If content matching is slow, enforcement loses value. At enterprise scale, AI systems need to scan text, images, video, and audio across massive libraries in seconds, not minutes.
Here’s the short version:
- Multimodal matching turns many media types into vectors or fingerprints
- Vector search helps teams compare one item against millions or even hundreds of millions of stored assets
- Two layers work together: semantic matching for similarity, then fingerprint checks for identity
- Scale comes from system design: parallel ingestion, batching, sharding, replication, caching, and smart sampling
- Match speed matters most during enforcement, especially for live streams, product drops, and fast-moving search results
- Proof matters too: matching finds likely copying, watermarking helps trace ownership, and blockchain timestamping helps show when a claim existed
A simple way to think about it: AI does the search, fingerprints confirm the match, watermarks add ownership signals, and timestamps add dated proof.
Quick comparison
| Layer | Main job | What it adds |
|---|---|---|
| Multimodal matching | Finds similar or reused content | Detection at scale |
| Watermarking | Places hidden ownership data in media | Traceability after edits |
| Blockchain timestamping | Records a dated checksum | Proof of prior claim |
If you want content protection that works under heavy volume, this is the stack: fast matching, low-latency search, and proof that supports action.
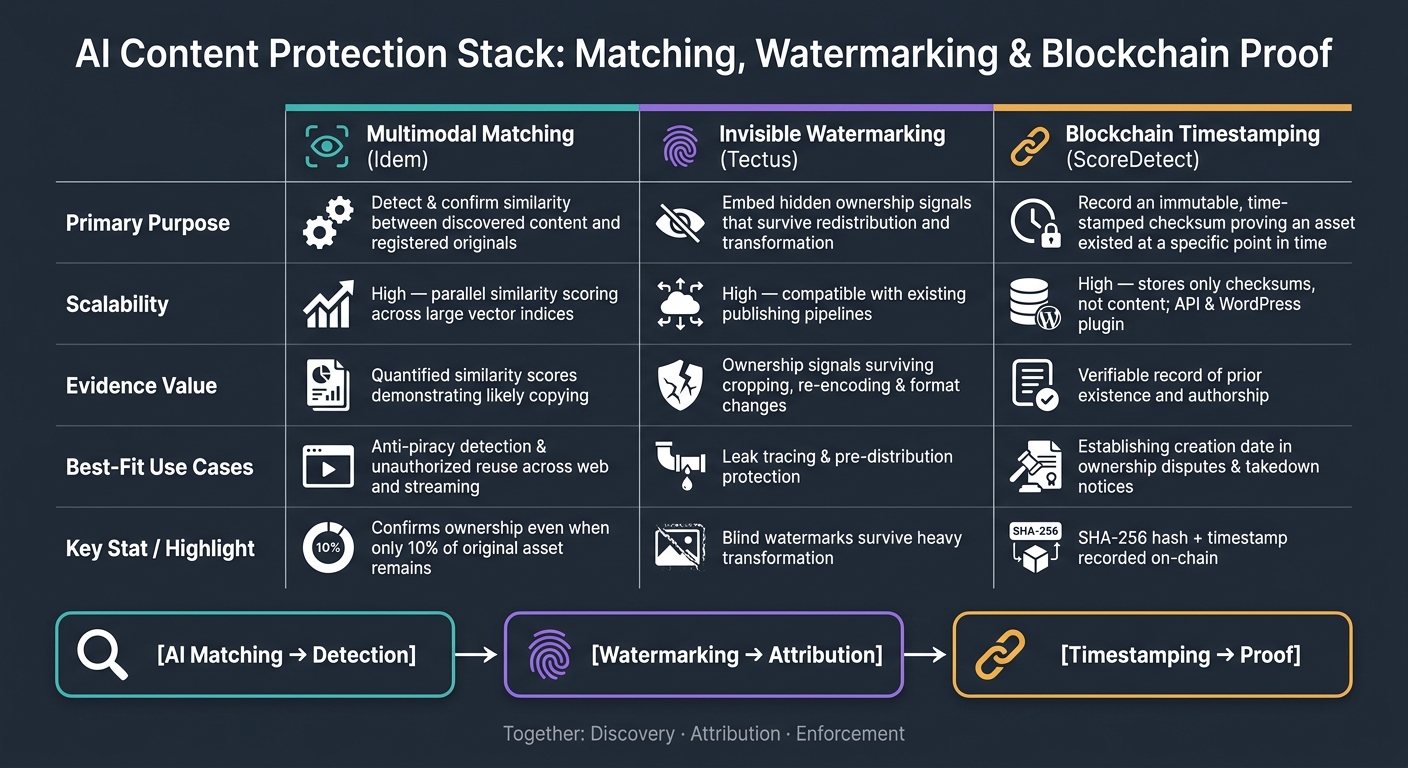
AI Content Protection Stack: Matching, Watermarking & Blockchain Proof
Core AI Components Behind Scalable Matching
Embeddings, fingerprints, and similarity scoring
Two closely related but different representations sit at the heart of any multimodal matching system: semantic embeddings and copy-detection fingerprints.
Semantic embeddings come from deep neural networks. That can mean convolutional models for images and video frames, transformer-based models for text, and spectrogram-based models for audio. These models compress raw content into vectors. Once that happens, similar items end up near each other in vector space, which makes embeddings useful for cross-modal search and for sorting huge asset libraries.
Copy-detection fingerprints do a different job. They’re built to stay stable even when content is cropped, re-encoded, compressed, or covered with text. Put simply, semantic embeddings capture meaning, while fingerprints capture identity. That split is a big deal in rights enforcement, where the task is to show that two assets are the same work, not just about the same thing.
Similarity scoring compares two vectors by checking how close they are in vector space. Cosine similarity is a common metric for text and multimodal embeddings because it ignores scale. In practice, most systems use a two-step flow: fast approximate scoring to narrow the field, then fingerprint verification to confirm the match. That setup helps keep latency low and cloud spend in check.
The next problem is speed. It’s one thing to create these representations. It’s another to search them fast enough when the dataset is massive.
Vector databases and metadata filters
Once embeddings and fingerprints are created, the system has to store and search them without slowing to a crawl. Vector databases handle this with special indexes, most often HNSW (Hierarchical Navigable Small World) graphs or IVF (inverted file) indexes paired with product quantization, to run approximate nearest neighbor (ANN) search. Exact search checks every query against every stored vector, which falls apart once datasets get past the small stage. ANN cuts that work down to milliseconds, even across hundreds of millions of vectors, which makes real-time matching possible at enterprise scale. [1][3]
Metadata filters make that search layer sharper and cheaper. Instead of searching the full index every time, the system can limit queries to a smaller slice first, such as assets owned by one rights holder, content published in a set date range, or records tied to a given jurisdiction. That trims the search space before ANN starts. The payoff is lower compute use, better result relevance, and support for compliance needs by blocking cross-tenant data leakage in multi-tenant platforms.
That search layer is also what lets teams run parallel processing and distributed indexing at scale.
Why multimodal resilience matters for altered content
Enterprise-grade matching systems deal with modification attacks by training fingerprint models with heavy augmentation. In plain English, they feed the model many altered versions of the same asset, with crops, color shifts, compression artifacts, and text overlays, so it learns to ignore those changes when judging content identity.
Research on detecting unauthorized reposts in social media ads shows that a combined visual, audio, and text approach substantially outperforms any single-modality signal. [2] That difference reflects what happens in the wild: people alter content in many ways, so relying on one signal alone leaves gaps. Bringing modalities together leads to fewer missed detections during enforcement.
These resilience methods only pay off if the system can run comparisons fast enough for real-time enforcement.
sbb-itb-738ac1e
Search Images with Text: Build a Multimodal AI Engine (Python Tutorial)
How AI Systems Scale: Parallel Processing, Sharding, and Pipeline Optimization
Once embeddings and fingerprints are in place, scale comes down to one thing: how fast the system can take content in, send it to the right workers, and search it.
Parallel processing across ingestion and analysis
A large ingestion pipeline can’t handle media one file at a time. It needs parallel jobs.
In a production pipeline, images, video, audio, and text are queued as separate jobs as soon as they come in. For video, frame sampling, audio extraction, and speech transcription happen at the same time. Sampled frames go to GPU workers for embeddings, while audio goes to audio feature extraction and speech-to-text services. OCR and metadata normalization for images can run on CPU workers alongside those tasks.
Batching helps GPUs do more work per call. Instead of sending assets one by one to an embedding model, the system groups them into batches for each GPU request. That can multiply GPU throughput compared with item-by-item processing.[4]
Distributed indexing with sharding and replication
After embeddings are generated, fast search across a large dataset takes more than one node. A single-node index becomes a bottleneck, and it’s also a failure risk. Sharding deals with the first issue. Replication deals with the second.
Sharding splits the embedding index across multiple nodes. Each shard can be indexed and queried in parallel, whether the split is based on content type, tenant, or another routing key. When a query comes in, the system fans it out to the relevant shards at the same time, then merges the results.
Replication creates copies of each shard on separate nodes. That lets the system spread query traffic across replicas and keep serving matches even if one node goes offline. Put those two together, and reads stay resilient and low-latency at enterprise scale.[5][8]
After distribution handles capacity, the next job is cutting inference and reindexing cost.
Optimization techniques that reduce cost without losing match quality
Speed matters, but so does cost. A few techniques help keep infrastructure spend in check without hurting match quality.
Embedding caching stores previously computed vectors using a stable content hash. The system can cache embeddings and reprocess only the assets affected by a new model version, usually in batches during off-peak hours, while the rest of the index stays live.
Adaptive frame sampling lowers video embedding cost without reducing recall. Instead of extracting one frame per second across an entire file, the system samples more heavily around scene changes and high-motion segments while skipping low-information sections.
Hybrid search uses metadata filters, such as brand tags, license periods, or content type, before ANN matching to cut cost. The payoff is faster, cheaper, and more precise search.[6][7][9][10]
These efficiencies keep large-scale matching fast enough for continuous monitoring and enforcement. They’re also what makes enterprise tools like Idem workable at high volume.
Applying Scalable Matching to Content Protection and Enforcement
The speed gains from the previous sections only matter if they lead to faster detection and takedown. That’s the whole point. This is where the technical base turns into a working protection system, and where matching moves from analysis into enforcement.
Detection across web, search, and shared media channels
At this level, manual monitoring just doesn’t work. There’s too much content moving across too many places. Scalable multimodal matching fills that gap by running continuous, parallel scans across websites, search engine result pages, social platforms, and streaming services at the same time.
A practical way to handle volume is to use multimodal agreement to split automatic enforcement from human review. When there’s a strong visual match plus audio or text support, the case can move straight to automated action. If there’s only a single-signal hit, it can go to review instead. That threshold logic helps keep false positives low without forcing someone to check every single hit.[11][12][13]
From there, each signal needs to move into the right enforcement path.
How InCyan products fit into a scaled protection workflow
InCyan sets up its product stack so each tool covers a clear part of the workflow.
Idem handles multimodal matching. It fingerprints images, video, and audio, and can confirm ownership even when only 10% of the original asset remains. Txtmatch focuses on text-heavy IP, including articles, research papers, and marketing copy, matching against a proprietary corpus with forensic precision. Indago works at the search layer, removing unauthorized links from search results in under 60 minutes so traffic gets cut off at the discovery point. TorrentWatch tracks the BitTorrent ecosystem and feeds detected hashes and tracker data into enforcement workflows. Tectus sits upstream of all of this, embedding invisible blind watermarks into visual and audiovisual files before distribution so ownership signals survive heavy transformation.
The next layer is ownership proof. That’s where blockchain-based timestamping comes in.
Matching, watermarking, and blockchain proof compared
The table below shows how each layer supports the same enforcement workflow.
| Multimodal Matching (Idem) | Invisible Watermarking (Tectus) | Blockchain Timestamping (ScoreDetect) | |
|---|---|---|---|
| Primary purpose | Detect and confirm similarity between discovered content and registered originals | Embed hidden ownership signals that survive redistribution and transformation | Record an immutable, time-stamped checksum proving an asset existed at a specific point in time |
| Scalability | High – parallel similarity scoring across large vector indices and multimodal databases | High – does not disrupt publishing workflows and is compatible with existing pipelines | High – stores only checksums, not content; API and WordPress plugin enable continuous, automated timestamping |
| Evidence value | Demonstrates likely copying through quantified similarity scores | Demonstrates deliberate ownership embedding that can survive cropping, re-encoding, and format changes | Provides a verifiable record of prior existence and authorship |
| Best-fit use cases | Anti-piracy detection and unauthorized reuse across web and streaming platforms | Leak tracing and pre-distribution protection | Establishing creation date in ownership disputes and strengthening takedown notices |
| InCyan product | Idem | Tectus | ScoreDetect |
Together, these layers give teams evidence at three key points: discovery, proof, and enforcement.
ScoreDetect, Blockchain Timestamping, and the Enterprise Stack

Where ScoreDetect fits in the workflow
ScoreDetect, a product of InCyan, handles blockchain timestamping. It records a SHA-256 hash, ownership metadata, and a timestamp on-chain, while the file itself stays off-chain. That setup keeps storage light and makes it easy for teams to automate timestamping through the WordPress plugin, API, or Zapier workflows.
The WordPress plugin can timestamp new and updated posts automatically. The API can trigger timestamping in custom workflows, such as at approval or publication.
ScoreDetect also generates downloadable verification certificates. These include the hash, blockchain transaction URL, registration date, and copyright owner name. That can help with legal filings or compliance sign-offs.
How timestamping strengthens enforcement at scale
Once matching spots a likely copy, timestamping adds the ownership record that backs up enforcement. When Idem flags a likely infringement, ScoreDetect provides the dated ownership record needed to show prior claim. For legal and compliance teams, that creates a clear version history for audits and internal review.
Put simply, timestamping works as the proof layer in a larger protection workflow.
Conclusion: Building a scalable and defensible content protection workflow
Scalable matching only goes so far if it can’t produce proof that holds up. The technical base – efficient embeddings, similarity scoring, parallel ingestion pipelines, and distributed indexing – lets systems like Idem find altered or partial content across large asset libraries at scale. But detection alone isn’t a complete protection plan.
Tectus adds invisible blind watermarking that places ownership signals directly into the media and survives common transformations. ScoreDetect anchors the timeline with a blockchain-backed record that shows when each asset was first claimed. Together, these layers – AI matching, invisible watermarking, and timestamped proof – give rights holders evidence at each step: discovery, attribution, and enforcement.
That means the workflow doesn’t just help teams find misuse. It also helps them document ownership and act on it when needed most.
FAQs
How is multimodal matching different from fingerprinting?
File-based fingerprinting depends on exact hashes. That works fine when a file stays untouched, but it falls apart the moment the content is cropped, compressed, or re-encoded.
AI fingerprinting works in a different way. Instead of looking for an exact file match, it builds mathematical signatures that reflect the content’s semantic core. In plain English, it tries to recognize the meaning and structure of the content, not just the file itself. That makes similarity-based detection possible even after edits.
Multimodal matching takes this a step further by looking at images, video, audio, and text at the same time. That extra layer of overlap acts like a safety net: even if one signal has been changed heavily, the system can still use the others to trace the source.
Why use vector search instead of exact search?
Vector search matters for modern content protection because exact search falls apart as soon as a file gets altered. A bit-for-bit match sounds nice in theory, but in practice, content gets cropped, compressed, resized, and re-encoded all the time.
Instead of looking for an exact copy, vector search uses embeddings to represent the asset’s semantic core. Think of it as matching the meaning or underlying pattern of the content, not just the raw file data.
That makes it possible to spot content even after common edits. And because ANN algorithms can scan massive databases fast, the system can work at the scale and speed needed for near real-time use. InCyan’s Idem uses this approach for enterprise-scale identification.
How does ScoreDetect support AI-based enforcement?
ScoreDetect adds a proof-of-ownership layer to AI-driven enforcement. Tools from InCyan, such as Idem and Txtmatch, can spot infringing content. ScoreDetect then records a cryptographic checksum of your assets on the blockchain.
That record creates a tamper-proof timestamp and a clear chain of custody without storing the actual files. For organizations, that means they can build enforcement evidence at scale and back it up with records that are easy to verify.