Psychoacoustic watermarking embeds hidden data in audio by leveraging how human hearing works. Recent advancements have improved its ability to remain undetectable while resisting tampering, like compression or AI-driven edits. Here’s a quick overview of key developments:
- XAttnMark: Uses cross-attention to embed watermarks in time-frequency regions, ensuring they stay hidden and resilient.
- SilentCipher: Introduced psychoacoustic thresholding for imperceptible watermarks, boasting a 47.24 dB Signal-to-Distortion Ratio (SDR) and operating 1,302x faster than real time.
- AWARE: Excels in resisting temporal attacks, achieving a Bit Error Rate (BER) of just 1.61% after neural vocoder processing.
- Low-Bandwidth Solutions: SilentCipher’s half-band masking ensures watermark durability for low-bandwidth audio like telephony.
These models address modern challenges like deepfake technologies and piracy, offering tools for industries to protect audio content efficiently. Below, we dive into how these advancements are shaping enterprise audio protection.
Psychoacoustics – Masking Part 1
sbb-itb-738ac1e
Recent Advances in Psychoacoustic Watermarking
Recent developments in psychoacoustic watermarking have made significant strides in balancing two critical factors: keeping watermarks hidden from human listeners and ensuring they can endure various forms of tampering. By incorporating auditory masking principles directly into deep learning frameworks, researchers have moved beyond basic perceptual loss techniques. The result? Watermarks that remain undetectable to the ear while withstanding real-world challenges like compression and generative edits.
Between 2024 and 2026, several breakthroughs have tackled key issues in audio protection, focusing on improving speed, efficiency, and resistance to compression – particularly for enterprise applications.
XAttnMark: Cross-Attention with Psychoacoustic Masking Loss

XAttnMark is a standout innovation that uses a psychoacoustic-aligned temporal-frequency masking loss. This approach is specifically designed to resist generative edits. The model employs cross-attention mechanisms to pinpoint time-frequency regions within audio that can safely embed watermark data. By aligning the masking loss with human auditory perception, XAttnMark ensures that watermark alterations remain undetectable, even when the audio is subjected to neural reconstruction attacks.
SilentCipher: Deep Learning with Psychoacoustic Thresholding
In September 2024, SilentCipher introduced a groundbreaking method that integrates psychoacoustic model-based thresholding to create imperceptible watermarks for high-quality 44.1 kHz audio [5]. The research team behind SilentCipher highlighted their achievement:
"Our work is the first deep learning-based model to integrate psychoacoustic model based thresholding to achieve imperceptible watermarks." – Mayank Kumar Singh et al., SilentCipher Authors [5]
SilentCipher delivers an impressive Signal-to-Distortion Ratio (SDR) of 47.24 dB, significantly outperforming earlier methods like AudioWmark and RobustDNN [5]. By setting the watermark phase to π relative to the original carrier and limiting the magnitude of each frequency bin to the original signal’s level, SilentCipher ensures that low-energy watermark signals blend seamlessly into high-energy audio.
The model also stands out for its speed. SilentCipher-16k operates 1,302 times faster than real time, which is 6 to 9 times faster than earlier models like RobustDNN and WavMark. And it achieves this efficiency with just 372 hours of training data – far less than the 5,000 hours required by traditional approaches [5]. Additionally, it employs pseudo-differentiable compression layers that simulate compression during the forward pass while bypassing it during the backward pass. This clever design allows SilentCipher to withstand compression formats like MP3, OGG, and AAC [5].
Psychoacoustic Models for Low-Bandwidth Audio
Low-bandwidth environments, such as 8 kHz telephony audio, pose unique challenges. Deep learning models often introduce audible artifacts when working with band-limited signals. SilentCipher addresses this issue using half-band masking, which restricts watermarks to frequency bins below 4 kHz for 16 kHz signals. This ensures watermark resilience even when the audio is downsampled to as low as 6.4 kHz, all while keeping the watermark imperceptible [5].
Moreover, SilentCipher allows users to set a controlled lower bound for the SDR during inference without requiring additional training. This flexibility helps balance imperceptibility and robustness, making the model adaptable for various deployment scenarios. These advancements are particularly valuable for ensuring watermark durability in constrained audio settings.
These cutting-edge developments set the stage for a deeper comparison of these models and their practical applications.
Comparison of Psychoacoustic Models
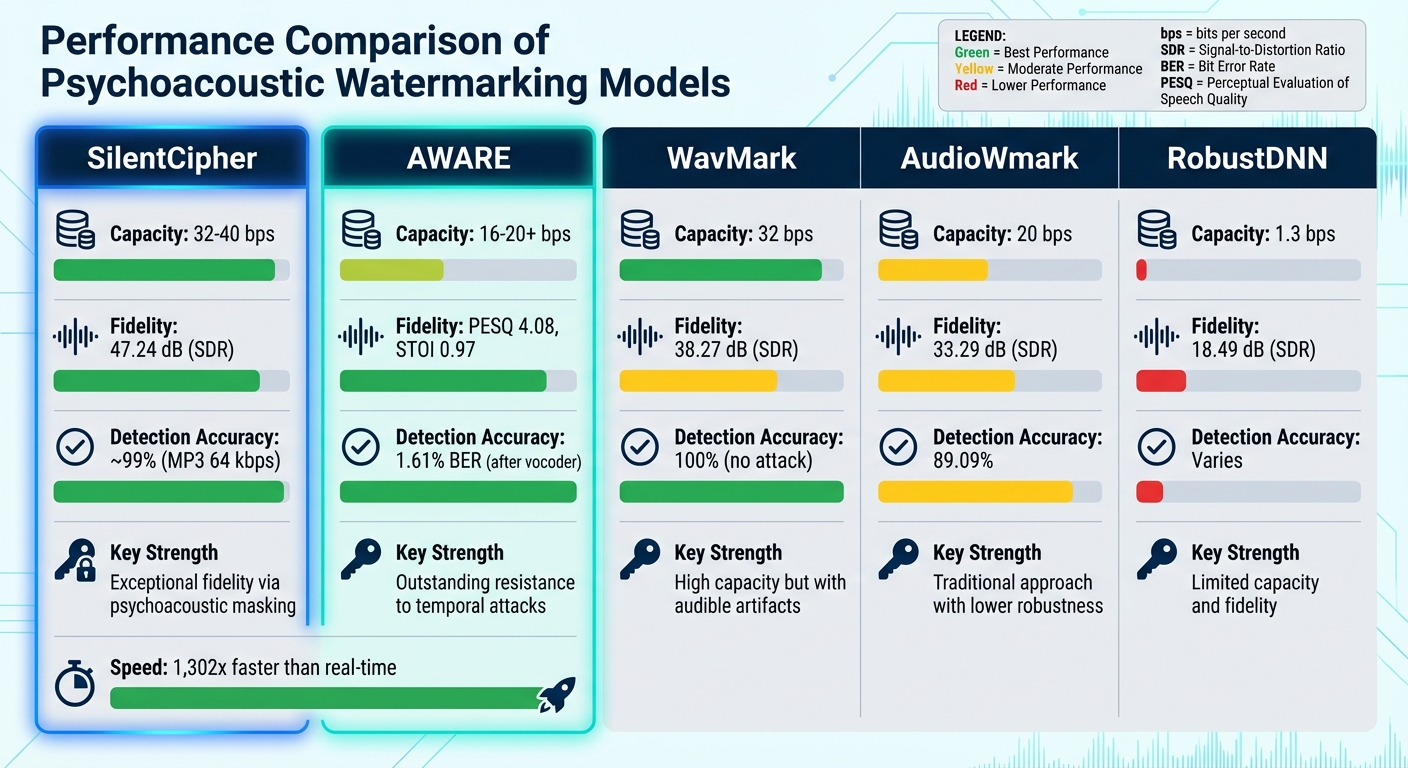
Psychoacoustic Watermarking Models Performance Comparison: Capacity, Fidelity & Detection Accuracy
When evaluating watermark performance, three factors take center stage: imperceptibility, durability, and capacity. The latest models – SilentCipher, AWARE, and Timbru – approach these priorities differently, offering unique advantages depending on the application.
SilentCipher prioritizes audio fidelity, boasting an impressive SDR of 47.24 dB. This outperforms WavMark’s 38.27 dB and AudioWmark’s 33.29 dB [5]. It supports a capacity of 32–40 bits per second, depending on the sample rate, and operates at a speed 1,302 times faster than real-time. Additionally, it maintains about 99% detection accuracy even under MP3 64 kbps compression [5].
AWARE shines in its resistance to temporal attacks and desynchronization. It achieves near-imperceptible watermarking, with a PESQ score of 4.08 and a STOI score of 0.97 [1]. After neural vocoder resynthesis, AWARE demonstrates a low Bit Error Rate (BER) of just 1.61%, while WavMark struggles with a 50% BER under the same conditions [1]. Its capacity ranges from 16 bits per second to over 20 bits per second [1].
Timbru is tailored for professional-grade stereo audio at 44.1 kHz. It leverages post-hoc gradient optimization within the latent space of a pretrained audio VAE, achieving a cutting-edge balance between robustness and imperceptibility. This approach eliminates the need for a trained embedder-detector model, making it especially useful for high-value music assets where fidelity is critical [3][6].
Detection and Attribution Trade-Offs
The performance metrics of these models directly impact their suitability for detection and attribution in practical scenarios. For instance, high-capacity models like SilentCipher and WavMark offer strong attribution reliability (32+ bits) while maintaining near-perfect detection accuracy under standard conditions [5].
| Model | Capacity (bps) | Fidelity Metric | Detection Accuracy | Key Strength |
|---|---|---|---|---|
| SilentCipher | 32–40 | 47.24 dB (SDR) | ~99% (MP3 64 kbps) | Exceptional fidelity via psychoacoustic masking [5] |
| AWARE | 16–20+ | PESQ 4.08 | 1.61% BER (after vocoder) | Outstanding resistance to temporal attacks [1] |
| WavMark | 32 | 38.27 dB | 100% (no attack) | High capacity but with audible artifacts [5] |
| AudioWmark | 20 | 33.29 dB | 89.09% | Traditional approach with lower robustness [5] |
| RobustDNN | 1.3 | 18.49 dB | Varies | Limited capacity and fidelity [5] |
Applications in Enterprise Audio Protection
Psychoacoustic watermarking models have evolved to tackle the challenges posed by deepfake technologies and unauthorized use of audio, particularly in heavily edited social media content. These advancements are designed to meet the unique needs of enterprises.
Professional-grade imperceptibility is a must for industries like broadcast networks, music labels, and podcast producers. Tools like SilentCipher use psychoacoustic thresholding to embed watermarks that are inaudible even in high-fidelity 44.1 kHz audio. This ensures audio quality isn’t compromised, as imperceptibility depends on psychoacoustic principles rather than just achieving a high Signal-to-Distortion Ratio (SDR) [5].
Fragment-level detection provides a solution for piracy techniques such as splicing short clips or creating montages. AWARE’s Bitwise Readout Head (BRH) architecture excels at identifying watermarks even in non-contiguous audio segments, making it difficult for unauthorized users to avoid detection [1].
Speed is key to automation. SilentCipher processes audio files at a rate 1,302 times faster than real-time [5]. This speed transforms watermark detection from a manual process into an automated one, enabling enterprises to monitor vast libraries of streaming and social media content daily.
Robust AI resistance ensures watermarks can withstand manipulation by neural vocoders, which are often used in deepfake and voice cloning technologies. For instance, AWARE maintains a Bit Error Rate (BER) of only 1.61% after audio passes through such tools, compared to older models like AudioSeal, which exhibit a much higher BER of 39.01% under similar conditions [1]. This resilience ensures watermarks survive even through AI-driven reconstruction.
Integration with ScoreDetect‘s Advanced Tools
ScoreDetect leverages these innovations to deliver comprehensive digital audio protection.
During the Prevent phase, ScoreDetect uses advanced invisible watermarking techniques that embed watermarks capable of withstanding common distribution formats while maintaining the high-fidelity standards required for professional audio and broadcast content.
In the Discover phase, the platform combines ultra-fast detection with intelligent web scraping, achieving a 95% success rate in bypassing anti-bot systems. With models operating at over 1,300 times faster than real-time, enterprises can rapidly scan the digital landscape for infringing content.
The Analyse phase provides detailed verification of unauthorized usage. Modern psychoacoustic watermarks embed payloads of 16 to 40 bits per audio snippet [5], offering precise details about when, where, and by whom content was misused. This forensic accuracy allows enterprises to gather the evidence needed for legal enforcement, even when audio has been compressed, edited, or partially reconstructed.
Finally, the Take Down phase automates enforcement with an impressive success rate of over 96%. By combining fragment-level detection with automated takedown notices and frameworks that prevent unauthorized watermark removal [4], infringing content is swiftly removed from search engines and hosting platforms.
For media companies, podcast networks, and content creators, ScoreDetect’s platform offers scalable protection. By integrating psychoacoustic watermarking with blockchain timestamping, it provides a dual-layer defense: invisible watermarks that endure content manipulation and blockchain checksums that offer tamper-proof ownership records. This approach not only addresses technical detection challenges but also meets legal requirements for proving ownership.
Conclusion and Key Takeaways
Recent developments in psychoacoustic watermarking are transforming how businesses protect their audio content. For instance, models like AWARE achieve a PESQ score of 4.08 while keeping the Bit Error Rate impressively low at just 1.61% after neural vocoder resynthesis. This level of performance marks a major leap compared to earlier methods [1]. Such resilience is becoming increasingly critical as voice cloning and deepfake technologies create new challenges for media companies, podcast networks, and content creators.
One standout innovation is the use of Bitwise Readout Heads (BRH) for time-order-agnostic detection. This approach resolves long-standing issues with temporal desynchronization, ensuring watermarks remain detectable even after edits like cuts and splices – common in professional audio workflows. As lead researcher Kosta Pavlović puts it:
"Watermark detection differs fundamentally from object/keyword detection… It is a weak, distributed pattern, encoding bits that must be sequence-consistent under time-warping and cutting" [1].
Further advancements in frameworks like WAKE enhance watermark resilience by introducing key-controlled systems. These systems prevent unauthorized detection and allow multiple watermarks to coexist without interference [4]. Additionally, multiplexing strategies combine different watermarking techniques, providing robust defenses against both traditional signal processing attacks and AI-driven manipulations [2].
Together, these innovations form a powerful toolkit for audio protection. Tools like ScoreDetect integrate these advancements to enable fast detection, automated forensic analysis, and blockchain-based timestamping, achieving a 96% success rate for takedown actions.
Watermarking has evolved from a defensive measure to a proactive security solution. By adopting these cutting-edge techniques, enterprises can better protect their audio assets from both current and future threats driven by AI technologies.
FAQs
How do psychoacoustic watermarks stay inaudible?
Psychoacoustic watermarks work by staying inaudible, thanks to a multi-band masking model that leverages the ear’s natural limitations in detecting certain sounds. These watermarks introduce slight, undetectable changes that are obscured by louder or more dominant audio signals, allowing them to integrate seamlessly into the sound without drawing attention.
What edits or attacks can these watermarks withstand?
Watermarks like these are built to withstand a wide range of modifications and distortions. They can endure challenges such as desynchronization, temporal cuts, filtering, noise, compression, resampling, cropping, pitch shifting, and frequency band filtering. Even under regeneration attacks or other forms of alteration, they are typically able to maintain accurate decoding with minimal errors, offering strong protection against misuse.
How can ScoreDetect use these models at enterprise scale?
ScoreDetect uses cutting-edge psychoacoustic watermarking models to embed watermarks into audio content that are undetectable to the human ear. These watermarks are designed to withstand challenges like compression, filtering, and even neural attacks, all while preserving the original audio’s quality.
For large-scale operations, ScoreDetect automates the entire process – embedding, detecting, and verifying watermarks across massive volumes of digital assets. This makes it a powerful tool for copyright protection, content verification, and streamlining rights management workflows, all without sacrificing performance.