If your protection stack checks only one media type at a time, it will miss piracy that jumps from text to image, video to audio, or article to voice-over.
I’d sum up the article like this: multimodal AI links related content across formats, watermarking and hashing help prove source and time, and distributed systems help large teams search and act on matches with less delay. That matters because content theft can lead to lost traffic, lost licensing value, and lost ad or subscription income.
Here’s the short version:
- Multimodal AI checks text, images, audio, and video in one match layer.
- It can still spot reuse after cropping, clipping, compression, re-encoding, or partial edits.
- Fingerprinting reads the file and creates a math-based signature.
- Invisible watermarking places a hidden signal in the media that can survive many edits.
- SHA-256 hashing + blockchain timestamping help show when a file existed and who claimed it.
- Distributed training and search help large libraries process more assets with lower lag.
- The business goal is simple: find copied content, prove ownership, and support takedowns.
For me, the main takeaway is plain: detection alone is not enough. You need a system that can match reused media, log proof, and support enforcement.
| Layer | What it does | Why it matters |
|---|---|---|
| Multimodal AI | Matches content across media types | Finds reuse that single-format tools may miss |
| Fingerprinting | Builds a signature from the file | Helps locate copied or edited media |
| Watermarking | Embeds a hidden signal | Helps verify source after conversion or compression |
| Timestamping | Records a hash and ownership claim | Helps support proof of date and control |
| Distributed search | Spreads processing across nodes | Helps large teams monitor at scale |
Below, I break down the article in plain English and focus on what matters most for enterprise content protection.
How multimodal AI detects unauthorized reuse across media types
Once content is out in the world, the hard part begins: finding reuse after someone has edited it, repackaged it, or shifted it into a different format. Multimodal AI helps by comparing text, images, audio, and video inside one shared model, which lets it spot unauthorized reuse fast.
How images, video, audio, and text are matched together
Text, images, audio, and video are checked in one shared system. Because of that, the model can connect related content even when it shows up in different formats.
That matters because pirates rarely copy an asset in a neat, one-to-one way. They may grab only part of it, trim it down, or move it into a new medium. That’s where a shared model stands out.
That shared semantic view matters most when pirates split one asset across formats.
Why multimodal matching still works across formats
The model follows meaning, not just file type. So it can still match content after it has been repackaged into another medium.
In plain English, matching can survive:
- reformatting
- repackaging
- partial reuse
That’s where single-format tools often fall short.
For enterprises, this means one detection layer can catch reuse across channels without a separate tool for each format.
| Approach | How it helps detection |
|---|---|
| Single-format detection | Checks one media type at a time |
| Multimodal detection | Builds a shared view from text, images, audio, and video |
| Retrieval-augmented analysis | Improves contextual similarity detection across formats |
That shared view is what lets the system catch reuse across formats.
Detection is only the first step; the next layer is proving ownership and acting on it.
sbb-itb-738ac1e
Where watermarking, timestamping, and proof of ownership fit
Unauthorized copies are only half the problem. You also need to show where the asset came from and who controlled it over time. That’s where watermarking and timestamping come in. They act as the proof layer.
Invisible watermarking versus AI fingerprinting
These two tools do different jobs, and people mix them up all the time.
AI fingerprinting creates a unique mathematical signature from the content itself. It doesn’t change the file at all – it simply reads it. That makes fingerprinting fast to use at scale when you need to find matches across the web, even if the content has been edited or reused in part.
Invisible watermarking works differently. It embeds a signal inside the media itself. That embedded signature can survive re-encoding, compression, and format conversion that would wipe out normal file-level metadata. InCyan’s Tectus uses a blind watermarking method for images, video, and audio, so you don’t need the original unwatermarked file to pull the signature from a suspected copy.
One detail matters here: watermark verification depends on a confidence threshold. Use tighter thresholds for legal claims and looser ones for internal provenance logging.
How ScoreDetect adds blockchain-backed proof without storing the asset
Once you’ve found a match, the next step is keeping evidence in a form that can hold up in a claim.
Watermarking and fingerprinting help prove what your content is. ScoreDetect, a product of InCyan, helps prove when it existed and who owned it – without storing the file itself.
The platform takes a SHA-256 cryptographic checksum of your content and records it on the blockchain along with ownership metadata. If someone later challenges the asset, you can recalculate the hash from the original file and compare it with the on-chain record. If they match, you have verifiable proof that the file existed, unchanged, at that moment in time.
That’s the key shift. A detection event by itself is just a signal. The outputs from ScoreDetect – verification records and ownership certificates – help turn that signal into something you can act on. For enterprises that publish often, the WordPress plugin automatically timestamps every article at publication or update, which gives you a clean starting point for the chain of custody.
Together, these layers turn a match into an enforceable record and support the scale needed to work across an entire content library.
Why distributed training and distributed search are required at scale
Enterprise content protection is, at its core, a scale problem. As content libraries get larger and live analysis stretches across text, images, and video, centralized systems start to drag. And detection alone isn’t enough. Proof only matters if the system can find matches and act on them fast.
How distributed training improves coverage and accuracy
Distributed training helps a model learn patterns across text, images, audio, and video, then bring them together in one shared match space [1].
That becomes important when the same asset shows up in another format, or when someone has trimmed, cropped, or partly changed it. With fast access to reference data, the system can keep match quality high in real time [1].
How distributed comparison supports real-time anti-piracy operations
In enforcement, speed makes all the difference. Distributed comparison cuts latency by spreading processing across nodes instead of sending everything through one central system [1].
Here’s what that looks like in practice:
- Different nodes process different asset types at the same time
- Their outputs feed into one matching layer
- The system can respond faster when new infringements appear
InCyan’s Indago platform uses this kind of search enforcement approach to help de-index infringing links quickly. That keeps response cycles short when piracy shows up [1].
Centralized versus distributed protection architecture: a comparison
The trade-off is pretty simple:
| Feature | Centralized Architecture | Distributed Architecture |
|---|---|---|
| Scalability | Limited by central server capacity and data volume | High; scales by processing data closer to the source |
| Latency | Higher; prone to processing delays in live monitoring | Lower; enables real-time analysis and faster response |
| Security | Higher risk for sensitive proprietary information | Lower exposure of sensitive data |
| Accuracy | Standard monitoring capabilities | Improved through retrieval-augmented multimodal models |
| Suitability | Small to medium asset libraries | Large-scale, high-volume enterprise libraries |
Once detection is distributed, the next step is turning matches into takedowns and enforceable records.
How an end-to-end protection stack turns AI detection into business outcomes
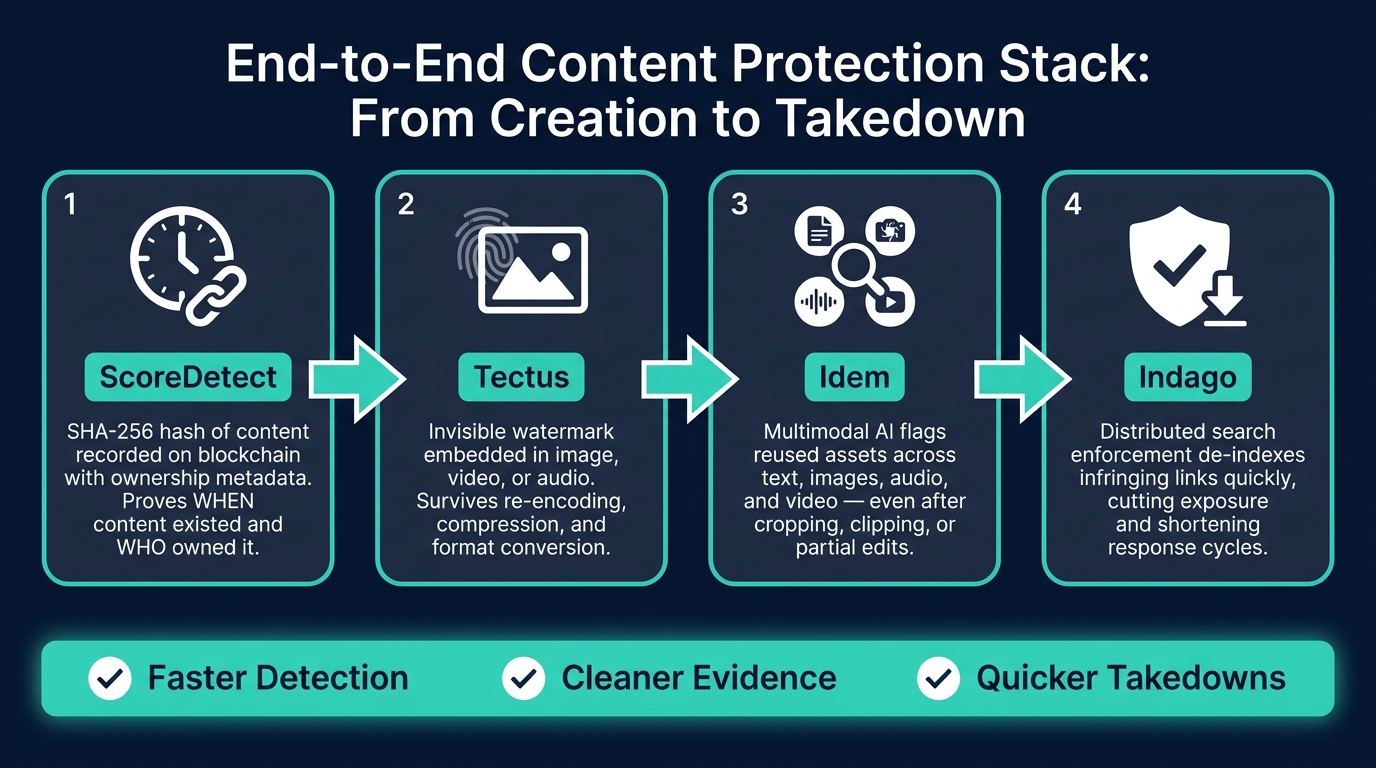
End-to-End Content Protection Stack: From Creation to Takedown
Detection by itself doesn’t protect revenue. What matters is the full chain from proof to action. Multimodal AI helps because it connects scattered signals into one workflow that runs from content creation all the way to removal.
A clear workflow from content creation to takedown
Here’s how the stack works from start to finish.
A practical workflow has four stages. ScoreDetect timestamps ownership. Tectus adds a second proof layer. Idem flags reused assets even after edits. Indago cuts exposure by removing infringing listings.
Once proof is in place, monitoring and removal can start. That evidence becomes far more useful when it’s matched with live monitoring and search enforcement. From there, distributed monitoring turns proof into action. When a match appears, blockchain timestamps and quantitative evidence create an audit trail for enforcement. Delisting notices then move the case from detection to removal.
The result is faster detection, cleaner evidence, and quicker takedowns.
Key takeaways for enterprises protecting digital revenue
Three points matter most:
- Multimodal AI finds reuse across formats.
- Distributed systems make enforcement scalable.
- Blockchain timestamps strengthen ownership proof.
The outcome is simple: less revenue leakage, faster takedowns, and stronger ownership records.
FAQs
How does multimodal AI catch cross-format piracy?
Multimodal AI spots cross-format piracy by looking at images, audio, text, and metadata together instead of checking just one format at a time.
That matters because piracy rarely stays unchanged. A file might be cropped, re-encoded, or pitch-shifted, yet the system can still connect it back to the source. It does this by turning those signals into shared semantic fingerprints.
InCyan’s Idem pushes this further by identifying assets from as little as 10% of the original content.
What’s the difference between fingerprinting and watermarking?
Fingerprinting turns an asset into a one-of-a-kind mathematical signature. That makes it possible to spot and identify unauthorized copies, even after changes like cropping, compression, or re-encoding.
Watermarking places an invisible signal inside the content itself. That signal helps prove ownership and trace the asset back to its source, even if someone strips out the metadata. InCyan also uses ScoreDetect for blockchain-based timestamping.
Why is distributed search important for large content libraries?
Distributed search matters when your content library gets big. A single central system can turn into a traffic jam fast, especially when it has to handle massive datasets from many places at once.
With distributed search, collection, processing, and decision-making happen across multiple nodes instead of piling onto one system. That setup cuts latency, reduces bottlenecks, and helps teams move faster.
It also improves resilience and monitoring accuracy across regions. So if one area slows down, the whole system doesn’t grind to a halt.
Pair that with smart indexing and Approximate Nearest Neighbor search, and you get fast, scalable protection for digital assets spread across the globe.