlier techniques focused on resilience and subtlety, modern approaches must also address efficiency due to high computational demands. Models like AudioSeal and WavMark process thousands of audio hours, impacting costs and energy use.
Four key metrics evaluate efficiency:
- Signal-to-Noise Ratio (SNR): Measures distortion. Higher values (40–60 dB) mean better audio quality. This is often achieved through psychoacoustic audio watermarking, which hides data within frequencies less audible to humans.
- Perceptual Evaluation of Speech Quality (PESQ): Rates listener-perceived quality. Scores above 4.0 are nearly indistinguishable from the original.
- Bit Error Rate (BER): Indicates watermark robustness. Lower percentages show higher accuracy, even under compression or noise.
- Computational Complexity: Measured in GFLOPs/s, it impacts energy use and scalability.
Durability against attacks (e.g., compression, noise, AI manipulation) is also critical. Neural codecs like Encodec pose challenges by removing imperceptible details, often reducing watermark accuracy. Trade-offs exist between fidelity, robustness, and efficiency, with no single model excelling at all metrics.
WAKE, developed in 2025, advanced watermarking with key-controlled security, achieving low BER and surviving double-watermarking scenarios. Tools like ScoreDetect combine watermarking with automated takedown systems to protect digital audio assets effectively.
Balancing audio quality, durability, and efficiency ensures watermarking systems meet specific needs, whether for music distribution or forensic tracking.
DeepMind SynthID: Invisible AI Watermarks Explained
sbb-itb-738ac1e
Core Metrics for Measuring AI Audio Watermarking Efficiency
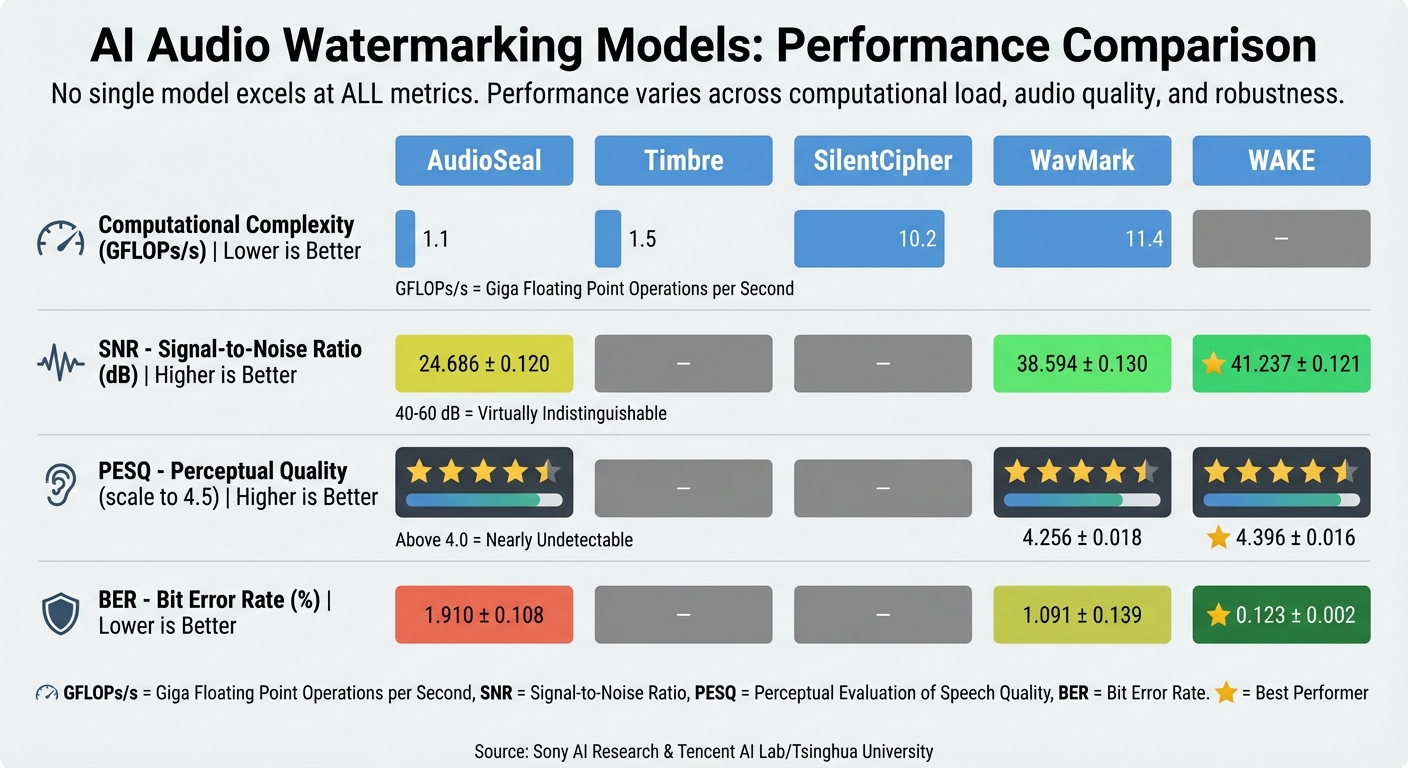
AI Audio Watermarking Models: Performance Metrics Comparison
When evaluating the efficiency of AI audio watermarking, four main metrics come into play: SNR, PESQ, BER, and computational complexity. Together, they help assess the balance between audio fidelity, perceptual quality, decoding robustness, and resource use.
Signal-to-Noise Ratio (SNR)
SNR measures how well the watermarked audio retains the original signal’s integrity. A higher SNR means less distortion. For example, the WAKE model reached an impressive SNR of 41.237 dB, surpassing AudioSeal’s 24.686 dB and WavMark’s 38.594 dB [3]. To put this into perspective, SNR values between 40–60 dB are virtually indistinguishable from the original audio, while values in the 20–40 dB range may introduce audible but tolerable distortions [1].
As Yaoxun Xu and colleagues explained:
"SNR and PESQ do not directly reflect human perceptual evaluation. For example, a slight bursting sound is observed at the watermarked audio edges… without BroadWeight constraints, WAKE shows significant energy stacking in the high-frequency region." [3]
Perceptual Evaluation of Speech Quality (PESQ)
PESQ offers a deeper look into the subjective audio experience by assessing quality from a listener’s perspective. This metric, standardized under ITU-T P.862, rates audio on a scale up to 4.5. The WAKE model scored 4.396, outperforming both WavMark (4.256) and AudioSeal (4.316) [3]. For applications where pristine audio quality is critical, maintaining a PESQ score above 4.0 ensures the watermark remains undetectable by human listeners.
Bit Error Rate (BER)
BER evaluates how accurately the watermark can be extracted, even when the audio is compressed or subjected to noise. A lower BER indicates stronger robustness. Under controlled conditions, the WAKE model recorded a BER of just 0.123%, while AudioSeal and WavMark posted values of 1.91% and 1.09%, respectively [3]. However, challenges emerge with multiple watermarks. For instance, AudioSeal’s BER skyrocketed to 46.75% when a second watermark was embedded, highlighting the difficulty in maintaining accuracy under such conditions [3].
Computational Complexity
Efficiency in computational resources is crucial, especially for large-scale operations. Computational complexity, measured in Giga Floating-Point Operations per second (GFLOPs/s), directly affects energy use and infrastructure costs. AudioSeal operates at 1.1 GFLOPs/s, while SilentCipher and WavMark require 10.2 GFLOPs/s and 11.4 GFLOPs/s, respectively [1]. This difference can significantly impact platforms handling thousands of audio files daily. Leveraging architectural innovations like Invertible Neural Networks (INN) can further optimize performance, allowing for reusable processes during embedding and decoding [3].
| Model | Complexity (GFLOPs/s) | SNR (dB) | PESQ | BER (%) |
|---|---|---|---|---|
| AudioSeal | 1.1 | 24.686 ± 0.120 | 4.316 ± 0.010 | 1.910 ± 0.108 |
| Timbre | 1.5 | – | – | – |
| SilentCipher | 10.2 | – | – | – |
| WavMark | 11.4 | 38.594 ± 0.130 | 4.256 ± 0.018 | 1.091 ± 0.139 |
| WAKE | – | 41.237 ± 0.121 | 4.396 ± 0.016 | 0.123 ± 0.002 |
Source: Sony AI Research [1] and Tencent AI Lab/Tsinghua University [3]
Measuring Watermark Durability Against Distortions and Attacks
Watermark durability ensures that protections hold up under real-world conditions. Audio files rarely remain untouched – they’re often compressed, re-encoded, mixed with noise, or subjected to deliberate attacks. These durability tests complement earlier metrics like audio quality and computational efficiency by focusing on how well watermarks survive real-world challenges.
Distortions can be grouped into three main categories: Signal-Level (e.g., compression, noise, filtering), Physical-Level (e.g., re-recording, environmental noise), and AI-Induced (e.g., voice conversion, text-to-speech). Among these, neural compression stands out as the greatest threat. According to Sony AI researchers:
"Neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions." [1]
Neural codecs like Encodec and Descript Audio Codec strip out imperceptible details – precisely where watermarks are embedded. When subjected to neural compression, bitwise accuracies often fall below 0.5, and full-message accuracies nearly disappear [2].
False Positive and False Negative Rates
Once watermark durability is assessed, the next step is evaluating detection reliability through false-positive and false-negative rates. These metrics are crucial: a high False Negative Rate (FNR) suggests watermarks can be easily removed, while a high False Positive Rate (FPR) means clean audio might wrongly be flagged as watermarked. Under distortion-free conditions, leading models achieve true-positive rates between 0.97 and 1.0, with zero false negatives [2]. However, performance drops sharply when distortions are introduced.
In May 2025, Sony AI researchers tested four major watermarking models – AudioSeal, SilentCipher, Timbre, and WavMark – against 20 types of distortions applied to music, speech, and environmental sounds. Two intensity levels were used: "Loose" (imperceptible, SNR 40–60 dB) and "Strict" (audible but acceptable, SNR 20–40 dB). This dual-threshold approach provides insight into when and how watermarks fail [1].
Attack-Specific Survival Rates
Different attacks exploit different weaknesses in watermarking systems. A 2025 study examined 22 watermark removal techniques across 109 configurations, revealing no watermarking scheme that could withstand every type of distortion tested [4]. For example, AudioSeal resists standard MP3 compression effectively but fails under polarity inversion and phase shifts [2]. Similarly, SilentCipher is resilient to noise but struggles with time stretching [2].
| Attack Category | Common Examples | Typical Impact |
|---|---|---|
| Neural Compression | Encodec, Descript Audio Codec | Bitwise accuracy often drops below 0.5 |
| Signal-Level | Gaussian noise, MP3/AAC, filtering | Moderate; depends on "Loose" vs "Strict" settings |
| Temporal/Phase | Time stretching, polarity inversion, phase shifts | Can completely break specific algorithms |
| Physical-Level | Re-recording, environmental noise | Disrupts fine-grained signal patterns |
| AI-Induced | Voice conversion, text-to-speech | Regenerates audio without the watermark |
Embedding a second watermark can severely compromise the first. For instance, when AudioSeal was tested with a second embedding, the first watermark’s Bit Error Rate (BER) rose to 46.75%, demonstrating how layering can undermine integrity [3].
Trade-offs in AI Audio Watermarking Metrics
When evaluating watermark durability, it becomes clear that balancing key metrics in audio watermarking is no simple task. There’s an inherent push-and-pull among imperceptibility, robustness, and capacity [2]. Improving one, like robustness, often comes at the cost of another – typically audio fidelity.
Take the SilentCipher model, for instance. It boasts a stellar SI-SNR of 49.13 dB and a MOS-LQO of 4.98, indicating excellent audio quality. But when retrained to withstand stricter attacks, its SI-SNR drops to 31.80 dB. On the other hand, the Timbre model, which operates at a much lower SI-SNR of 21.91 dB, excels in handling distortions, showing higher robustness [2]. The choice of model ultimately hinges on whether pristine audio quality or resistance to attacks is more critical.
It’s also worth noting that a high SNR doesn’t always equate to better perceived quality. Metrics like MOS-LQO or Mel Cepstral Distance are often better indicators of the listener’s experience. However, neural codecs can complicate things – they strip away imperceptible details, leaving watermark signals vulnerable. In extreme cases, this can reduce bitwise accuracy to nearly zero under strict compression [2].
Comparing Metrics Side by Side
The table below highlights how four leading AI watermarking models handle fidelity, perceived quality, and robustness. Each model reflects specific trade-offs, showing that no single solution excels across all metrics.
| Model | SI-SNR (Fidelity) | MOS-LQO (Perceived Quality) | Robustness (Strict Attacks) |
|---|---|---|---|
| SilentCipher (SC) | High (49.13 dB) | High (4.98) | Lower (vulnerable to time-stretching) |
| Timbre (TI) | Low (21.91 dB) | Low (4.59) | Highest (most resilient to distortions) |
| AudioSeal (AS) | Moderate (22.73 dB) | High (4.93) | Moderate (struggles with polarity inversion) |
| WavMark (WM) | Moderate (35.89 dB) | High (4.91) | Moderate (vulnerable to MP3 compression) |
These comparisons highlight the need to carefully weigh fidelity and robustness when designing watermarking models for specific applications.
When training custom models, setting a hard lower limit for the Signal-to-Distortion Ratio (SDR) can help maintain a balance. For example, "loose" settings (imperceptible, SNR 40–60 dB) are ideal for high-quality music distribution. Meanwhile, "strict" settings (audible but acceptable, SNR 20–40 dB) are better suited for forensic speech tracking, where robustness is key [2].
Conclusion
AI audio watermarking is a balancing act between three critical factors: imperceptibility, robustness, and computational complexity. Each plays a vital role, but none can stand alone. For instance, imperceptibility – measured by metrics like SNR and PESQ – ensures the watermark doesn’t degrade audio quality. On the other hand, robustness, tracked through BER and survival rates against attacks, determines how well the watermark holds up under stress. Meanwhile, computational complexity dictates whether the solution can scale for practical use. Since no single metric tells the whole story, businesses must prioritize based on their specific needs, whether that’s perfect audio fidelity for music or durability for forensic tracking.
The development of WAKE in June 2025 by Tencent AI Lab and Tsinghua University highlights how far the field has come. WAKE introduced key-controllable security, achieving a BER of 0.12% with the correct key and 50.09% with an incorrect one, effectively preventing unauthorized extraction – even from publicly shared models [3]. Impressively, WAKE also handled double-watermarking scenarios with BERs of 1.25% and 2.71%, while baseline models completely failed [3].
However, challenges remain, particularly with neural compression. Sony AI researchers pointed out in May 2025 that neural codecs, designed for high-efficiency compression, often disrupt embedded watermarks because both operate in the same imperceptible domain [1]. This makes it especially hard for watermarks to survive compression, underscoring the need for rigorous testing across various distortion types.
To tackle these challenges, advanced tools like ScoreDetect have emerged. Combining invisible watermarking with automated discovery, takedown capabilities, and blockchain timestamping, ScoreDetect secures digital audio assets against distortions like noise, filtering, compression, and more [1]. Its automated takedown system boasts a success rate exceeding 96%, while maintaining professional audio quality for industries like media, entertainment, and digital content distribution.
Ultimately, fine-tuning these metrics not only protects audio content but also improves the energy efficiency of AI systems. By understanding and optimizing these factors, organizations can align technical performance with their broader business goals.
FAQs
Which metric matters most for my use case: SNR, PESQ, BER, or compute?
When deciding on the best metric, it all comes down to your priorities. If you’re focused on audio quality, PESQ is your go-to – it assesses how well the watermarked audio aligns with the original. For those prioritizing robustness, metrics like SNR (which measures how well the watermark stands up to noise) and BER (which evaluates detection accuracy under challenging conditions) are essential. On the other hand, if efficiency in resource-constrained settings is your main concern, look at Compute. However, keep in mind that while Compute measures efficiency, it doesn’t directly reflect effectiveness. Ultimately, your choice depends on whether clarity, durability, or performance matters most to you.
How do neural codecs like Encodec break audio watermarks?
Neural codecs, such as Encodec, can interfere with audio watermarks due to how they compress and reconstruct audio using deep learning techniques. These systems work by encoding audio into a latent space and then reconstructing it, a process that often involves lossy compression or alterations. As a result, watermarks embedded in the audio may be distorted or entirely removed. Since neural codecs focus on maintaining perceptual audio quality rather than preserving watermark integrity, watermarks are unlikely to withstand challenges like noise, re-sampling, or other signal processing methods.
What are acceptable false positive and false negative rates in detection?
Acceptable false positive rates generally fall between 0.1% and 1%, ensuring minimal misidentification. On the other hand, false negative rates are often maintained below 5% to ensure reliable detection. The exact thresholds can vary depending on the specific watermarking method and the type of content being analyzed.

