If you rely on exact file matches, you’ll miss edited copies. I’d sum up the article this way: the best way to spot stolen UGC is to check video, audio, images, and text together, then back those matches with watermarks and timestamp records.
Here’s the core point in plain English:
- I can’t depend on hashes alone because a crop, re-encode, overlay, pitch shift, or new caption can break a match.
- I get better results when I compare multiple signals at once instead of checking only one file type.
- One cited study found 0.94 precision but only 0.61 recall for visual perceptual hashing in freebooted social ads. That means about 39% of likely infringements still slipped through when edits changed the post.
- A multimodal setup helps because if one signal is weak, another can still support the match.
- For day-to-day use, I’d run a simple flow: register source assets, score new uploads, review or block based on thresholds, then support cases with watermark and timestamp evidence.
A simple way to think about it:
| Method | What it checks | Main problem |
|---|---|---|
| Exact hashing | Identical files | Any small edit breaks the match |
| Audio-only | Soundtrack | Misses visual or text reuse |
| Text-only | Captions and copy | Misses image and video reuse |
| Multimodal similarity | Visual, audio, and text together | More setup, but fewer missed copies |
So the article’s message is clear: modern piracy is mixed-format and edited on purpose, so detection has to work the same way. I’d use multimodal matching for discovery, invisible watermarking for ownership support, and blockchain timestamps for a dated record.
The Problem: Why Single-Modality Protection Fails Against Modern UGC
Modern infringement almost never shows up as a clean copy. People clip it, remix it, add captions, and repost it across different platforms. That’s where single-modality systems fall short: they often miss the altered version because they’re only looking at one signal at a time.
Common Evasion Tactics Across Image, Video, Audio, and Text
The pattern is pretty predictable. A tutorial video gets trimmed and re-encoded. A podcast clip gets sped up and placed under new footage. A product image gets cropped, framed, and recaptioned. A news segment turns into a meme with text slapped on top.
One study of freebooted social media ads found that visual perceptual hashing hit 0.94 precision but only 0.61 recall. In plain English, nearly 39% of infringements still got through when cropping or overlays disrupted the match.[1] Audio-only systems run into the same issue from the other side. They may detect a stolen soundtrack, but miss the post when the audio is replaced, pitch-shifted, or swapped for different music.[2]
Things get harder when one post pulls from several source assets. A single upload might mix video from one source, audio from another, and text from somewhere else. At that point, a one-file match stops being enough. Protection needs to compare signals across image, video, audio, and text, not just within one file type.
What Weak Detection Costs Brands, Creators, and Platforms
Missed infringement turns into direct business damage. For creators, that can mean lost monetization and less control over how their work reaches an audience. For brands, it opens the door to unauthorized use of campaign assets and reputation risk. For platforms, it adds to moderation queues and puts more pressure on trust-and-safety teams.[3][4]
Single-Modality vs. Multimodal Detection: A Direct Comparison
The table below shows how each method stacks up against the way modern UGC infringement actually works.
| Detection Method | Content Coverage | Resilience to Edits | False Positive Risk | False Negative Risk |
|---|---|---|---|---|
| Exact hashing (MD5/SHA-1) | Identical files only | None – any edit breaks the match | Very low | Very high |
| Audio-only fingerprinting | Audio tracks only | Moderate – fails on pitch shifts, speed changes, or music swaps | Low | High for visual/text reposts |
| Text-only matching | Text/captions only | Low – paraphrasing and subtitle changes defeat it | Medium | High for image/video reposts |
| Multimodal similarity | Image, video, audio, and text together | High – survives cropping, re-encoding, overlays, and combined reuse of multiple source assets | Medium | Low |
That’s why joint analysis matters. The system has to check visual, audio, and text signals against the same original asset instead of treating each one in isolation.
sbb-itb-738ac1e
The Solution: How Multimodal Similarity Detects Modified Content
Multimodal similarity looks at visual, audio, and text signals at the same time, then rolls them into a single match decision. That combined view helps the system hold up even when edits would throw off a one-signal check.
How Visual, Audio, and Text Signals Are Analyzed Together
Each signal type is checked on its own first, then the results are merged.
- Visual signals come from image data and individual video frames.
- Audio signals are pulled out as fingerprints that reflect traits like rhythm, melody, and tempo. They’re compact enough to survive compression and small edits.[5]
- Text signals come from titles, captions, subtitles, transcripts, descriptions, and even on-screen text picked up by OCR.
Each input is then turned into an embedding. That means a machine-readable representation of the content’s structure and meaning, not just the file itself. When those embeddings are close enough, the system flags a match.
That’s why a repost can still match the source even if it’s been cropped, re-encoded, or given a new caption. Enterprise systems like InCyan‘s Idem do this across images, video, and audio at once, combining the signal-level scores into one final decision. For UGC protection, that matters because the match can survive the kinds of reposting and remixing moves people use every day.
Why Multimodal Matching Works Even After Heavy Edits
The big strength of multimodal matching is redundancy. If one signal gets weakened or removed, another one can still carry the match.
Say a short-form video gets re-encoded, trimmed, and reposted with a different caption. The visual frames may lose detail from compression. But if the original soundtrack is still there, the audio fingerprint can still show that the content was reused.
InCyan’s Idem is built to survive major transformations, including mobile edits, memes, cropping, and compression, and it can still detect ownership after those changes. The same idea works with image-based content too. A meme made from a cropped photo with new text on top may still keep enough visual structure to register a match, especially if the caption also mirrors the source description.
That match score then becomes the basis for review and enforcement.
A Practical Content Protection Pipeline for Enterprises
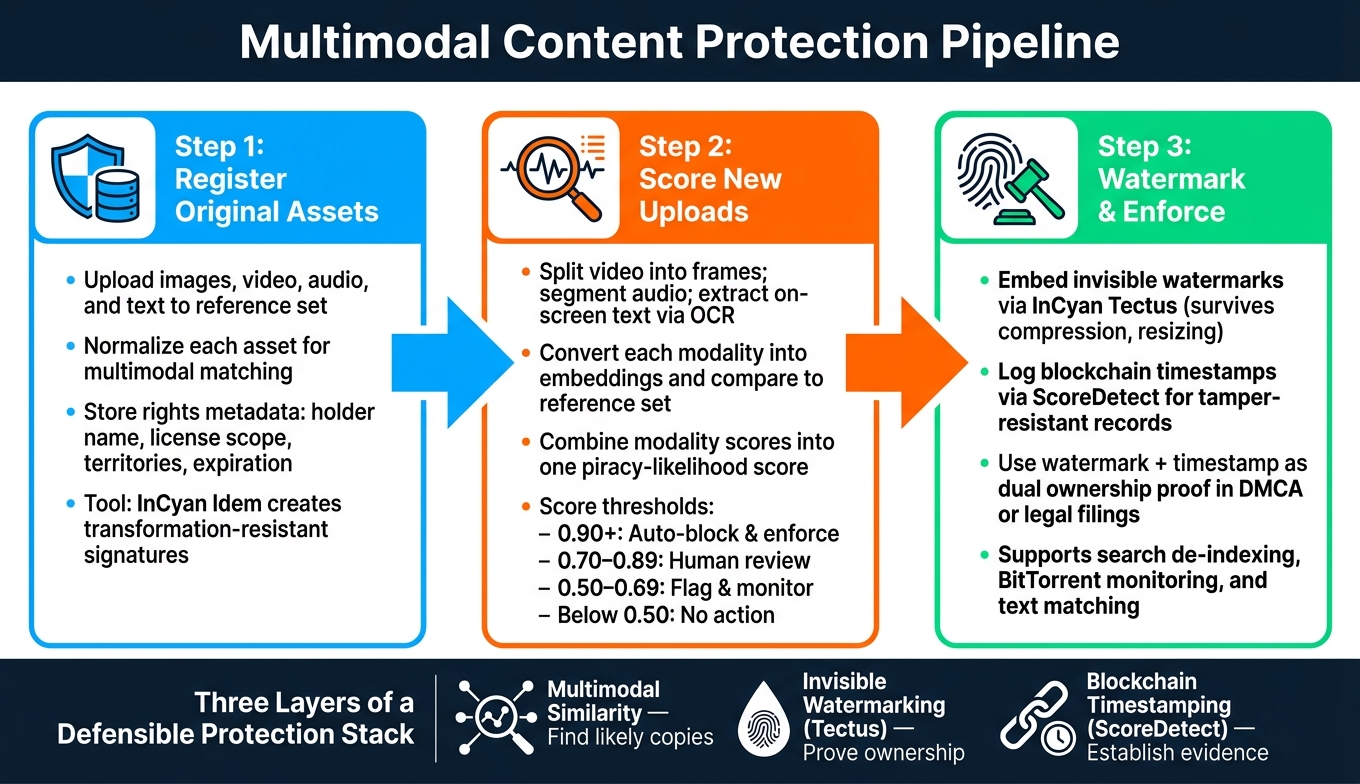
Multimodal Content Protection Pipeline: 3-Step Enterprise Workflow
Multimodal similarity works best with a simple flow: register assets, score uploads, then act on matches.
Step 1: Register and Prepare Original Assets for Matching
The process starts with a protected reference set. Register original images, video, audio, and text in that set, then normalize each asset for matching.
InCyan’s Idem handles the multimodal matching layer at this stage. It creates transformation-resistant signatures across image, video, audio, and text, so teams can detect ownership even after heavy editing. During registration, enterprises should also store rights and licensing metadata next to each asset’s technical identifiers. That includes the rights holder name, license scope, permitted territories, expiration dates, and intended distribution channels. This rights data helps teams decide whether a match is infringing or allowed under license.
InCyan’s Blueprint digital asset management platform can connect those metadata layers directly with Idem’s matching system. The result is a single source of truth that ties each asset to its enforceable rights and obligations.
That reference set becomes the baseline for every future scan.
Step 2: Score New Uploads or Discovered Copies Against the Reference Set
Once the baseline is in place, each new upload can be scored automatically against the reference set. Video gets split into frames and scenes. Audio gets segmented. Any text – on-screen, in captions, or in descriptions – is extracted and cleaned. Each modality is then converted into its own embedding and compared with the registered reference.
From there, teams combine those modality scores into one piracy-likelihood score. For example, a high visual match with only moderate text similarity may send content to a human review queue. But strong similarity across all three signals – visual, audio, and text – can justify immediate blocking or enforcement.
| Score Range | Recommended Action |
|---|---|
| 0.90 and above | Auto-block and trigger enforcement workflow |
| 0.70–0.89 | Route to human review with rights data attached |
| 0.50–0.69 | Flag for monitoring, especially for high-value assets |
| Below 0.50 | Generally no immediate action |
Thresholds should be calibrated against past outcomes to cut false positives and false negatives.
Scores above the enforcement threshold can then move into watermark and takedown workflows.
Step 3: Add Watermarking and Enforcement Workflows
Once a match is confirmed, proof of ownership gives the enforcement case more weight. Similarity scoring finds likely matches. Watermarking helps prove who owns the asset, even after recompression or other file changes.
InCyan’s Tectus embeds invisible ownership markers directly into image, video, and audio files without changing how the content looks or sounds to users. Those watermarks can survive resizing, compression, and minor edits. That gives teams a second, independent ownership signal to support similarity match results when a case is close.
ScoreDetect‘s blockchain timestamps round out the audit trail. When both a similarity match and a watermark detection point to infringement – across uploads, reposts, and remixes – legal teams can use the ScoreDetect timestamp record to show exactly when ownership was asserted. That creates an immutable, tamper-resistant record that can strengthen a DMCA notice, contract enforcement, or a court filing.
Teams can also use InCyan tools for search de-indexing, BitTorrent monitoring, and precise text matching to turn a detected match into enforcement.
Conclusion: Building a Defensible Multimodal Protection Stack
UGC piracy moves fast. Infringing copies get cropped, compressed, dubbed, memed, and reformatted before they spread. If you rely on a single signal, you’ll miss a lot of them.
That’s why the detection layer needs to read more than one signal at once. Multimodal similarity looks at visual, audio, and text signals together, so damage to one modality doesn’t hide the copy. That kind of resistance to edits makes it a practical way to deal with the changes real infringers use.
But detection by itself doesn’t build a case you can stand behind. A defensible protection stack needs three layers working together: multimodal similarity analysis to find likely copies, invisible watermarking through InCyan’s Tectus to support ownership checks, and blockchain-based timestamping through ScoreDetect to create a verifiable record of when an asset was first registered. Each layer handles a different problem: detection, provenance, and evidence.
The end result is a workflow teams can enforce in day-to-day work. Enterprise protection only works when registration, watermarking, and multimodal scoring run as one stack.
FAQs
How does multimodal similarity reduce missed infringements?
Multimodal similarity cuts down on missed infringements by looking at text, images, video, and audio together instead of depending on one-format tools. That matters because single-format systems can miss matches once a file has been changed, trimmed, compressed, re-encoded, or rewritten.
By mapping content into shared embeddings, it can spot the core meaning of an asset rather than just its surface form. So even if an image is cropped, a video is re-encoded, an audio file is compressed, or text is paraphrased, the system can still detect a copy. And if one format is hidden or weakened, another format can help confirm that the asset is the same.
What kinds of edits can multimodal matching still detect?
Multimodal matching can still spot original content even after major edits meant to hide where it came from.
It can identify images even when someone adds crops, filters, borders, mirroring, compression, or reposts them in low resolution. It can follow video through cuts, speed changes, aspect ratio changes, and re-encoding. It can detect audio despite pitch shifts, tempo changes, or background noise. And it can flag text that has been paraphrased, translated, or reformatted.
When should a match be auto-blocked or sent to review?
This depends on the match’s confidence score from content analysis. High-confidence matches are often auto-blocked, which helps teams act fast and handle large volumes without slowing down.
Medium-confidence matches should go to human review. That extra check helps confirm accuracy and cut down on false positives, especially when the case is less clear.

